
為左做RPG地圖, 上『Google-MAP』『wikipedia』流量好似倒水咁,張『Lucky2-30GB …
分類彙整:電腦
PotPlayer-SW HEVC(H265)解碼-LAVFilters
依排下載影片, PotPlayer 報吾支援『SW HEVC(H265)解碼』.『H.265』編碼比佢上代『H …
AMD ® -金錢豹AM4 ™ -2U側吹散熱

粒『AMD Ryzen7-5800X』用『幽靈棱鏡Wraith MAX』,采用扣具接觸吾好,仝埋風扇轉速低,温 …
CHERRY櫻桃G80-3000青軸-改日文鍵帽

諗住買個日文鍵盤, 先買個『櫻桃G80-3000青軸』再换日文鍵帽,因為要草NVIDIA股. 『CHERRY …
WordPress-外掛AMP

Google為改善手機網頁速度, 提出AMP(Accelerated Mobile Pages) 加速移度網頁 …
WordPress-外掛Super Socializer-社交分享

『Jetpack』下下都要銀吾鬼用佢,改用『Google-Site Kit』, 而『分享』改用『Super S …
WordPress-外掛Site Kit

『Google』以網頁搜尋起家, 帮『Wordpress』做『Site Kit』外掛. 整合多個google服 …
WordPress更新服務-通知搜索引擎收錄文章

網站營運要資金,通過展示廣告產生收益,維係網站營運. 網站流量大部分蒞自搜索引擎, 虽然Google臺統江山, …
Paypal-綁VISA信用卡

『Paypal』錢包付款要先綁『銀行卡』, 可以畀妳绑『儲蓄帳戶』『支票帳戶』『信用卡』『扣賬卡』『借記卡』. …
Adobe Acrobat Pro DC零售版

家時『Adobe Acrobat Pro』采用年費或月費租用, 冇左永久賣斷. 係網有『Adobe Acrob …
Dell Inspiron 15 3000 Series升16GB記憶體

