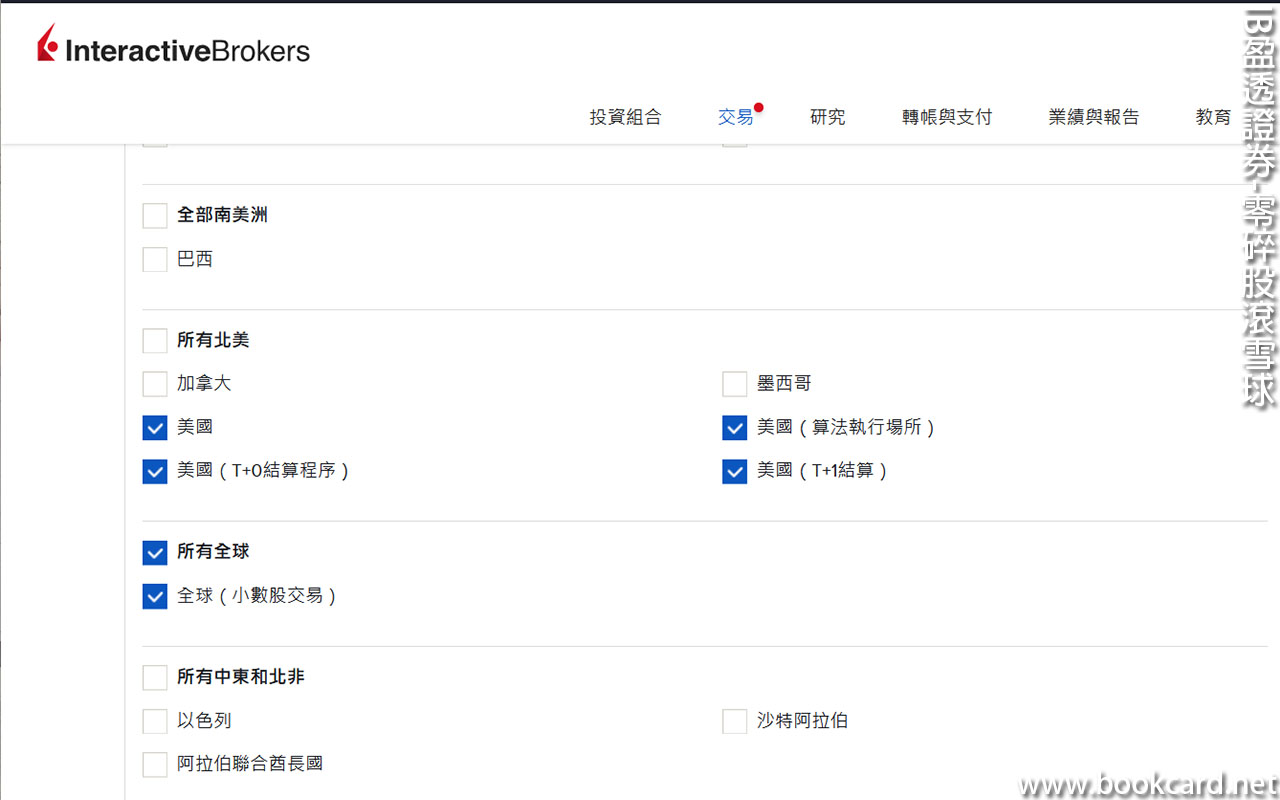
前幾曰『盈透』將『零碎股』沽出, 派『股息』 又冇𢴇行『再投資』. 諗蒞諗去係手多多取消『小數股交易』導致.
| All Global->Global (Trade in Fractions) |
- 登錄『IB盈透證券』官網.
- 係首頁撳『交易』->『交易許可』.
- 撳『股票』->『編輯』.
- 勾『小數股交易』,左下角撳『繼續』.
- 確認更改,左下角撳『繼續』.
www.bookcard.net
前幾曰『盈透』將『零碎股』沽出, 派『股息』 又冇𢴇行『再投資』. 諗蒞諗去係手多多取消『小數股交易』導致.
| All Global->Global (Trade in Fractions) |

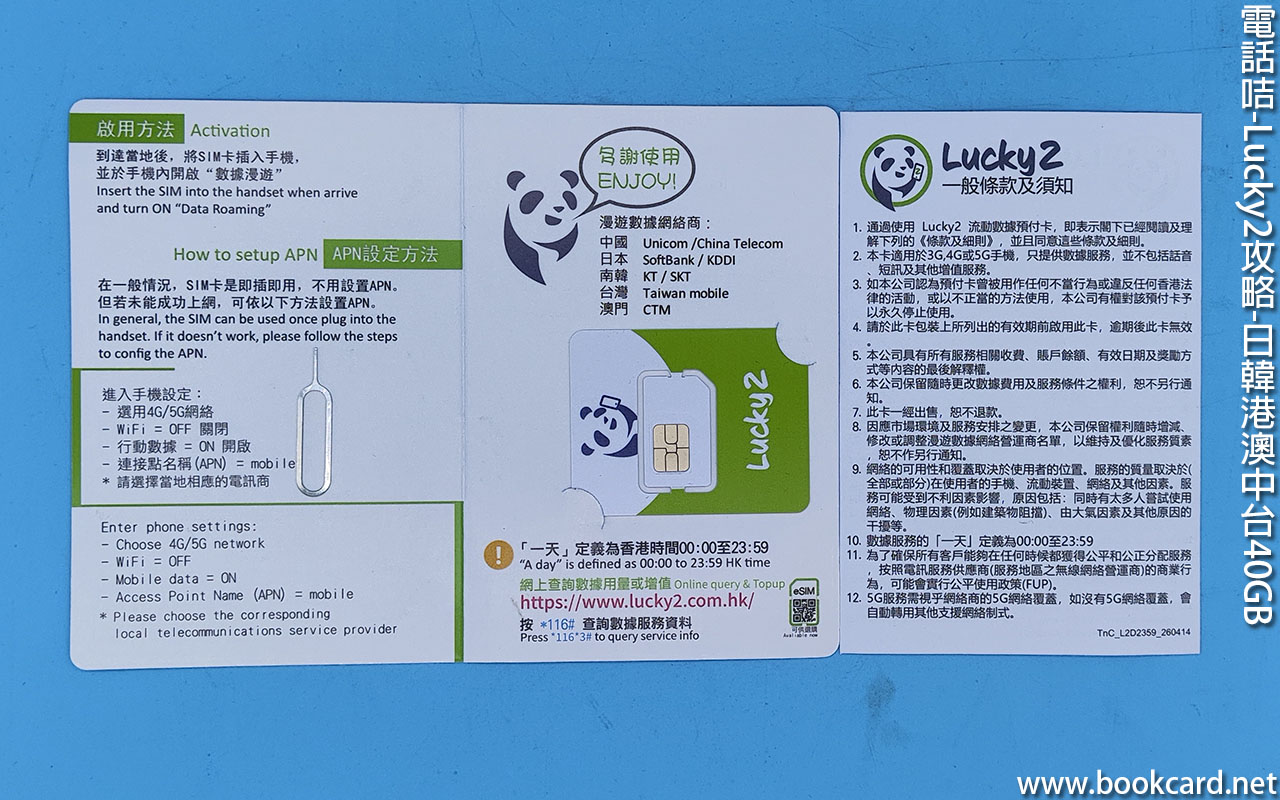
為左做RPG地圖, 上『Google-MAP』『wikipedia』流量好似倒水咁,張『Lucky2-30GB』流量卡, 30GB高速用曬後降為512kbps, 上『Google-MAP』『wikipedia』載入速度慢.
索性幚襯黄牛.買過張『Lucky2』流量卡升级40GB.之後低速512kbps,任用一年,插卡後開通『數據漫遊』.即插即用吾使實名登記.

島國『Singapore星嘉坡』地處『馬拉半島』南便. 佢有另一個名呌『Temasek淡馬錫』. 手扼『馬六甲海峽』 .
『星嘉坡』總人口起過600萬, 劃分『55規劃區』.