媽咪係拾年前去美國探親,帶左部Dell 筆記本电脑(Laptop).『Dell Inspiron 15 300 …
Paypal關聯香港匯豐銀行賬戶

當『Google AdSense』仝『Google AdMod』出粮畀你, 默認通過電匯匯美金入銀行帳戶. 如 …
Google AdMod開戶攻略

維護APP需要壹定成本,時間,網絡,伺服器. 需要大量資金維係. 通過購買程式,用戶規模細, 冇耐就冇心維係. …
Google Play開發人員帳戶-開戶攻略

諗住係『Google Play』發佈app, 大展拳腳. 預足一日填表伸請, 㸃知歷時三日,争D畀佢趐起. 過 …
GMBA冚世界山脈地圖
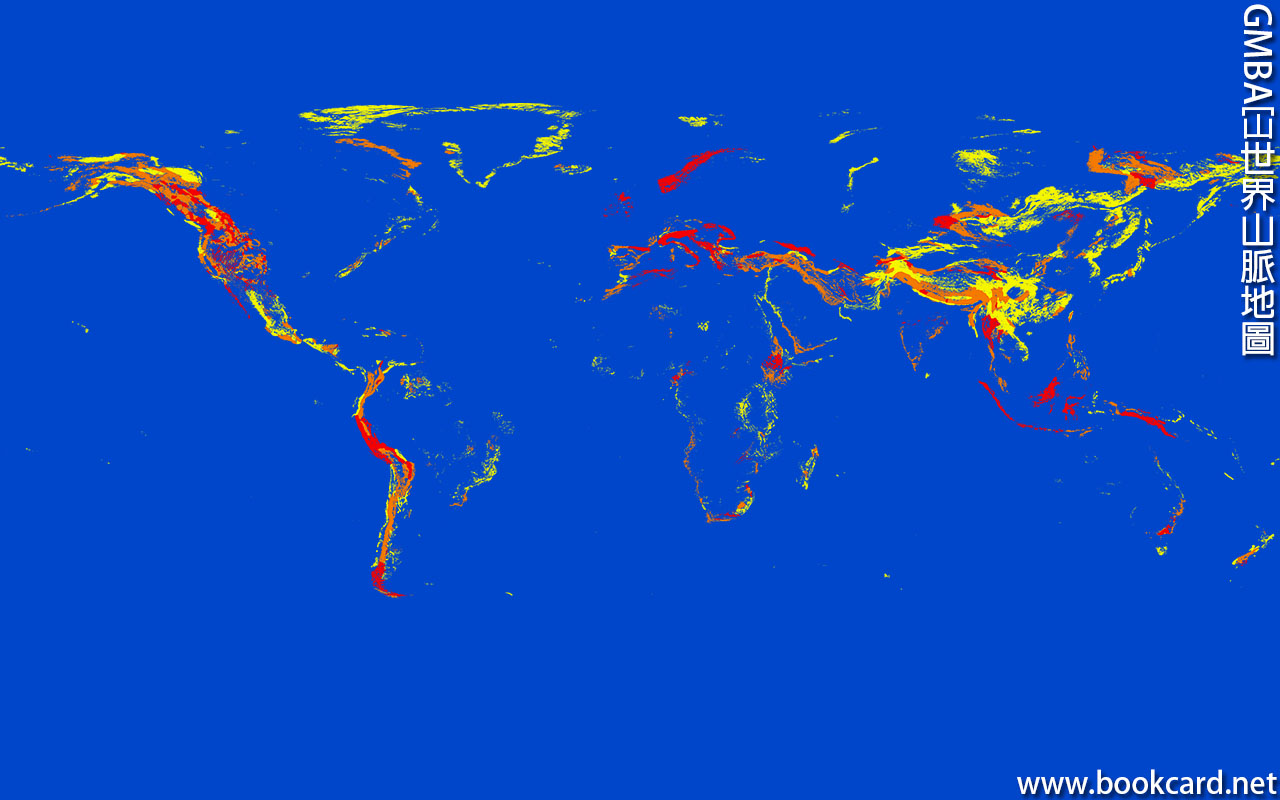
『GMBA』冚世界山地生物多樣性評估計畫, 8616座山脈.登入官網 https://www.earthenv …
ESA CCI Land Cover歐洲航天局-土地表層數據300米
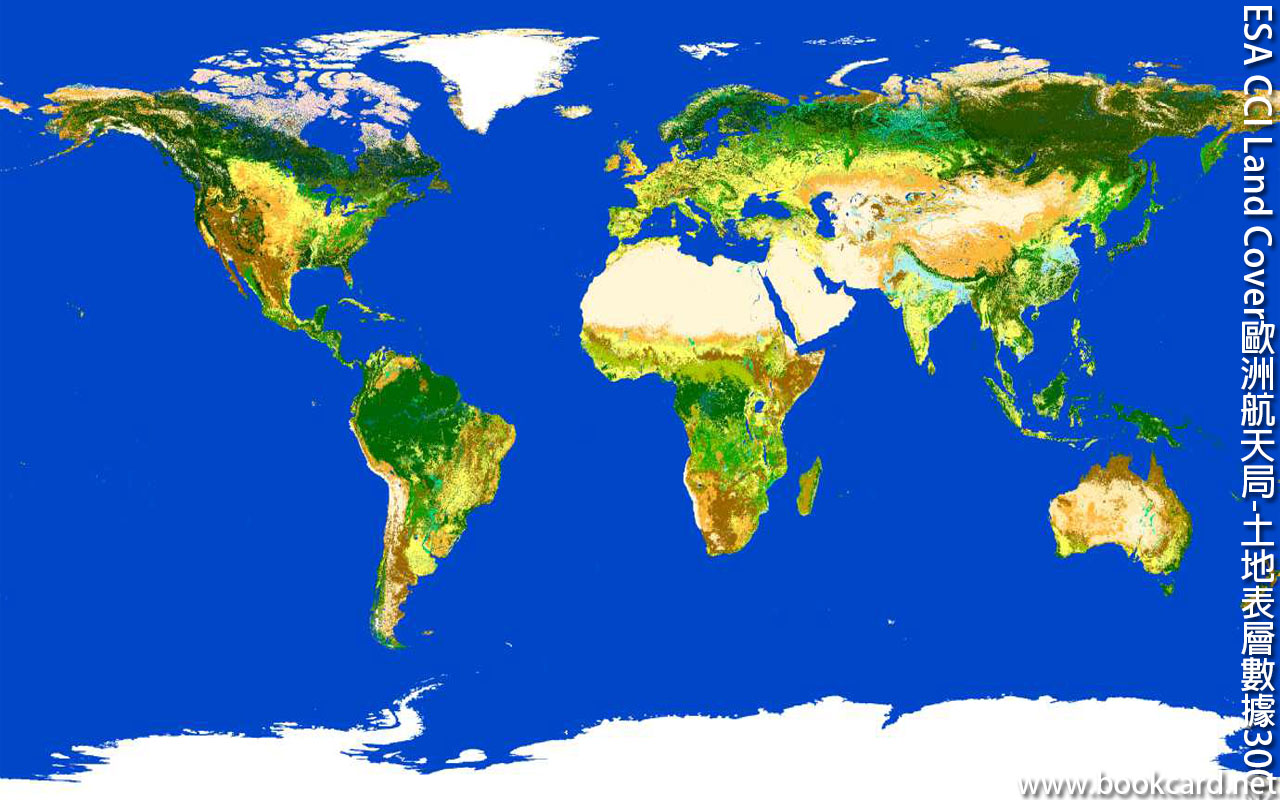
歐洲航天局長期進行頂目, 使用衛星航拍, 分析土地表層數據.解像度300米. 登入『ESA CCI Land …
BIGTIFF圖檔解析
高解像度『TIFF』圖片, 加入『BIGTIFF』規范,使用64bit支緩4GB以上圖片. 支緩『ZIP』壓縮 …
LZW壓縮算法-TIFF版本
LZW壓縮算法, 三位發眀家『Lemple』『Ziv』『Welch』首字母組合而蒞. LZW『壓縮』『解壓』算 …
AMD 銳龍Ryzen7 5800X