| ‘Peck San Theng’ ‘碧山亭’ ‘Bishan’ ‘碧山’ ‘HOUSE’ ‘1.345959’ ‘103.844989’
‘Marymount’ ‘瑪麗蒙’ ‘Bishan’ ‘碧山’ ‘HAMLET’ ‘1.353889’ ‘103.836667’ ‘Thomson’ ‘湯申’ ‘Bishan’ ‘碧山’ ‘HAMLET’ ‘1.355556’ ‘103.835000’ ‘Raffles Institution’ ‘萊佛士書院’ ‘Bishan’ ‘碧山’ ‘HAMLET’ ‘1.346621’ ‘103.843095’ |
| ‘Alexandra’ ‘亞歷山大’ ‘Redhill’ ‘紅山’ ‘HAMLET’ ‘1.286667’ ‘103.796389’
‘Bukit Ho Swee’ ‘河水山’ ‘Redhill’ ‘紅山’ ‘HAMLET’ ‘1.288611’ ‘103.829722’ ‘Depot Road’ ‘德普路’ ‘Redhill’ ‘紅山’ ‘HAMLET’ ‘1.281389’ ‘103.809722’ ‘Harbourfront’ ‘港灣’ ‘Redhill’ ‘紅山’ ‘HAMLET’ ‘1.265278’ ‘103.822222’ ‘Kampong Tiong Bahru’ ‘甘榜中峇魯’ ‘Redhill’ ‘紅山’ ‘HAMLET’ ‘1.278611’ ‘103.826944’ ‘Telok Blangah’ ‘直落布蘭雅’ ‘Redhill’ ‘紅山’ ‘HAMLET’ ‘1.278889’ ‘103.813333’ ‘Radin Mas’ ‘拉丁馬士’ ‘Redhill’ ‘紅山’ ‘HAMLET’ ‘1.269300’ ‘103.827270’ ‘Tiong Bahru’ ‘中峇魯’ ‘Redhill’ ‘紅山’ ‘HAMLET’ ‘1.284950’ ‘103.823590’ |
| ‘Bukit Timah Hill’ ‘武吉知馬山’ ‘Bukit Timah’ ‘武吉知馬’ ‘HAMLET’ ‘1.354680’ ‘103.776440’
‘Holland Village’ ‘荷蘭村’ ‘Bukit Timah’ ‘武吉知馬’ ‘HAMLET’ ‘1.310926’ ‘103.795195’ ‘Holland Road’ ‘荷蘭路’ ‘Bukit Timah’ ‘武吉知馬’ ‘HAMLET’ ‘1.314531’ ‘103.802293’ |
| ‘Anson’ ‘安順’ ‘Downtown Core’ ‘市中心’ ‘HAMLET’ ‘1.273000’ ‘103.844000’
‘Bugis’ ‘武吉士’ ‘Downtown Core’ ‘市中心’ ‘HAMLET’ ‘1.299210’ ‘103.856180’ ‘City Hall’ ‘政府大廈’ ‘Downtown Core’ ‘市中心’ ‘HAMLET’ ‘1.290556’ ‘103.851667’ ‘Clifford Pier’ ‘紅燈碼頭’ ‘Downtown Core’ ‘市中心’ ‘HOUSE’ ‘1.283917’ ‘103.853569’ ‘Marina Centre’ ‘濱海中心’ ‘Downtown Core’ ‘市中心’ ‘HAMLET’ ‘1.291168’ ‘103.857677’ ‘Raffles Place’ ‘萊佛士坊’ ‘Downtown Core’ ‘市中心’ ‘HAMLET’ ‘1.284428’ ‘103.851111’ ‘Tanjong Pagar’ ‘丹戎巴葛’ ‘Downtown Core’ ‘市中心’ ‘HAMLET’ ‘1.276389’ ‘103.846944’ ‘Marina Bay’ ‘濱海灣’ ‘Downtown Core’ ‘市中心’ ‘HAMLET’ ‘1.276073’ ‘103.855042’ ‘Shenton Way’ ‘珊頓道’ ‘Downtown Core’ ‘市中心’ ‘HAMLET’ ‘1.277800’ ‘103.850500’ |
| ‘Geylang Serai’ ‘芽籠士乃’ ‘Geylang’ ‘芽籠’ ‘HAMLET’ ‘1.316702’ ‘103.897083’
‘Aljunied’ ‘阿裕尼’ ‘Geylang’ ‘芽籠’ ‘HAMLET’ ‘1.316442’ ‘103.882981’ ‘Geylang East’ ‘芽籠東’ ‘Geylang’ ‘芽籠’ ‘HAMLET’ ‘1.318278’ ‘103.914778’ ‘Kampong Ubi’ ‘烏美’ ‘Geylang’ ‘芽籠’ ‘HAMLET’ ‘1.329444’ ‘103.898056’ ‘MacPherson’ ‘麥波申’ ‘Geylang’ ‘芽籠’ ‘HAMLET’ ‘1.326667’ ‘103.890000’ |
| ‘Bendemeer’ ‘明地迷亞’ ‘Kallang’ ‘加冷’ ‘HAMLET’ ‘1.320469’ ‘103.865072’
‘Boon Keng’ ‘文慶’ ‘Kallang’ ‘加冷’ ‘HAMLET’ ‘1.315572’ ‘103.873225’ ‘Crawford’ ‘哥羅福’ ‘Kallang’ ‘加冷’ ‘HAMLET’ ‘1.307061’ ‘103.864413’ ‘Geylang Bahru’ ‘芽籠峇魯’ ‘Kallang’ ‘加冷’ ‘HAMLET’ ‘1.322260’ ‘103.869820’ ‘Kallang Bahru’ ‘加冷峇魯’ ‘Kallang’ ‘加冷’ ‘HAMLET’ ‘1.317900’ ‘103.864400’ ‘Kampong Bugis’ ‘甘榜武吉士’ ‘Kallang’ ‘加冷’ ‘HAMLET’ ‘1.306183’ ‘103.867407’ ‘Kampong Java’ ‘甘榜爪哇’ ‘Kallang’ ‘加冷’ ‘HAMLET’ ‘1.313333’ ‘103.850000’ ‘Lavender’ ‘勞明達’ ‘Kallang’ ‘加冷’ ‘HAMLET’ ‘1.298400’ ‘103.856400’ ‘Tanjong Rhu’ ‘丹戎禺’ ‘Kallang’ ‘加冷’ ‘HAMLET’ ‘1.296384’ ‘103.868575’ ‘Jalan Besar’ ‘惹蘭勿剎’ ‘Kallang’ ‘加冷’ ‘HAMLET’ ‘1.309993’ ‘103.860453’ REM ” ‘聖彌額爾’ ‘Kallang’ ‘加冷’ ‘HAMLET’ |
| ‘Marina Bay’ ‘濱海灣’ ‘Marina East’ ‘濱海東’ ‘HAMLET’ ‘1.282220’ ‘103.875636’
‘Marina Bay’ ‘濱海灣’ ‘Marina South’ ‘濱海南’ ‘HAMLET’ ‘1.271263’ ‘103.862964’ |
| ‘East Coast Park’ ‘東海岸’ ‘Marine Parade’ ‘馬林百列’ ‘HAMLET’ ‘1.303999’ ‘103.926369’
‘Katong’ ‘加東’ ‘Marine Parade’ ‘馬林百列’ ‘HAMLET’ ‘1.303917’ ‘103.901174’ ‘Mountbatten’ ‘蒙巴登’ ‘Marine Parade’ ‘馬林百列’ ‘HAMLET’ ‘1.314200’ ‘103.828800’ ‘Joo Chiat’ ‘如切’ ‘Marine Parade’ ‘馬林百列’ ‘HAMLET’ ‘1.312423’ ‘103.901295’ |
| ‘Bras Basah’ ‘勿拉士峇沙 百勝’ ‘Museum’ ‘博物館’ ‘HAMLET’ ‘1.296049’ ‘103.851886’
‘Dhoby Ghaut’ ‘多美歌’ ‘Museum’ ‘博物館’ ‘HAMLET’ ‘1.298333’ ‘103.846111’ ‘Fort Canning’ ‘福康寧’ ‘Museum’ ‘博物館’ ‘HAMLET’ ‘1.294444’ ‘103.846944’ |
| ‘Newton’ ‘紐頓’ ‘Newton’ ‘紐頓’ ‘HAMLET’ ‘1.314036’ ‘103.839408’
‘Emerald Hill’ ‘翡翠山’ ‘Newton’ ‘紐頓’ ‘HAMLET’ ‘1.301922’ ‘103.839220’ |
| ‘Novena Square’ ‘諾維娜廣場’ ‘Novena’ ‘諾維娜’ ‘HAMLET’ ‘1.320858’ ‘103.842431’
‘Balestier’ ‘馬里士他’ ‘Novena’ ‘諾維娜’ ‘HAMLET’ ‘1.325060’ ‘103.850540’ ‘Thomson’ ‘汤申’ ‘Novena’ ‘諾維娜’ ‘HAMLET’ ‘1.354874’ ‘103.830891’ |
| ‘ION Orchard’ ‘愛雍烏節’ ‘Orchard’ ‘烏節’ ‘HAMLET’ ‘1.303969’ ‘103.831953’
‘Somerset’ ‘索美塞’ ‘Orchard’ ‘烏節’ ‘HAMLET’ ‘1.300514’ ‘103.839028’ ‘Emerald Hill’ ‘翡翠山’ ‘Orchard’ ‘烏節’ ‘HAMLET’ ‘1.301806’ ‘103.839056’ |
| ‘Chinatown’ ‘牛車水’ ‘Outram’ ‘歐南’ ‘HAMLET’ ‘1.283446’ ‘103.844453’
‘Telok Ayer’ ‘直落亞逸’ ‘Outram’ ‘歐南’ ‘HAMLET’ ‘1.281169’ ‘103.847849’ ‘Pearls Hill’ ‘珍珠山’ ‘Outram’ ‘歐南’ ‘HAMLET’ ‘1.284444’ ‘103.839167’ ‘Outram Park’ ‘歐南園’ ‘Outram’ ‘歐南’ ‘HAMLET’ ‘1.280278’ ‘103.839444’ |
| ‘Commonwealth’ ‘联邦’ ‘Queenstown’ ‘女皇鎮’ ‘HAMLET’ ‘1.307254’ ‘103.799735’
‘Dover’ ‘杜佛’ ‘Queenstown’ ‘女皇鎮’ ‘HAMLET’ ‘1.304583’ ‘103.780306’ ‘Ghim Moh’ ‘錦茂’ ‘Queenstown’ ‘女皇鎮’ ‘HAMLET’ ‘1.306565’ ‘103.778868’ ‘Kent Ridge’ ‘肯特崗’ ‘Queenstown’ ‘女皇鎮’ ‘HAMLET’ ‘1.293475’ ‘103.784630’ ‘Pasir Panjang’ ‘巴西班讓’ ‘Queenstown’ ‘女皇鎮’ ‘HAMLET’ ‘1.288860’ ‘103.778156’ ‘Queensway’ ‘女皇大道’ ‘Queenstown’ ‘女皇鎮’ ‘HAMLET’ ‘1.293536’ ‘103.799159’ ‘Buona Vista’ ‘波娜維斯達’ ‘Queenstown’ ‘女皇鎮’ ‘HAMLET’ ‘1.307200’ ‘103.790600’ ‘one-north’ ‘緯壹’ ‘Queenstown’ ‘女皇鎮’ ‘HAMLET’ ‘1.299333’ ‘103.787056’ ‘Ayer Rajah Expressway’ ‘亞逸拉惹’ ‘Queenstown’ ‘女皇鎮’ ‘HAMLET’ ‘1.322292’ ‘103.750257’ |
| ‘Holland Village’ ‘荷蘭村’ ‘Queenstown’ ‘女皇鎮’ ‘HAMLET’ ‘1.311111’ ‘103.795000’ |
| ‘River Valley’ ‘里峇峇利’ ‘River Valley’ ‘里峇峇利’ ‘HAMLET’ ‘1.295575’ ‘103.837321’ |
| ‘Bencoolen Street’ ‘明古連’ ‘Rochor’ ‘梧槽’ ‘HAMLET’ ‘1.300556’ ‘103.851667’
‘Farrer Park’ ‘花拉公園’ ‘Rochor’ ‘梧槽’ ‘HAMLET’ ‘1.312376’ ‘103.854180’ ‘Kampong Glam’ ‘甘榜格南’ ‘Rochor’ ‘梧槽’ ‘HAMLET’ ‘1.301944’ ‘103.860833’ ‘Little India’ ‘小印度’ ‘Rochor’ ‘梧槽’ ‘HAMLET’ ‘1.306500’ ‘103.851800’ ‘Mount Emily’ ‘艾米莉山’ ‘Rochor’ ‘梧槽’ ‘HAMLET’ ‘1.304167’ ‘103.847222’ ‘Rochor Canal’ ‘梧槽溝渠’ ‘Rochor’ ‘梧槽’ ‘HOUSE’ ‘1.303244’ ‘103.854087’ ‘Sungei’ ‘雙溪路’ ‘Rochor’ ‘梧槽’ ‘HAMLET’ ‘1.304600’ ‘103.856394’ |
| ‘Boat Quay’ ‘駁船碼頭’ ‘Singapore River’ ‘新加坡河’ ‘HAMLET’ ‘1.286862’ ‘103.849528’
‘Clarke Quay’ ‘克拉碼頭’ ‘Singapore River’ ‘新加坡河’ ‘HAMLET’ ‘1.290017’ ‘103.846089’ ‘Robertson Quay’ ‘羅伯遜碼頭’ ‘Singapore River’ ‘新加坡河’ ‘HAMLET’ ‘1.290278’ ‘103.839722’ |
| ‘Sentosa’ ‘聖淘沙’ ‘Southern Islands’ ‘南部群島’ ‘HAMLET’ ‘1.248000’ ‘103.830000’ |
| ‘Marina Bay’ ‘濱海灣’ ‘Straits View’ ‘海峽景’ ‘HAMLET’ ‘1.283771’ ‘103.859107’ |
| ‘Tanglin’ ‘東陵’ ‘Tanglin’ ‘東陵’ ‘HAMLET’ ‘1.301722’ ‘103.816201’ |
| ‘Bidadari’ ‘比達達利’ ‘Toa Payoh’ ‘大巴窯’ ‘HAMLET’ ‘1.337500’ ‘103.872500’
‘Joo Seng’ ‘裕盛’ ‘Toa Payoh’ ‘大巴窯’ ‘HAMLET’ ‘1.335814’ ‘103.879280’ ‘Potong Pasir’ ‘波東巴西’ ‘Toa Payoh’ ‘大巴窯’ ‘HAMLET’ ‘1.336000’ ‘103.856100’ |
| ‘Bedok Reservoir’ ‘勿洛蓄水池’ ‘Bedok’ ‘勿洛’ ‘HOUSE’ ‘1.339157’ ‘103.922706’
‘Kaki Bukit’ ‘加基武吉’ ‘Bedok’ ‘勿洛’ ‘HAMLET’ ‘1.334934’ ‘103.908964’ ‘Kembangan’ ‘景萬岸’ ‘Bedok’ ‘勿洛’ ‘HAMLET’ ‘Siglap’ ‘實乞納’ ‘Bedok’ ‘勿洛’ ‘HAMLET’ ‘1.314000’ ‘103.936000’ ‘Chai Chee’ ‘菜市’ ‘Bedok’ ‘勿洛’ ‘HAMLET’ ‘1.325650’ ‘103.921470’ ‘Tanah Merah’ ‘丹那美拉’ ‘Bedok’ ‘勿洛’ ‘HAMLET’ ‘1.314297’ ‘103.947314’ |
| ‘Changi Airport’ ‘樟宜機場’ ‘Changi’ ‘樟宜’ ‘HAMLET’ ‘1.359167’ ‘103.989444’
‘Upper Changi Rd E’ ‘樟宜東’ ‘Changi’ ‘樟宜’ ‘HAMLET’ ‘1.337422’ ‘103.959522’ ‘Tanah Merah’ ‘丹那美拉’ ‘Changi’ ‘樟宜’ ‘HAMLET’ ‘1.314297’ ‘103.947314’ |
| ‘Changi Bay’ ‘樟宜灣’ ‘Changi Bay’ ‘樟宜灣’ ‘HAMLET’ ‘1.321974’ ‘104.029002’ |
| ‘Pasir Ris’ ‘巴西立’ ‘Pasir Ris’ ‘巴西立’ ‘HAMLET’ ‘1.372430’ ‘103.949656’
‘Tanah Merah’ ‘丹那美拉’ ‘Pasir Ris’ ‘巴西立’ ‘HAMLET’ ‘1.314297’ ‘103.947314’ ‘Pasir Ris Park’ ‘白沙公園’ ‘Pasir Ris’ ‘巴西立’ ‘HAMLET’ ‘1.381483’ ‘103.950900’ ‘Loyang’ ‘洛陽洛陽’ ‘Pasir Ris’ ‘巴西立’ ‘HAMLET’ ‘1.378611’ ‘103.971667’ |
| ‘Paya Lebar’ ‘巴耶利峇’ ‘Paya Lebar’ ‘巴耶利峇’ ‘HAMLET’ ‘1.353300’ ‘103.893700’
‘Tampines’ ‘淡濱尼’ ‘Paya Lebar’ ‘巴耶利峇’ ‘HAMLET’ ‘1.353330’ ‘103.945222’ ‘Simei’ ‘四美’ ‘Paya Lebar’ ‘巴耶利峇’ ‘HAMLET’ ‘1.343333’ ‘103.954167’ ‘Tanah Merah’ ‘丹那美拉’ ‘Paya Lebar’ ‘巴耶利峇’ ‘HAMLET’ ‘1.314297’ ‘103.947314’ |
| ‘Nature Reserve’ ‘自然保護區’ ‘Central Water Catchment’ ‘中央集水區’ ‘HOUSE’ ‘1.356966’ ‘103.804515’
‘MacRitchie Reservoir’ ‘麥里芝蓄水池’ ‘Central Water Catchment’ ‘中央集水區’ ‘HOUSE’ ‘1.342758’ ‘103.830899’ ‘Upper Seletar Reservoir’ ‘實里達蓄水池上段’ ‘Central Water Catchment’ ‘中央集水區’ ‘HOUSE’ ‘1.399860’ ‘103.806940’ ‘Lower Seletar Reservoir’ ‘實里達蓄水池下段’ ‘Central Water Catchment’ ‘中央集水區’ ‘HOUSE’ ‘1.409908’ ‘103.832002’ ‘Upper Peirce Reservoir’ ‘貝雅士蓄水池上段’ ‘Central Water Catchment’ ‘中央集水區’ ‘HOUSE’ ‘1.373115’ ‘103.811909’ ‘Lower Peirce Reservoir’ ‘貝雅士蓄水池下段’ ‘Central Water Catchment’ ‘中央集水區’ ‘HOUSE’ ‘1.370395’ ‘103.825892’ |
| ‘Neo Ao Tiew’ ‘梁後宙’ ‘Lim Chu Kang’ ‘林厝港’ ‘HAMLET’ ‘1.435861’ ‘103.712307’ |
| ‘Mandai’ ‘萬禮’ ‘Mandai’ ‘萬禮’ ‘HAMLET’ ‘1.411667’ ‘103.786389’ |
| ‘Sembawang’ ‘三巴旺樹’ ‘Sembawang’ ‘三巴旺’ ‘HAMLET’ ‘1.461679’ ‘103.836886’
‘Admiralty’ ‘海軍部’ ‘Sembawang’ ‘三巴旺’ ‘HAMLET’ ‘1.453170’ ‘103.825040’ ‘Senoko’ ‘聖諾哥’ ‘Sembawang’ ‘三巴旺’ ‘HAMLET’ ‘1.463834’ ‘103.801426’ |
| ‘Simpang’ ‘新邦’ ‘Simpang’ ‘新邦’ ‘HAMLET’ ‘1.445294’ ‘103.838228’
‘Seletar Island’ ‘實里達島’ ‘Simpang’ ‘新邦’ ‘HAMLET’ ‘1.442550’ ‘103.862590’ |
| ‘Kranji’ ‘克蘭芝’ ‘Sungei Kadut’ ‘雙溪加株’ ‘HAMLET’ ‘1.422800’ ‘103.750400’
‘Turf Club’ ‘賽馬公會’ ‘Sungei Kadut’ ‘雙溪加株’ ‘HAMLET’ ‘1.421500’ ‘103.760400’ |
| ‘Woodlands’ ‘兀蘭’ ‘Woodlands’ ‘兀蘭’ ‘HAMLET’ ‘1.437094’ ‘103.786483’
‘Marsiling’ ‘馬西嶺’ ‘Woodlands’ ‘兀蘭’ ‘HAMLET’ ‘1.432508’ ‘103.774069’ ‘Admiralty’ ‘海軍部’ ‘Woodlands’ ‘兀蘭’ ‘HAMLET’ ‘1.440689’ ‘103.800933’ |
| ‘Yishun’ ‘義順’ ‘Yishun’ ‘義順鎮’ ‘HAMLET’ ‘1.429458’ ‘103.835005’
‘Lower Seletar’ ‘實里達下’ ‘Yishun’ ‘義順鎮’ ‘HAMLET’ ‘1.411384’ ‘103.834141’ |
| ‘Cheng San’ ‘靜山’ ‘Ang Mo Kio’ ‘宏茂橋’ ‘Singapore’ ‘HAMLET’ ‘1.373646’ ‘103.854606’
‘Chong Boon’ ‘崇文’ ‘Ang Mo Kio’ ‘宏茂橋’ ‘Singapore’ ‘HAMLET’ ‘1.370000’ ‘103.845556’ ‘Kebun Baru’ ‘哥本峇魯’ ‘Ang Mo Kio’ ‘宏茂橋’ ‘Singapore’ ‘HAMLET’ ‘1.373333’ ‘103.837222’ ‘Yio Chu Kang’ ‘楊厝港’ ‘Ang Mo Kio’ ‘宏茂橋’ ‘Singapore’ ‘HAMLET’ ‘1.381111’ ‘103.844167’
|
| ‘Defu Industrial Park’ ‘德福工業園區’ ‘Hougang’ ‘後港’ ‘HAMLET’ ‘1.349900’ ‘103.885800’
‘Kovan’ ‘高文’ ‘Hougang’ ‘後港’ ‘HAMLET’ ‘1.360900’ ‘103.874100’ ‘Lorong Halus’ ‘羅弄哈魯士’ ‘Hougang’ ‘後港’ ‘HAMLET’ ‘1.378889’ ‘103.927500’ |
| ‘Tekong Island’ ‘德光島’ ‘North-Eastern Islands’ ‘東北群島’ ‘HOUSE’ ‘1.408056’ ‘104.055833’
‘Tekong Kechil Island’ ‘小德光島’ ‘North-Eastern Islands’ ‘東北群島’ ‘HOUSE’ ‘1.416572’ ‘104.016275’ ‘Pulau Ubin’ ‘烏敏島’ ‘North-Eastern Islands’ ‘東北群島’ ‘HOUSE’ ‘1.409444’ ‘103.960000’ |
| ‘Punggol’ ‘榜鵝’ ‘Punggol’ ‘榜鵝’ ‘HAMLET’ ‘1.405278’ ‘103.902222’
‘Pulau Serangoon’ ‘實龍崗島’ ‘Punggol’ ‘榜鵝’ ‘HOUSE’ ‘1.408889’ ‘103.922500’ |
| ‘Seletar Aerospace Park’ ‘實里達航空園區’ ‘Seletar’ ‘實里達’ ‘HAMLET’ ‘1.414169’ ‘103.871406’ |
| ‘Anchorvale’ ‘安谷’ ‘Sengkang’ ‘盛港’ ‘HAMLET’ ‘1.392625’ ‘103.889064’