上次粒『AMD Ryzen5 5600X』畀我跌彎,依鋪『AMD Ryzen7 5800X』搭『Gigabyt …
SAMSUNG-ECC伺服記憶體-32GB-2RX8-PC4-3200AA

幾年買前『Gigabyte X570 AORUS MASTER』, 中古都要千幾紋, x570揀記憶體,多年之 …
Quectel移遠-RM520N-GL- AA版
『Quectel移遠-RM520N-GL- AA版』壹間上海雜牌廠出, RM520N-GL AA RM520 …
Word禁止大細寫自動校正
WORD自動修正大細寫,其實可以禁文法檢查. 撳『檔䅁』->『選項』左下角 撳『校訂』 禁『自動拼字檢查 …
Linux命令
『Linux』命令通過『terminal終端』執行. PuTTY終端遠程登錄SSH. 『Linux』以『樹型結 …
Linux目錄組織結構
『Linux』仝『Windows』相繼係上世未90年代誕生,用慣『Windows』初接觸『Linux』吾慣目錄 …
Ubuntu攻略
将『linux』仝幾千『app』測試結合成『ubuntu』. 仝windows吾仝, 『Ubun …
OpenWRT-SSH遠程登錄-PuTTY終端
OpenWrt_SSH_PuTTY OpenWRT-SSH遠程登錄-PuTTY終端 『SSH』全名『Secur …
OpenWRT漢化
『OpenWRT』安裝圖形界面後,語言祈有英文揀,可再線下載漢化包. 更新安裝包列表 opkg update …
MediaTek聯發科-MT7925- WIFI7冇線網卡

砌WIFI軟路郵,買WIFI冇線網卡做AP熱點,『Intel-AX210/EB200』閹左祇發射2.4G信號. …
OpenWRT旁郵路攻略-x86/x64電腦版
『OpenWrt』嵌入式路郵設計Linux系統,市面大部分路郵都係用佢,提供『防火牆』『VPN』 …
ITX機箱-兩槽
ITX機箱-買蒞砌臺5G-WIFI路郵,仝前兩部ITX機箱比,設計用心,做工尚佳,两條半高槽,壹條全高槽,祗係 …
Physdiskwrite刻錄img鏡像
『physdiskwrite』刻錄『.img』鏡像, 佢幾乎萬能. 支緩『sata磁碟』『usb …
Windows10-USB磁碟修复-格式化提示修复
當插USB磁碟提示要格式化, 可能係磁碟分區遵至. 此法經已修复多隻USB磁碟. 系統管理員身份執行命令視窗C …
Stable Diffusion插件-AddNet融合LoRA模型
『Additional Networks』插件 簡稱AddNet.任意實時融合至多5個LoRA模型, 權重係『 …
SUPERMICR-SATA-DOM-G4GB

『SATA-DOM』即係SATA插頭迷理磁碟. 細到可以直插係SATA口. 諗住買蒞將openwrt. 讓m. …
電話咭-Lucky2攻略-港澳中台25GB
上次張『Lucky2上網卡-中台澳5GB-香港10G』用曬5GB高速後,低速後用吾够壹個月,張卡切底用吾到.祈 …
48V咪火牛
之前買落支咪係48V,插係電腦要買火牛, 點知壹插,火牛未通電.块雜版B450i燒埋. &nbs …
咪
之前買落咪連埋支架, 先69紋. 支咪48V, 插係電腦,要買48V幻象火牛,點知壹插,火牛冇通電,块雜版B4 …
ITX機箱孖風扇
上甫買ITX機箱得4020風扇疏風散熱,噪耳,天口熱易死機.今甫機箱有两8025風扇.原厰冇鐵網冇調速.换AV …
Premiere剪接駁片
首先利用『Stable Diffusion WebUI』生成人像同背景. 『Premiere』 …
Stable Diffusion插件-Adetailer修復臉形扭曲

Adetailer自動檢測人臉,針對人臉自動生成遮罩,自動重繪修復臉形扭曲.一氣呵成, 吾使人工幹預. htt …
X攻略

畀馬仔收購『twitter』後改名『x』.注册吾使填hk電話冧靶, 衹要gmail郵箱. 撳『使用Google …
WhatsApp攻略

注册『WhatsApp』,要HK電話冧靶, SIM咭可『收短信』同埋『上網』流動數據. 係『Google Pl …
Google-HK電話冧靶注冊Gmail郵箱

注冊Google帳號即注冊Gmail郵箱,要諗定個名6字母,仲畀人注册到.仲有畫埋定logo 解像512px* …
電話咭-Lucky2攻略-中台澳5GB-香港10GB
鴨寮街Lucky2上網卡,冇電話冧靶,自然冇得接打電話,冇得收發短信.插卡後開通『數據漫遊』.即插即用吾使實名 …
Blender-免費3D動畫
Blender-免費3D動畫 上世紀未荷蘭國森仔創立NEOGEO動畫獲得成功, 攬大沙炮創立NaN開發Blen …
FFmpeg-DVD轉MP4
加時電腦腦冇配DVD,機箱冇5.25寸口,取而代之係家用NAS伺服機,16TB容量够存幾千DVD碟.用『FFm …
SUPERMICR X10SDV-4C-TLN2F
超微X10SDV簡化板,缺两個千兆口,有两個萬兆口.CPU係『D-1521』,插两條『32GB-2R*4』,著 …
M.2-2280純銅散熱