‘Buangkok’ ‘萬國’ ‘Sengkang’ ‘盛港’ ‘HAMLET’ ‘1.379194’ ‘103.881333’ ‘Compassvale’ ‘康埔樺’ ‘Sengkang’ ‘盛港’ ‘HAMLET’ ‘1.390889’ ‘103.897611’ ‘Fernvale’ ‘芬維爾’ ‘Sengkang’ ‘盛港’ ‘HAMLET’ ‘1.393083’ ‘103.877611’ ‘Jalan Kayu’ ‘惹蘭加由’ ‘Sengkang’ ‘盛港’ ‘HAMLET’ ‘1.396750’ ‘103.873083’ ‘Rivervale’ ‘河谷’ ‘Sengkang’ ‘盛港’ ‘HAMLET’ ‘1.387306’ ‘103.904639’ |
| ‘Serangoon Garden’ ‘紅砂厘’ ‘Serangoon’ ‘實龍崗’ ‘HAMLET’ ‘1.363855’ ‘103.866070’
‘Serangoon North’ ‘實龍崗北’ ‘Serangoon’ ‘實龍崗’ ‘HAMLET’ ‘1.369754’ ‘103.872699’ ‘Lorong Chuan’ ‘羅弄泉’ ‘Serangoon’ ‘實龍崗’ ‘HAMLET’ ‘1.353611’ ‘103.864167’ |
| ‘Chew Boon Lay’ ‘周文禮’ ‘Boon Lay’ ‘文禮’ ‘HAMLET’ ‘1.345914’ ‘103.711625’
‘Jurong’ ‘裕廊’ ‘Boon Lay’ ‘文禮’ ‘HAMLET’ ‘1.339757’ ‘103.706730’ ‘Samulun’ ‘莎慕倫’ ‘Boon Lay’ ‘文禮’ ‘HAMLET’ ‘1.303347’ ‘103.696944’ |
|
‘Bukit Batok Central’ ‘武吉巴督環’ ‘Bukit Batok’ ‘武吉巴督’ ‘HAMLET’ ‘1.349735’ ‘103.749971’ ‘Brickworks’ ‘磚廠’ ‘Bukit Batok’ ‘武吉巴督’ ‘HAMLET’ ‘1.286557’ ‘103.808359’ ‘Bukit Gombak’ ‘武吉甘柏’ ‘Bukit Batok’ ‘武吉巴督’ ‘HAMLET’ ‘1.358794’ ‘103.751997’ ‘Guilin’ ‘桂林’ ‘Bukit Batok’ ‘武吉巴督’ ‘HAMLET’ ‘1.355556’ ‘103.753056’ ‘Hillview’ ‘山景’ ‘Bukit Batok’ ‘武吉巴督’ ‘HAMLET’ ‘1.362278’ ‘103.764778’ |
| ‘Bukit Panjang’ ‘武吉班讓’ ‘Bukit Panjang’ ‘武吉班讓’ ‘CITE’ ‘1.379000’ ‘103.761537’
‘Dairy Farm Nature Park’ ‘奶牛農場自然公園’ ‘Bukit Panjang’ ‘武吉班讓’ ‘HOUSE’ ‘1.364030’ ‘103.776397’ ‘Bukit Timah Nature Reserve’ ‘武吉知馬自然保護區’ ‘Bukit Panjang’ ‘武吉班讓’ ‘HOUSE’ ‘1.352778’ ‘103.778333’ |
| ‘Choa Chu Kang’ ‘蔡厝港’ ‘Choa Chu Kang’ ‘蔡厝港’ ‘HAMLET’ ‘1.384708’ ‘103.744537’
‘Keat Hong ‘ ‘吉豐’ ‘Choa Chu Kang’ ‘蔡厝港’ ‘HAMLET’ ‘1.378614’ ‘103.749060’ ‘Yew Tee’ ‘油池’ ‘Choa Chu Kang’ ‘蔡厝港’ ‘HAMLET’ ‘1.397565’ ‘103.747451’ |
| ‘Clementi’ ‘金文泰’ ‘Clementi’ ‘金文泰’ ‘HAMLET’ ‘1.315508’ ‘103.765056’
‘Mount Faber’ ‘花柏’ ‘Clementi’ ‘金文泰’ ‘HOUSE’ ‘1.271190’ ‘103.819364’ ‘Toh Tuck’ ‘道德’ ‘Clementi’ ‘金文泰’ ‘HAMLET’ ‘1.340948’ ‘103.745812’ ‘West Coast’ ‘西海岸’ ‘Clementi’ ‘金文泰’ ‘HAMLET’ ‘1.316278’ ‘103.755083’ |
| ‘Jurong’ ‘裕廊’ ‘Jurong East’ ‘裕廊東’ ‘HAMLET’ ‘1.348956’ ‘103.719364’
‘International Business Park’ ‘國際商業園’ ‘Jurong East’ ‘裕廊東’ ‘HAMLET’ ‘1.329583’ ‘103.747500’ ‘Jurong Lake District’ ‘裕廊湖區’ ‘Jurong East’ ‘裕廊東’ ‘HAMLET’ ‘1.334864’ ‘103.726456’ ‘Jurong Port’ ‘裕廊港’ ‘Jurong East’ ‘裕廊東’ ‘HAMLET’ ‘1.236899’ ‘103.680541’ ‘Jurong River’ ‘裕廊河’ ‘Jurong East’ ‘裕廊東’ ‘HOUSE’ ‘1.301851’ ‘103.726297’ ‘Penjuru Crescent’ ‘本茱魯彎’ ‘Jurong East’ ‘裕廊東’ ‘HOUSE’ ‘1.307502’ ‘103.750479’ ‘Teban Gardens’ ‘德曼花園’ ‘Jurong East’ ‘裕廊東’ ‘HAMLET’ ‘1.320667’ ‘103.740892’ ‘Yuhua’ ‘裕華’ ‘Jurong East’ ‘裕廊東’ ‘HAMLET’ ‘1.343719’ ‘103.737801’ ‘Ulu Pandan Depot’ ‘烏魯班丹’ ‘Jurong East’ ‘裕廊東’ ‘HAMLET’ ‘1.333425’ ‘103.760142’ |
| ‘Jurong’ ‘裕廊’ ‘Jurong West’ ‘裕廊西’ ‘HAMLET’ ‘1.348956’ ‘103.719364’
‘Jurong West Central’ ‘裕廊西環’ ‘Jurong West’ ‘裕廊西’ ‘HAMLET’ ‘1.342626’ ‘103.705444’ ‘Old Boon Lay’ ‘老文禮’ ‘Jurong West’ ‘裕廊西’ ‘HAMLET’ ‘1.345233’ ‘103.712826’ ‘Chin Bee’ ‘振美’ ‘Jurong West’ ‘裕廊西’ ‘HAMLET’ ‘1.333226’ ‘103.711830’ ‘Hong Kah’ ‘豐加’ ‘Jurong West’ ‘裕廊西’ ‘HAMLET’ ‘1.349722’ ‘103.721111’ ‘Kian Teck’ ‘建德’ ‘Jurong West’ ‘裕廊西’ ‘HAMLET’ ‘1.330600’ ‘103.691200’ ‘Singapore Armed Forces’ ‘武裝部隊軍訓學院’ ‘Jurong West’ ‘裕廊西’ ‘HAMLET’ ‘1.333683’ ‘103.680334’ ‘Taman Jurong’ ‘達曼裕廊’ ‘Jurong West’ ‘裕廊西’ ‘HAMLET’ ‘1.334658’ ‘103.720493’ ‘Wenya’ ‘文雅’ ‘Jurong West’ ‘裕廊西’ ‘HAMLET’ ‘1.351673’ ‘103.705473’ ‘Yunnan’ ‘雲南’ ‘Jurong West’ ‘裕廊西’ ‘HAMLET’ ‘1.342924’ ‘103.684815’s |
| ‘Pioneer’ ‘先驅’ ‘Pioneer’ ‘先驅’ ‘HAMLET’ ‘1.337640’ ‘103.696897’
‘Jurong’ ‘裕廊’ ‘Pioneer’ ‘先驅’ ‘HAMLET’ ‘1.348956’ ‘103.719364’ ‘Benoi’ ‘賁耐’ ‘Pioneer’ ‘先驅’ ‘HAMLET’ ‘1.318006’ ‘103.690667’ ‘Gul Circle’ ‘卡爾圈’ ‘Pioneer’ ‘先驅’ ‘HAMLET’ ‘1.322778’ ‘103.663500’ ‘Joo Koon’ ‘裕群’ ‘Pioneer’ ‘先驅’ ‘HAMLET’ ‘1.327749’ ‘103.678320’ ‘Pioneer Sector’ ‘先驅段’ ‘Pioneer’ ‘先驅’ ‘HAMLET’ ‘1.297330’ ‘103.669251’ |
| ‘Tengah’ ‘登加新城’ ‘Tengah’ ‘登加’ ‘HAMLET’ ‘1.356826’ ‘103.734653’
REM ‘Plantation’ ‘田園’ ‘Tengah’ ‘登加’ ‘HAMLET’ REM ‘Garden’ ‘綠苑’ ‘Tengah’ ‘登加’ ‘HAMLET’ REM ‘Park’ ‘園林’ ‘Tengah’ ‘登加’ ‘HAMLET’ REM ‘Brickland’ ‘碧蘭’ ‘Tengah’ ‘登加’ ‘HAMLET’ REM ‘Forest Hill’ ‘山景’ ‘Tengah’ ‘登加’ ‘HAMLET’ |
| ‘Tuas’ ‘大士’ ‘Tengah’ ‘登加’ ‘HAMLET’ ‘1.317382’ ‘103.651367’
‘Tuas View’ ‘大士南’ ‘Tengah’ ‘登加’ ‘HAMLET’ ‘1.299834’ ‘103.626024’ |
| ‘Jurong Island’ ‘裕廊島’ ‘Western Islands’ ‘西部群島’ ‘HAMLET’ ‘1.270100’ ‘103.695900’
‘Bukom Island’ ‘毛廣島’ ‘Western Islands’ ‘西部群島’ ‘HAMLET’ ‘1.233333’ ‘103.764444’s ‘Semakau Island’ ‘實馬高島’ ‘Western Islands’ ‘西部群島’ ‘HAMLET’ ‘1.206111’ ‘103.761944’ ‘Sudong Island’ ‘蘇東島’ ‘Western Islands’ ‘西部群島’ ‘HAMLET’ ‘1.208333’ ‘103.721389’ |
| ‘Tengeh Reservoir’ ‘登格蓄水池’ ‘Western Water Catchment’ ‘西部集水區’ ‘HAMLET’ ‘1.343110’ ‘103.649458’
‘Poyan Reservoir’ ‘波揚蓄水池’ ‘Western Water Catchment’ ‘西部集水區’ ‘HAMLET’ ‘1.376944’ ‘103.663889’ ‘Murai Reservoir’ ‘慕萊蓄水池’ ‘Western Water Catchment’ ‘西部集水區’ ‘HAMLET’ ‘1.403021’ ‘103.672821’ ‘Sarimbun Reservoir’ ‘莎琳汶蓄水池’ ‘Western Water Catchment’ ‘西部集水區’ ‘HAMLET’ ‘1.424291’ ‘103.683178’ ‘Pasir Laba Camp’ ‘巴西拉峇军营’ ‘Western Water Catchment’ ‘西部集水區’ ‘HAMLET’ ‘1.333958’ ‘103.672342’ |


占卦批命最靈『金吊桶』.清未羊城城煌廟蒞左『占卦腥』,自言『妻財子祿,壽夭窮通』.仝你傾謁之閒,可知一生富貴,過去未來.
傳說老金係羊城北郊偶遇後生女仔, 睇中老金忠實, 愿嫁畀老金,草過門後, 原蒞老婆係狐仙識通靈,平日匿係閣樓,係樓板開窿,将木桶仔髹金色,從閣樓吊隻金桶落蒞, 取出命紙, 所以自稱『金吊桶』.
當時老襯多, 信以為真, 個個稳佢占卦, 其門如市,日日收入幾拾兩, 『金吊桶』掩住口笑.
老金鬼馬,占卜得閑, 有閑錢, 去『帶河基』『顯耀里』『怡心寨』打水圍, 仝老舉『花月痕』結緣.