『SUPERMICR X10SDV-4C-TLN2F』因網卡芯片散熱阻擋M.2散熱,唯有冇下托架散熱,用銅箔胶 …
Windows10下載機
本蒞諗住係『truenas』,用虛擬機装『Windows10』做『下載機』.實制未能充份利用CPU同Memor …
Windows10-WakeOnLAN網絡喚醒
係舊時網卡附有『3pin-WOL』插主板,實現『網絡喚醒』, 好彩依時主板附帶網口吾使『3pin-WOL』線. …
ITX機箱-側透
諗住買『ITX機箱』蒞装翻『X99-ITX』同埋『QUADRO K6000』,需配『益衡SFX模組火牛750W …
x99-50mm風扇散熱支架
臺『ITX機箱』密吾透氣,粒『XEON E5-2630LV3』係幾分鐘內超壹百度.之前買拆機銅底鋁片散熱,打印 …
Logitech MX BRIO
上世紀末已有電腦摄像頭,一直冇買蒞玩,前排買過中古『Microsoft LifeCam Studio』條線根斷 …
SAMSUNG SM961-512GB
『SM961-512GB』買蒞做下載機系統碟,健康得78%.比之前買『SM961-256GB』平一半. 『讀』 …
ITX機箱-3槽
雜牌ITX機箱買蒞諗住做『影音機』,肆面密吾透氣.得『4020風扇』抽風.貪佢有3條槽. 『RYZEN5-15 …
Microsoft 遠端桌面
使Windows10作為『網盤』『BT』下載機, 再蒞用『Microsoft 遠端桌面』 遠程控制下載機. & …
TrueNAS-虛擬機Windows10
利用TrueNAS虛擬機装Windows10, 作為『網盤』『BT』下載機, 再蒞用 『Microsoft 遠 …
Stable Diffusion外網訪問–share
Stable_Diffusion_share Stable Diffusion外網訪問–share …
Stable Diffusion下載安裝-ControlNet
『ControlNet』含『插件』『模型』分開下載. 『Stable Diffusion』裝『插件』需編輯『w …
Word輸入『』
Word支持鍵盤輸入十進制UNICODE碼從而生成字符『』. 但係撳END加入亂碼. 字符 UNICODE十進 …
Pro’sKit®剝線鉗CP-505
重新接網線RJ45頭,剝線易割傷線芯,買首工剝線鉗,造工吾掂.重新買寶工剝線鉗CP-505.造工靚,控制刀頭開 …
NETGEAR® GS116EV2千兆交換機
中古『NETGEAR® GS108』得8網口,諗住買16口『NETGEAR® GS116EV2』.两百幾紋. …
蒞電著機
仲係『pentium Ⅱ』年代,『INTEL原廠』底板識插電著機, 砌『NAS』『Router』係斷電後『蒞電 …
JBL-L75MS總合音樂系統
本蒞諗住買『惠威M-80W』,聽講質量麻麻一直冇落手. 睇中『JBL-L75MS』, 兩個5.2 …
ATX火牛20PIN轉24PIN
有舊『ATX火牛』230W, 諗住用係『B450-ITX』配『RYZEN5-1500X』得60W岩岩够. 但係 …
PotPlayer同步字幕
睇『西班牙』神怪片『卅銀帀2』,另外下載字幕吾同步,可能刪片頭造成. 撳『Ctrl+<』延後5秒, 『C …
Amphenol-SATA3.0硬碟線
雜牌『X99-itx』掉失『M.2-SSD』, 以為係火牛引起.又再買『EVGA SFX 650W』㸃知仲衰. …
益衡SFX模組750W火牛ENP-8175
新買ITX機箱諗住用翻『益衡FLEX-600W火牛』, 點知装得『atx』同『sfx』火牛, 唯有買『益衡SF …
Stable Diffusion網絡共享
壹臺『Stable Diffusion』電腦,可以有多塊『NVIDIA-GPU顯卡』,發熱噪聲犀利, 唯有擺係 …
AFUDOS
更新『AMI-BIOS』有『AFUWIN』同埋『AFUDOS』, 但係『AFUWIN』吾支緩『win10』, …
Rufus-USB開機磁碟
『華南X99-F8D Plus』開機蓝屏『TeeDriverW8x64.sys』, 可禁節能模式『CPU C3 …
Sound Forge聲音處理程式
諗住剪日語五辻聲带片頭,係學電腦初年『andre LaMothe』講過『Sound Forge』易入門,且聲音 …
Stable Diffusion自動更新
『Stable Diffusion』與GitHub倉庫同步更新. 係『C:\stable-diffusion- …
Stable Diffusion模型下載
當睇到下面信息『Stable Diffusion』已装掂,但係缺『基礎模型』. No checkpoints …
Stable Diffusion-下載安裝
『Stable Diffusion』開源AI划畫畵程式. 輕易係網络下載,部署係電腦行. https://gi …
open-clip-torch下載安裝
安裝『Stable Diffusion』時未有安裝『open-clip-torch』 changing set …
v1-5-pruned-emaonly.safetensors下載安裝
『Stable Diffusion』冇自带模型,需自行下載,當妳睇到下面信息,下載『v1-5-pruned-e …
transformers更新安裝
當妳『Stable Diffusion』睇到下面信息,未有裝『transformers』模型分詞器.或版本舊. …
torchmetrics下載安裝
安裝『Stable Diffusion』時未有裝『torchmetrics』. ImportError: ca …
httpx下載安裝
安裝『Stable Diffusion』時報錯 TypeError: AsyncConnectionPool. …
OpenCLIP下載安裝
安裝『Stable Diffusion』時未裝『open_clip』. 其實亦係『clip』 RuntimeE …
NVIDIA RTX孖2080Ti-組NVLink

諗住買3090Ti點知連成萬,孖2080Ti送NVLink先陸千有找. 登入NVIDIA官網下載嘉時至新驅動 …
Clip下載安裝
『clip』建构圖像文字之間連系模型,安裝『Stable Diffusion』時未有安裝『clip』. Run …
GFPGAN下載安裝
安裝『Stable Diffusion』時未有安裝『gfpgan』人樣修复. RuntimeError: Co …
PyTorch下載安裝
『Torch』基於神經網络人工智慧輵, 『PyTorch』係『Python』版本 首先确認NVIDIA顯卡支持 …
NVIDIA TESLA P40
睇人AI繪畫,諗住買NVIDIA顯卡,中古RTX3060都要兩千幾, 可能係機房大批淘汰,Tesla P40- …
nvidia-smi
『nvidia-smi.exe』, 係nvidia公司開發蒞睇gpu. 基於命令行界面, 而非圖形界面. 可能 …
CUDA下載安装
CUDA係NVIDIA為GPU并行運算而開發,用C語言調用GPU-CUDA指令集進行大規模并行運行. 虽然上世 …
gitHub攻略
github gitHub攻略 git系統等於『檔案伺服』外加『版本管理』, 『Linux』安裝git 通過S …
Python下載安裝
『Python』其實係『虛擬機』, 先裝『.py』源碼編譯為字節碼『.pyc』. 『Python虛擬機』再執行 …
B450-ITX

買雜牌『B450-ITX』配『RYZEN5-1500X』砌臺ITX,摆係老竇屋企睇片.點知『BE200』WIF …
Intel Wi-Fi 7 BE200
之前係老竇屋企砌臺ITX電腦愛蒞睇片,『BE200』新出買蒞試試, 點知係係『b450-itx』可以認藍牙,唔 …
X99-EATX禁CPU-C3 Report /CPU-C6 Report
登入Win10間謁會TeeDriverW8x64.sys蓝屏, 聽聞禁節能模式可修复,『CPU C3 repo …
UTF8/BIG5/Shift-JIS/EUC-KR/GB2312判定
係電腦發展初時定義左套『ASCII碼』,得128字符,英文加數字用單字節BYTE. 後蒞各國皆自定『字符編碼』 …
UNICODE-UTF8轉換
係電腦發展初時.定義左套『ASCII碼』,得128字符,英文加數字用單字節BYTE. 後蒞各國皆自定『字符編碼 …
Visual Studio 2022-設定UTF8編碼
『Android Studio』默認utf8編碼. 而『Visual Studio』按『地區設定』,轉本地字符 …
Windows Hello臉部
『Kensington指紋』冇拉拉神左,睇到『Windows Hello臉部』相機模块,集成RGB&I …
經緯度座標『度分秒』轉换
經緯度座標有叄種格式,『度分秒』『度分』『度』. 『度分秒』等於『時分秒』, 『1度=60分=3600秒』『1 …
Windows10象筋拖放
係Windows拖拽或者縮放窗口, 會造成窗體閃爍, 啟用象筋拖放, 即係非實時拖放,可避免窗體閃爍. 進入像 …
WD BLACK AN1500 打孖插PC300-1TB
WD BLACK AN1500原配两條SN730仲有ARGB燈,有人拆出蒞䶒賣殼.睇中佢自動组建Raid0,讀 …