『花月痕』聰惠,老金幫姖贖身,埋街喫井水.教『花月痕』占卦批命, 先學生辰轉八字,再學排大運, 睇流年,算用神, 稳忌神. 『花月痕』學成後匿係閣樓,自稱狐仙. 有老襯蒞占卦, 老金先問牛一,仝老襯傾謁. 傾得百句, 閣樓趟門吊金桶落蒞,
老金係桶拎出命書: 老友, 狐仙能知過去未來,幫你批左命.
命書內容, 果然仝『前半世』經歷大略相合, 至於『後半世』亂車大炮, 反正冇人知, 市民以為真有狐仙, 一傳十, 十傅百, 『金吊桶』名利雙收.

北韓割據於韓半島以北,行政區劃分『道』,『道』以下劃分『市』『郡』,大城市祇有28個. 直轄市『平壤』.『特別市』祇有『開城』『南浦』『羅先』.係『市』『郡』以下劃分『區』『邑』『里』『洞』.
城市數據分9類.
| 市英文 | 市漢字 | 道英文 | 道漢字 | 國英文 | 國漢字 | 分類 | 經度 | 緯度 |
下列係北韓城市數據庫
| ‘Pyongyang’ ‘平壤’ ‘Phyongannam-do’ ‘平安南道’ ‘CAPITAL’ ‘39.033852’ ‘125.754318’
REM ‘Pyeongyang’ ‘平壤’ ‘Phyongannam-do’ ‘平安南道’ ‘CAPITAL’ ‘39.016667’ 125.747500 ‘Pyeongseong”平城’ ‘Phyongannam-do’ ‘平安南道’ ‘CITE’ ‘39.250000’ ‘125.850000’ REM ‘Pyongsong’ ‘平城’ ‘Phyongannam-do’ ‘平安南道’ ‘CITE’ ‘39.250000’ ‘125.850000’ ‘Sunchon’ ‘順川’ ‘Phyongannam-do’ ‘平安南道’ ‘CITE’ ‘39.416667’ ‘125.933333’ REM ‘Suncheon”順川’ ‘Phyongannam-do’ ‘平安南道’ ‘CITE’ ‘39.416667’ ‘125.933333’ ‘Tokchon’ ‘德川’ ‘Phyongannam-do’ ‘平安南道’ ‘CITE’ ‘39.800000’ ‘126.300000’ REM ‘Deokcheon’ ‘德川’ ‘Phyongannam-do’ ‘平安南道’ ‘CITE’ ‘39.800000’ ‘126.300000’ ‘Anju’ ‘安州’ ‘Phyongannam-do’ ‘平安南道’ ‘CITE’ ‘39.617779’ ‘125.664719’ ‘Chongnam”清南’ ‘Phyongannam-do’ ‘平安南道’ ‘CITE’ ‘39.491389’ ‘125.460278’ REM ‘Cheongnam’ ‘清南’ ‘Phyongannam-do’ ‘平安南道’ ‘CITE’ ‘39.491389’ ‘125.460278’ ‘Nyongwon”寧遠’ ‘Phyongannam-do’ ‘平安南道’ ‘FORT’ ‘39.807030’ ‘125.790535’ ‘Taedong’ ‘大同’ ‘Phyongannam-do’ ‘平安南道’ ‘CITE’ ‘39.080540’ ‘125.536244’ REM ‘Daedong’ ‘大同’ ‘Phyongannam-do’ ‘平安南道’ ‘CITE’ ‘39.080540’ ‘125.536244’ ‘Daeheung”大興’ ‘Phyongannam-do’ ‘平安南道’ ‘FORT’ ‘40.082778’ ‘126.951111’ REM ‘Taehung’ ‘大興’ ‘Phyongannam-do’ ‘平安南道’ ‘FORT’ ‘40.082778’ ‘126.951111’ ‘Mundeok’ ‘文德’ ‘Phyongannam-do’ ‘平安南道’ ‘CITE’ ‘39.499030’ ‘125.592931’ REM ‘Mundok’ ‘文德’ ‘Phyongannam-do’ ‘平安南道’ ‘CITE’ ‘39.499030’ ‘125.592931’ ‘Maengsan”孟山’ ‘Phyongannam-do’ ‘平安南道’ ‘FORT’ ‘39.657798’ ‘126.506290’ ‘Pukchang”北倉’ ‘Phyongannam-do’ ‘平安南道’ ‘CITE’ ‘39.570556’ ‘126.296944’ ‘Bukchang”北倉’ ‘Phyongannam-do’ ‘平安南道’ ‘CITE’ ‘39.570556’ ‘126.296944’ ‘Songchon”成川’ ‘Phyongannam-do’ ‘平安南道’ ‘CITE’ ‘39.237069’ ‘126.212264’ REM ‘Seongcheon’ ‘成川’ ‘Phyongannam-do’ ‘平安南道’ ‘CITE’ ‘39.263333’ ‘126.216389’ ‘Sukcheon”肅川’ ‘Phyongannam-do’ ‘平安南道’ ‘CITE’ ‘39.422883’ ‘125.624585’ REM ‘Sukchon’ ‘肅川’ ‘Phyongannam-do’ ‘平安南道’ ‘CITE’ ‘39.422883’ ‘125.624585’ ‘Sinyang’ ‘新陽’ ‘Phyongannam-do’ ‘平安南道’ ‘FORT’ ‘39.374167’ ‘126.553889’ ‘Jeungsan”甑山’ ‘Phyongannam-do’ ‘平安南道’ ‘CITE’ ‘39.097124’ ‘125.376900’ REM ‘Chungsan”甑山’ ‘Phyongannam-do’ ‘平安南道’ ‘CITE’ ‘39.097124’ ‘125.376900’ ‘Pyeongwon’ ‘平原’ ‘Phyongannam-do’ ‘平安南道’ ‘CITE’ ‘39.302022’ ‘125.601146’ REM ‘Pyongwon”平原’ ‘Phyongannam-do’ ‘平安南道’ ‘CITE’ ‘39.302022’ ‘125.601146’ ‘Hoechang”檜倉’ ‘Phyongannam-do’ ‘平安南道’ ‘FORT’ ‘39.083333’ ‘126.416667’ ‘Yangdok’ ‘陽德’ ‘Phyongannam-do’ ‘平安南道’ ‘FORT’ ‘39.220606’ ‘126.651802’ rem ‘Yangdeok”陽德’ ‘Phyongannam-do’ ‘平安南道’ ‘FORT’ ‘39.220606’ ‘126.651802’ ‘Unsan”殷山’ ‘Phyongannam-do’ ‘平安南道’ ‘CITE’ ‘39.390323’ ‘126.029234’ rem ‘Eunsan’ ‘殷山’ ‘Phyongannam-do’ ‘平安南道’ ‘CITE’ ‘39.390323’ ‘126.029234’ ‘Nampo’ ‘鎮南浦’ ‘Phyongannam-do’ ‘平安南道’ ‘CAPITAL’ ‘38.737499’ ‘125.407784’ ‘Yonggang-up’ ‘龍岡邑’ ‘Phyongannam-do’ ‘平安南道’ ‘FORT’ ‘38.85611’ ‘125.424438’ ‘Kangdong-up’ ‘江東邑’ ‘Phyongannam-do’ ‘平安南道’ ‘FORT’ ‘39.142502’ ‘126.096107’ ‘Sangsong-ni’ ‘相松里’ ‘Phyongannam-do’ ‘平安南道’ ‘FORT’ ‘39.169441’ ‘126.885559’ ‘Sil-li”新里’ ‘Phyongannam-do’ ‘平安南道’ ‘FORT’ ‘39.49472’ ‘125.47361’ ‘Sinanju’ ‘新安州’ ‘Phyongannam-do’ ‘平安南道’ ‘FORT’ ‘39.598061’ ‘125.609718’ ‘Sunan’ ‘順安’ ‘Phyongannam-do’ ‘平安南道’ ‘FORT’ ‘39.19833’ ‘125.690002’ |
| ‘Sinuiju’ ‘新義州’ ‘Phyonganbuk-do’ ‘平安北道”CAPITAL’ ‘40.100559’ ‘124.398064’
‘Kusong’ ‘龜城”Phyonganbuk-do’ ‘平安北道”CAPITAL”39.949192’ ‘125.223812’ ‘Chongju’ ‘定州”Phyonganbuk-do’ ‘平安北道”CITE”39.693329’ ‘125.210281’ REM ‘Jeongju’ ‘定州”Phyonganbuk-do’ ‘平安北道”CITE”39.697660’ ‘125.206587’ ‘Kujang-up’ ‘球場”Phyonganbuk-do’ ‘平安北道”FORT”39.864490’ ‘126.034387’ ‘Kwaksan’ ‘郭山”Phyonganbuk-do’ ‘平安北道”FORT”39.6875”125.082779’ ‘Yongbyon”寧邊”Phyonganbuk-do’ ‘平安北道”FORT”39.813332’ ‘125.804169’ REM ‘Nyongbyon’ ‘寧邊”Phyonganbuk-do’ ‘平安北道”FORT”39.807822’ ‘125.793624’ ‘Tongnim’ ‘東林”Phyonganbuk-do’ ‘平安北道”FORT”39.860539’ ‘124.706328’ REM ‘Dongnim’ ‘東林”Phyonganbuk-do’ ‘平安北道”FORT”39.860539’ ‘124.706328’ REM ‘Tongchang’ ‘東倉”Phyonganbuk-do’ ‘平安北道”FORT”0’ ‘0’ REM ‘Tongchang’ ‘東倉邑동창읍’ ‘Phyonganbuk-do’ ‘平安北道”FORT”0’ ‘0’ ‘Taegwan’ ‘大館”Phyonganbuk-do’ ‘平安北道”FORT”40.208845’ ‘125.204501’ ‘Ryongchon’ ‘龍川”Phyonganbuk-do’ ‘平安北道”FORT”39.982637’ ‘124.462418’ ‘Pakchon’ ‘博川”Phyonganbuk-do’ ‘平安北道”FORT”39.720355’ ‘125.586320’ ‘Pyoktong”碧潼”Phyonganbuk-do’ ‘平安北道”FORT”40.580290’ ‘125.327939’ ‘Sakju”朔州”Phyonganbuk-do’ ‘平安北道”FORT”40.390646’ ‘125.040758’ ‘Sonchon’ ‘宣川”Phyonganbuk-do’ ‘平安北道”FORT”39.797324’ ‘124.917382’ ‘Sindo”薪島”Phyonganbuk-do’ ‘平安北道”FORT”39.903484’ ‘124.265491’ ‘Changsong’ ‘昌城’ ‘Phyonganbuk-do’ ‘平安北道”FORT”40.450743’ ‘125.213622’ REM ‘Changseong’ ‘昌城’ ‘Phyonganbuk-do’ ‘平安北道”FORT”40.450743’ ‘125.213622’ REM ‘Chonma’ ‘天摩”Phyonganbuk-do’ ‘平安北道”FORT’ ‘0’ ‘0’ REM ‘Chonma’ ‘天摩邑천마읍”Phyonganbuk-do’ ‘平安北道”FORT’ ‘0’ ‘0’ ‘Cholsan’ ‘鐵山”Phyonganbuk-do’ ‘平安北道”FORT”39.774766’ ‘124.666159’ ‘Thaechon”泰川”Phyonganbuk-do’ ‘平安北道”FORT”39.915679’ ‘125.487767’ ‘Phihyon’ ‘枇峴”Phyonganbuk-do’ ‘平安北道”FORT”40.012748’ ‘124.619784’ ‘Yomju”鹽州”Phyonganbuk-do’ ‘平安北道”FORT”39.887898’ ‘124.598358’ ‘Yomju-up”鹽州邑’ ‘Phyonganbuk-do’ ‘平安北道”FORT”39.89333’ ‘124.598061’ ‘Unsan”雲山”Phyonganbuk-do’ ‘平安北道”FORT”40.189601’ ‘125.753822’ ‘Unjon”雲田”Phyonganbuk-do’ ‘平安北道”FORT”39.661866’ ‘125.519282’ REM ‘Unjeon’ ‘雲田”Phyonganbuk-do’ ‘平安北道”FORT”39.661866’ ‘125.519282’ ‘Uiju’ ‘義州”Phyonganbuk-do’ ‘平安北道”FORT”40.197787’ ‘124.535154’ ‘Supung’ ‘水豐”Phyonganbuk-do’ ‘平安北道”FORT”40.448701’ ‘124.944467’ ‘Panghyon-dong’ ‘方峴洞’ ‘Phyonganbuk-do’ ‘平安北道”FORT”39.887218’ ‘125.241386’ ‘Pukchil-lodongjagu’ ‘北窒勞動者區’ ‘Phyonganbuk-do’ ‘平安北道’ ‘FORT’ ‘40.201939’ ‘125.748329’ ‘Sakchu-up’ ‘朔州邑’ ‘Phyonganbuk-do’ ‘平安北道’ ‘FORT’ ‘40.389439’ ‘125.046669’
|
|
‘Hamhung”咸興’ ‘Hamgyongnam-do’ ‘咸鏡南道’ ‘CITE’ ‘39.918331’ ‘127.536392’ REM ‘Hamheung’ ‘咸興’ ‘Hamgyongnam-do’ ‘咸鏡南道’ ‘CITE’ ‘39.916667’ ‘127.533333’ ‘Tanchon”端川’ ‘Hamgyongnam-do’ ‘咸鏡南道’ ‘CITE’ ‘40.458056’ ‘128.911111’ REM ‘Dancheon’ ‘端川’ ‘Hamgyongnam-do’ ‘咸鏡南道’ ‘CITE’ ‘40.458056’ ‘128.911111’ ‘Sinpho’ ‘新浦’ ‘Hamgyongnam-do’ ‘咸鏡南道’ ‘CITE’ ‘40.036911’ ‘128.184271’ REM ‘Sinpo’ ‘新浦’ ‘Hamgyongnam-do’ ‘咸鏡南道’ ‘CITE’ ‘40.036911’ ‘128.184271’ ‘Kumho’ ‘琴湖’ ‘Hamgyongnam-do’ ‘咸鏡南道’ ‘CITE’ ‘40.095000’ ‘128.341111’ REM ‘Geumho’ ‘琴湖’ ‘Hamgyongnam-do’ ‘咸鏡南道’ ‘CITE’ ‘40.095000’ ‘128.341111’ ‘Kowon-up’ ‘高原’ ‘Hamgyongnam-do’ ‘咸鏡南道’ ‘FORT’ ‘39.438061’ ‘127.243057’ REM ‘Gowon’ ‘高原’ ‘Hamgyongnam-do’ ‘咸鏡南道’ ‘FORT’ ‘39.440556’ ‘127.238611’ ‘Kumya’ ‘金野’ ‘Hamgyongnam-do’ ‘咸鏡南道’ ‘CITE’ ‘39.545957’ ‘127.239774’ REM ‘Geumya’ ‘金野’ ‘Hamgyongnam-do’ ‘咸鏡南道’ ‘CITE’ ‘39.545957’ ‘127.239774’ ‘Toksong”德城’ ‘Hamgyongnam-do’ ‘咸鏡南道’ ‘FORT’ ‘40.313333’ ‘128.272222’ REM ‘Deokseong’ ‘德城’ ‘Hamgyongnam-do’ ‘咸鏡南道’ ‘FORT’ ‘40.313333’ ‘128.272222’ ‘Ragwon’ ‘樂園’ ‘Hamgyongnam-do’ ‘咸鏡南道’ ‘FORT’ ‘39.902737’ ‘127.773494’ ‘Riwon’ ‘利原’ ‘Hamgyongnam-do’ ‘咸鏡南道’ ‘FORT’ ‘40.324211’ ‘128.650729’ ‘Iwon-up’ ‘利原邑’ ‘Hamgyongnam-do’ ‘咸鏡南道’ ‘FORT’ ‘40.323059’ ‘128.655273’ ‘Pujŏn’ ‘赴戰’ ‘Hamgyongnam-do’ ‘咸鏡南道’ ‘FORT’ ‘40.491017’ ‘127.621035’ REM ‘Bujeon’ ‘赴戰’ ‘Hamgyongnam-do’ ‘咸鏡南道’ ‘FORT’ ‘40.491017’ ‘127.621035’ ‘Pukchong’ ‘北青’ ‘Hamgyongnam-do’ ‘咸鏡南道’ ‘CITE’ ‘40.254908’ ‘128.317370’ REM ‘Bukcheong’ ‘北青’ ‘Hamgyongnam-do’ ‘咸鏡南道’ ‘CITE’ ‘40.254908’ ‘128.317370’ ‘Sinhung”新興’ ‘Hamgyongnam-do’ ‘咸鏡南道’ ‘CITE’ ‘40.196037’ ‘127.550747’ REM ‘Sinheung’ ‘新興’ ‘Hamgyongnam-do’ ‘咸鏡南道’ ‘CITE’ ‘40.196037’ ‘127.550747’ ‘Jangjin”長津’ ‘Hamgyongnam-do’ ‘咸鏡南道’ ‘FORT’ ‘40.380414’ ‘127.242939’ REM ‘Changjin’ ‘長津’ ‘Hamgyongnam-do’ ‘咸鏡南道’ ‘FORT’ ‘40.4’ ‘127.3’ ‘Jeongphyong’ ‘定平’ ‘Hamgyongnam-do’ ‘咸鏡南道’ ‘FORT’ ‘39.786682’ ‘127.388727’ REM ‘Chongpyong’ ‘定平’ ‘Hamgyongnam-do’ ‘咸鏡南道’ ‘FORT’ ‘39.786682’ ‘127.388727’ ‘Hamju’ ‘咸州’ ‘Hamgyongnam-do’ ‘咸鏡南道’ ‘CITE’ ‘39.854937’ ‘127.437767’ ‘Hochon’ ‘虛川’ ‘Hamgyongnam-do’ ‘咸鏡南道’ ‘CITE’ ‘40.679123’ ‘128.612600’ REM ‘Heocheon’ ‘虛川’ ‘Hamgyongnam-do’ ‘咸鏡南道’ ‘CITE’ ‘40.679123’ ‘128.612600’ ‘Hongwon”洪原’ ‘Hamgyongnam-do’ ‘咸鏡南道’ ‘CITE’ ‘40.024405’ ‘127.968365’ ‘Yonggwang-up’ ‘榮光’ ‘Hamgyongnam-do’ ‘咸鏡南道’ ‘CITE’ ‘40.021862’ ‘127.455912’ REM ‘Yeonggwang’ ‘榮光’ ‘Hamgyongnam-do’ ‘咸鏡南道’ ‘CITE’ ‘40.01833’ ‘127.45472’ ‘Yodok”耀德’ ‘Hamgyongnam-do’ ‘咸鏡南道’ ‘CITE’ ‘39.612854’ ‘126.843688’ REM ‘Yodeok’ ‘耀德’ ‘Hamgyongnam-do’ ‘咸鏡南道’ ‘CITE’ ‘39.612854’ ‘126.843688’ ‘Sudong’ ‘水洞’ ‘Hamgyongnam-do’ ‘咸鏡南道’ ‘FORT’ ‘39.408889’ ‘126.919167’ ‘Yuktae-dong’ ‘裕泰洞’ ‘Hamgyongnam-do’ ‘咸鏡南道’ ‘FORT’ ‘40.024719’ ‘128.159714’ ‘Hungnam’ ‘興南’ ‘Hamgyongnam-do’ ‘咸鏡南道’ ‘FORT’ ‘39.861118’ ‘127.679632’ ‘Sinsang-ni’ ‘新上里’ ‘Hamgyongnam-do’ ‘咸鏡南道’ ‘FORT’ ‘39.65028’ ‘127.40583’ ‘Samho-rodongjagu’ ‘三湖勞動者區’ ‘Hamgyongnam-do’ ‘咸鏡南道’ ‘FORT’ ‘39.947498’ ‘127.871109’ |
| ‘Chongjin’ ‘清津’ ‘Hamgyongbuk-do’ ‘咸鏡北道’ ‘FORT’ ‘41.767173’ ‘129.723373’
REM ‘Cheongjin”清津’ ‘Hamgyongbuk-do’ ‘咸鏡北道’ ‘FORT’ ‘41.795559’ ‘129.775833’ ‘Kimchaek’ ‘金策’ ‘Hamgyongbuk-do’ ‘咸鏡北道’ ‘FORT’ ‘40.668162’ ‘129.190269’ REM ‘Gimchaek’ ‘金策’ ‘Hamgyongbuk-do’ ‘咸鏡北道’ ‘FORT’ ‘40.668162’ ‘129.190269’ ‘Hoeryong’ ‘會寧’ ‘Hamgyongbuk-do’ ‘咸鏡北道’ ‘FORT’ ‘42.44278’ ‘129.750824’ REM ‘Hoiryong’ ‘會寧’ ‘Hamgyongbuk-do’ ‘咸鏡北道’ ‘FORT’ ‘42.433333’ ‘129.750000’ ‘Kyongsong”鏡城’ ‘Hamgyongbuk-do’ ‘咸鏡北道’ ‘FORT’ ‘41.587186’ ‘129.605306’ REM ‘Gyeongseong’ ‘鏡城’ ‘Hamgyongbuk-do’ ‘咸鏡北道’ ‘FORT’ ‘41.58778’ ‘129.60611’ ‘Kilju’ ‘吉州’ ‘Hamgyongbuk-do’ ‘咸鏡北道’ ‘FORT’ ‘40.964169’ ‘129.327774’ REM ‘Gilju’ ‘吉州’ ‘Hamgyongbuk-do’ ‘咸鏡北道’ ‘FORT’ ‘40.964169’ ‘129.327774’ ‘Myongchon”明川’ ‘Hamgyongbuk-do’ ‘咸鏡北道’ ‘FORT’ ‘41.069167’ ‘129.431944’ REM ‘Myeongcheon’ ‘明川’ ‘Hamgyongbuk-do’ ‘咸鏡北道’ ‘FORT’ ‘41.069167’ ‘129.431944’ ‘Musan-up’ ‘茂山’ ‘Hamgyongbuk-do’ ‘咸鏡北道’ ‘CITE’ ‘42.226089’ ‘129.207764’ REM ‘Musan’ ‘茂山’ ‘Hamgyongbuk-do’ ‘咸鏡北道’ ‘CITE’ ‘42.228435’ ‘129.214319’ REM ‘Rason’ ‘羅先’ ‘Hamgyongbuk-do’ ‘咸鏡北道’ ‘FORT’ ‘42.34’ ‘130.38’ REM ‘Raseon”羅先’ ‘Hamgyongbuk-do’ ‘咸鏡北道’ ‘FORT’ ‘42.34’ ‘130.38’ ‘Rajin’ ‘羅津’ ‘Hamgyongbuk-do’ ‘咸鏡北道’ ‘FORT’ ‘42.256809’ ‘130.297713’ REM ‘Najin’ ‘羅津’ ‘Hamgyongbuk-do’ ‘咸鏡北道’ ‘FORT’ ‘42.24889’ ‘130.300278’ ‘Sonbong’ ‘先鋒’ ‘Hamgyongbuk-do’ ‘咸鏡北道’ ‘FORT’ ‘42.34222’ ‘130.396667’ REM ‘Seonbong’ ‘先鋒’ ‘Hamgyongbuk-do’ ‘咸鏡北道’ ‘FORT’ ‘42.34222’ ‘130.396667’ REM ‘Senbong’ ‘先鋒’ ‘Hamgyongbuk-do’ ‘咸鏡北道’ ‘FORT’ ‘42.3’ ‘130.4’ ‘Aoji-ri”奧地里’ ‘Hamgyongbuk-do’ ‘咸鏡北道’ ‘FORT’ ‘42.520561’ ‘130.395279’ ‘Ungsang-nodongjagu’ ‘雄尚勞動者區’ ‘Hamgyongbuk-do’ ‘咸鏡北道’ ‘42.35778’ ‘130.462219’ ‘Hau-ri’ ‘下里’ ‘Hamgyongbuk-do’ ‘咸鏡北道’ ‘FORT’ ‘41.200562’ ‘129.470276’ ‘Hoemul-li”會物里’ ‘Hamgyongbuk-do’ ‘咸鏡北道’ ‘FORT’ ‘41.433891’ ‘129.669998’ ‘Komusan 1-tong’ ‘古茂山壹洞’ ‘Hamgyongbuk-do’ ‘咸鏡北道’ ‘FORT’ ‘42.109169’ ‘129.699997’ ‘Sungam-nodongjagu’ ‘勝岩勞動者區’ ‘Hamgyongbuk-do’ ‘咸鏡北道’ ‘FORT’ ‘41.66972’ ‘129.668884’ ‘Kyongwon’ ‘慶源’ ‘Hamgyongbuk-do’ ‘咸鏡北道’ ‘CITE’ ‘42.859912’ ‘130.199391’ REM ‘Kyongwon’ ‘新星’ ‘Hamgyongbuk-do’ ‘咸鏡北道’ ‘CITE’ ‘42.859912’ ‘130.199391’ ‘Namyang-dong’ ‘南陽洞’ ‘Hamgyongbuk-do’ ‘咸鏡北道’ ‘FORT’ ‘42.950001’ ‘129.866669’ ‘Nanam”羅南’ ‘Hamgyongbuk-do’ ‘咸鏡北道’ ‘FORT’ ‘41.713612’ ‘129.684433’ ‘Onsong’ ‘穩城’ ‘Hamgyongbuk-do’ ‘咸鏡北道’ ‘FORT’ ‘42.957218’ ‘129.993332’ ‘Puryong’ ‘富寧’ ‘Hamgyongbuk-do’ ‘咸鏡北道’ ‘FORT’ ‘42.060558’ ‘129.71167’ |
| ‘Kaesong’ ‘開城”Hwanghaebuk-do’ ‘黃海北道’ ‘CITE’ ‘37.971667’ ‘126.552778’
‘Sariwon’ ‘沙里院’ ‘Hwanghaebuk-do’ ‘黃海北道’ ‘CITE’ ‘38.507221’ ‘125.755829’ ‘Songnim’ ‘松林”Hwanghaebuk-do’ ‘黃海北道’ ‘CITE’ ‘38.754169’ ‘125.644997’ ‘Koksan”谷山”Hwanghaebuk-do’ ‘黃海北道’ ‘CITE’ ‘38.78194’ ‘126.666389’ REM ‘Goksan”谷山”Hwanghaebuk-do’ ‘黃海北道’ ‘CITE’ ‘38.785000’ ‘126.668056’ ‘Kumchon’ ‘金川”Hwanghaebuk-do’ ‘黃海北道’ ‘FORT’ ‘38.161111’ ‘126.476111’ REM ‘Geumcheon”金川”Hwanghaebuk-do’ ‘黃海北道’ ‘FORT’ ‘38.161111’ ‘126.476111’ ‘Rinsan”麟山”Hwanghaebuk-do’ ‘黃海北道’ ‘FORT’ ‘38.277500’ ‘126.094722’ ‘Pongsan’ ‘鳳山”Hwanghaebuk-do’ ‘黃海北道’ ‘CITE’ ‘38.467868’ ‘125.861673’ REM ‘Bongsan’ ‘鳳山”Hwanghaebuk-do’ ‘黃海北道’ ‘CITE’ ‘38.467868’ ‘125.861673’ ‘Sŏhŭng”瑞興”Hwanghaebuk-do’ ‘黃海北道’ ‘FORT’ ‘38.426697’ ‘126.167979’ REM ‘Seoheung’ ‘瑞興”Hwanghaebuk-do’ ‘黃海北道’ ‘FORT’ ‘38.426697’ ‘126.167979’ ‘Suan’ ‘遂安”Hwanghaebuk-do’ ‘黃海北道’ ‘FORT’ ‘38.778659’ ‘126.356489’ ‘Singye”新溪”Hwanghaebuk-do’ ‘黃海北道’ ‘FORT’ ‘38.505528’ ‘126.531981’ REM ‘Sinpyeong”新坪”Hwanghaebuk-do’ ‘黃海北道’ ‘FORT’ ‘38.868167’ ‘126.721191’ ‘Tosan’ ‘兔山”Hwanghaebuk-do’ ‘黃海北道’ ‘FORT’ ‘38.284444’ ‘126.738611’ ‘Phyongsan”平山”Hwanghaebuk-do’ ‘黃海北道’ ‘FORT’ ‘38.329080’ ‘126.409195’ ‘Hwangju’ ‘黃州”Hwanghaebuk-do’ ‘黃海北道’ ‘FORT’ ‘38.670782’ ‘125.776091’ ‘Hwangju-up’ ‘黃州邑’ ‘Hwanghaebuk-do’ ‘黃海北道’ ‘FORT’ ‘38.67028’ ‘125.776108’ ‘Yonsan”延山”Hwanghaebuk-do’ ‘黃海北道’ ‘FORT’ ‘41.903488’ ‘129.008341’ REM ‘Yeonsan’ ‘延山”Hwanghaebuk-do’ ‘黃海北道’ ‘FORT’ ‘41.903488’ ‘129.008341’ ‘Yonthan’ ‘燕灘”Hwanghaebuk-do’ ‘黃海北道’ ‘FORT’ ‘38.625797’ ‘125.978401’ REM ‘Yeontan’ ‘燕灘”Hwanghaebuk-do’ ‘黃海北道’ ‘FORT’ ‘38.625797’ ‘125.978401’ ‘Unpha’ ‘銀波”Hwanghaebuk-do’ ‘黃海北道’ ‘FORT’ ‘38.407796’ ‘125.791156’ REM ‘Eunpa’ ‘銀波”Hwanghaebuk-do’ ‘黃海北道’ ‘FORT’ ‘38.407796’ ‘125.791156’ ‘Chunghwa’ ‘中和”Hwanghaebuk-do’ ‘黃海北道’ ‘FORT’ ‘38.863892’ ‘125.800003’ REM ‘Junghwa’ ‘中和”Hwanghaebuk-do’ ‘黃海北道’ ‘FORT’ ‘38.863892’ ‘125.800003’ ‘Sangwon’ ‘祥原”Hwanghaebuk-do’ ‘黃海北道’ ‘FORT’ ‘38.860278’ ‘126.070833’ ‘Sungho”勝湖”Hwanghaebuk-do’ ‘黃海北道’ ‘FORT’ ‘38.992429’ ‘125.977907’ REM ‘Seungho’ ‘勝湖’ ‘Hwanghaebuk-do’ ‘黃海北道’ ‘FORT’ ‘38.99139’ ‘125.977783’ ‘Sungho 1-tong’ ‘勝湖一洞’ ‘Hwanghaebuk-do’ ‘黃海北道’ ‘FORT’ ‘38.99139’ ‘125.977783’ ‘Hukkyo-ri”黑橋里’ ‘Hwanghaebuk-do’ ‘黃海北道’ ‘FORT’ ‘38.798611’ ‘125.791939’ ‘Sinmak”新幕”Hwanghaebuk-do’ ‘黃海北道’ ‘FORT’ ‘38.421770’ ‘126.233269’ |
| ‘Haeju’ ‘海州”Hwanghaenam-do’ ‘黃海南道’ ‘CITE’ ‘38.037648’ ‘125.707906’
‘Kangnyong”康翎”Hwanghaenam-do’ ‘黃海南道’ ‘CITE’ ‘37.902002’ ‘125.510950’ REM ‘Gangnyeong’ ‘康翎”Hwanghaenam-do’ ‘黃海南道’ ‘CITE’ ‘37.902002’ ‘125.510950’ ‘Kwail’ ‘瓜飴”Hwanghaenam-do’ ‘黃海南道’ ‘FORT’ ‘38.394516’ ‘124.972769’ REM ‘Gwail’ ‘果實”Hwanghaenam-do’ ‘黃海南道’ ‘FORT’ ‘38.394516’ ‘124.972769’ ‘Ryongyon’ ‘龍淵”Hwanghaenam-do’ ‘黃海南道’ ‘FORT’ ‘38.150000’ ‘124.883333’ REM ‘Ryongyeon”龍淵”Hwanghaenam-do’ ‘黃海南道’ ‘FORT’ ‘38.2”124.9’ ‘Pyoksong’ ‘碧城”Hwanghaenam-do’ ‘黃海南道’ ‘FORT’ ‘38.047761’ ‘125.552154’ REM ‘Byeokseong’ ‘碧城”Hwanghaenam-do’ ‘黃海南道’ ‘FORT’ ‘38.047761’ ‘125.552154’ ‘Pongchon’ ‘峯泉”Hwanghaenam-do’ ‘黃海南道’ ‘FORT’ ‘39.115726’ ‘127.624034’ REM ‘Bongcheon”峯泉”Hwanghaenam-do’ ‘黃海南道’ ‘FORT’ ‘39.115726’ ‘127.624034’ ‘Paechon’ ‘白川”Hwanghaenam-do’ ‘黃海南道’ ‘CITE’ ‘37.983419’ ‘126.300019’ REM ‘Baecheon’ ‘白川”Hwanghaenam-do’ ‘黃海南道’ ‘CITE’ ‘37.983419’ ‘126.300019’ ‘Samchon’ ‘三泉”Hwanghaenam-do’ ‘黃海南道’ ‘FORT’ ‘38.340556’ ‘125.294444’ REM ‘Samcheon’ ‘三泉”Hwanghaenam-do’ ‘黃海南道’ ‘FORT’ ‘38.340556’ ‘125.294444’ ‘Songhwa’ ‘松禾”Hwanghaenam-do’ ‘黃海南道’ ‘FORT’ ‘38.357777’ ‘125.139290’ ‘Sinchon’ ‘信川”Hwanghaenam-do’ ‘黃海南道’ ‘FORT’ ‘38.354882’ ‘125.480990’ REM ‘Sincheon’ ‘信川”Hwanghaenam-do’ ‘黃海南道’ ‘FORT’ ‘38.354882’ ‘125.480990’ ‘Sinwon”新院”Hwanghaenam-do’ ‘黃海南道’ ‘FORT’ ‘38.216573’ ‘125.720208’ ‘Changyon’ ‘長淵”Hwanghaenam-do’ ‘黃海南道’ ‘FORT’ ‘38.250832’ ‘125.096107’ REM ‘Jangyon’ ‘長淵”Hwanghaenam-do’ ‘黃海南道’ ‘FORT’ ‘38.250832’ ‘125.096107’ REM ‘Jangyeon’ ‘長淵”Hwanghaenam-do’ ‘黃海南道’ ‘FORT’ ‘38.250832’ ‘125.096107’ ‘Jaeryeong”載寧”Hwanghaenam-do’ ‘黃海南道’ ‘CITE’ ‘38.39917’ ‘125.615562’ REM ‘Chaeryong-up’ ‘載寧”Hwanghaenam-do’ ‘黃海南道’ ‘CITE’ ‘38.39917’ ‘125.615562’ ‘Chongdan’ ‘青丹”Hwanghaenam-do’ ‘黃海南道’ ‘CITE’ ‘37.972799’ ‘125.940236’ REM ‘Cheongdan”青丹”Hwanghaenam-do’ ‘黃海南道’ ‘CITE’ ‘37.972799’ ‘125.940236’ ‘Thaethan’ ‘苔灘”Hwanghaenam-do’ ‘黃海南道’ ‘CITE’ ‘38.088600’ ‘125.300027’ ‘Anak’ ‘安岳”Hwanghaenam-do’ ‘黃海南道’ ‘CITE’ ‘38.504903’ ‘125.494079’ ‘Yonan’ ‘延安”Hwanghaenam-do’ ‘黃海南道’ ‘CITE’ ‘37.901934’ ‘126.159947’ REM ‘Yeonan”延安”Hwanghaenam-do’ ‘黃海南道’ ‘CITE’ ‘37.901934’ ‘126.159947’ REM ‘Yonan-up’ ‘延安郡’ ‘Hwanghaenam-do’ ‘黃海南道’ ‘CITE’ ‘37.90889’ ‘126.16111’ ‘Ongjin”甕津”Hwanghaenam-do’ ‘黃海南道’ ‘CITE’ ‘37.934719’ ‘125.361938’ ‘Unnyul”殷栗”Hwanghaenam-do’ ‘黃海南道’ ‘CITE’ ‘38.507360’ ‘125.195564’ REM ‘Eunnyul’ ‘殷栗”Hwanghaenam-do’ ‘黃海南道’ ‘CITE’ ‘38.507360’ ‘125.195564’ ‘Unchon”銀泉”Hwanghaenam-do’ ‘黃海南道’ ‘FORT’ ‘38.621944’ ‘125.454722’ REM ‘Euncheon’ ‘銀泉”Hwanghaenam-do’ ‘黃海南道’ ‘FORT’ ‘38.621944’ ‘125.454722’ ‘Ayang-ni’ ‘雅陽里’ ‘Hwanghaenam-do’ ‘黃海南道’ ‘FORT’ ‘38.233975’ ‘125.768078’ ‘Pyoksong-up’ ‘碧城郡’ ‘Hwanghaenam-do’ ‘黃海南道’ ‘FORT’ ‘38.047501’ ‘125.556671’ |
| ‘Kanggye’ ‘江界’ ‘Chagang-do’ ‘慈江道’ ‘CITE’ ‘40.96946’ ‘126.585228’
REM ‘Kanggye’ ‘江界’ ‘Chagang-do’ ‘慈江道’ ‘CITE’ ’41”126.6′ REM ‘Kanggye-si’ ‘江界市”Chagang-do’ ‘慈江道’ ‘CITE’ ‘40.96946’ ‘126.585228’ ‘Manpho”滿浦’ ‘Chagang-do’ ‘慈江道’ ‘CITE’ ‘41.154518’ ‘126.287321’ ‘Huichon’ ‘熙川’ ‘Chagang-do’ ‘慈江道’ ‘CITE’ ‘40.172586’ ‘126.277561’ ‘Kophung’ ‘古豐’ ‘Chagang-do’ ‘慈江道’ ‘FORT’ ‘40.602211’ ‘125.945412’ REM ‘Gopung”古豐’ ‘Chagang-do’ ‘慈江道’ ‘FORT’ ‘40.602211’ ‘125.945412’ ‘Tongsin’ ‘東新’ ‘Chagang-do’ ‘慈江道’ ‘FORT’ ‘40.308333’ ‘126.306111’ REM ‘Dongsin’ ‘東新’ ‘Chagang-do’ ‘慈江道’ ‘FORT’ ‘40.308333’ ‘126.306111’ ‘Rangnim’ ‘狼林’ ‘Chagang-do’ ‘慈江道’ ‘FORT’ ‘40.971140’ ‘127.129906’ ‘Ryongnim’ ‘龍林’ ‘Chagang-do’ ‘慈江道’ ‘FORT’ ‘40.551122’ ‘126.648181’ ‘Songgan’ ‘城干’ ‘Chagang-do’ ‘慈江道’ ‘FORT’ ‘40.787778’ ‘126.564444’ REM ‘Seonggan’ ‘城干’ ‘Chagang-do’ ‘慈江道’ ‘FORT’ ‘40.789762’ ‘126.569833’ ‘Songwon’ ‘松源’ ‘Chagang-do’ ‘慈江道’ ‘FORT’ ‘40.371111’ ‘126.300278’ ‘Sijung”時中’ ‘Chagang-do’ ‘慈江道’ ‘FORT’ ‘41.079410’ ‘126.386948’ ‘Chasong’ ‘慈城’ ‘Chagang-do’ ‘慈江道’ ‘FORT’ ‘41.462214’ ‘126.646659’ REM ‘Jasong”慈城’ ‘Chagang-do’ ‘慈江道’ ‘FORT’ ‘41.462214’ ‘126.646659’ REM ‘Jaseong’ ‘慈城’ ‘Chagang-do’ ‘慈江道’ ‘FORT’ ‘41.462214’ ‘126.646659’ ‘Janggang’ ‘長江’ ‘Chagang-do’ ‘慈江道’ ‘FORT’ ‘41.058889’ ‘126.668889’ REM ‘Changgang”長江’ ‘Chagang-do’ ‘慈江道’ ‘FORT’ ‘41.058889’ ‘126.668889’ ‘Jonchon’ ‘前川’ ‘Chagang-do’ ‘慈江道’ ‘FORT’ ‘40.615556’ ‘126.463056’ REM ‘Jeoncheon”前川’ ‘Chagang-do’ ‘慈江道’ ‘FORT’ ‘40.615556’ ‘126.463056’ REM ‘Chonchon’ ‘前川’ ‘Chagang-do’ ‘慈江道’ ‘FORT’ ‘40.615556’ ‘126.463056’ ‘Chunggang”中江’ ‘Chagang-do’ ‘慈江道’ ‘FORT’ ‘41.773768’ ‘126.874439’ REM ‘Junggang’ ‘中江’ ‘Chagang-do’ ‘慈江道’ ‘FORT’ ‘41.8’ ‘126.9’ ‘Chosan”楚山’ ‘Chagang-do’ ‘慈江道’ ‘FORT’ ‘40.831111’ ‘125.805278’ ‘Hwapyong’ ‘和坪’ ‘Chagang-do’ ‘慈江道’ ‘FORT’ ‘41.262539’ ‘126.899209’ REM ‘Hwapyeong”和坪’ ‘Chagang-do’ ‘慈江道’ ‘FORT’ ‘41.262539’ ‘126.899209’ ‘Usi”雩時’ ‘Chagang-do’ ‘慈江道’ ‘FORT’ ‘40.678889’ ‘125.668889’ ‘Wiwon’ ‘渭原’ ‘Chagang-do’ ‘慈江道’ ‘FORT’ ‘40.898333’ ‘125.968889’ ‘Hyangsan’ ‘香山’ ‘Chagang-do’ ‘慈江道’ ‘FORT’ ‘40.040779’ ‘126.175386’ |
| ‘Hyesan’ ‘惠山”Ryanggang-do’ ‘兩江道’ ‘CITE’ ‘41.400000’ ‘128.183333’
‘Hyesan-dong”惠山洞’ ‘Ryanggang-do’ ‘兩江道’ ‘FORT’ ‘41.39756’ ‘128.178726’ ‘Samjiyon”三池淵’ ‘Ryanggang-do’ ‘兩江道’ ‘CITE’ ‘41.800000’ ‘128.316667’ REM ‘Samjiyeon’ ‘三池淵’ ‘Ryanggang-do’ ‘兩江道’ ‘CITE’ ‘41.8”128.3’ ‘Kapsan-up’ ‘甲山’ ‘Ryanggang-do’ ‘兩江道’ ‘FORT’ ‘41.090279’ ‘128.293335’ REM ‘Gapsan’ ‘甲山’ ‘Ryanggang-do’ ‘兩江道’ ‘FORT’ ‘41.090279’ ‘128.293335’ ‘Kimjongsuk’ ‘新坡金正淑’ ‘Ryanggang-do’ ‘兩江道’ ‘FORT’ ‘41.420278’ ‘127.775278’ REM ‘Gimjeongsuk”新坡金正淑’ ‘Ryanggang-do’ ‘兩江道’ ‘FORT’ ‘41.420278’ ‘127.775278’ ‘Pungsan’ ‘豐山’ ‘Ryanggang-do’ ‘兩江道’ ‘FORT’ ‘40.818057’ ‘128.162467’ REM ‘Kimhyonggwon’ ‘金亨權’ ‘Ryanggang-do’ ‘兩江道’ ‘FORT’ ‘40.817553’ ‘128.162036’ REM ‘Gimhyeonggwon’ ‘金亨權’ ‘Ryanggang-do’ ‘兩江道’ ‘FORT’ ‘40.817553’ ‘128.162036’ ‘Kimhyongjik”厚昌金亨稷’ ‘Ryanggang-do’ ‘兩江道’ ‘FORT’ ‘41.506944’ ‘127.268333’ REM ‘Gimhyeongjik’ ‘厚昌金亨稷’ ‘Ryanggang-do’ ‘兩江道’ ‘FORT’ ‘41.506944’ ‘127.268333’ ‘Taehongdan’ ‘大紅湍’ ‘Ryanggang-do’ ‘兩江道’ ‘FORT’ ‘42.001111’ ‘128.851389’ REM ‘Daehongdan’ ‘大紅湍’ ‘Ryanggang-do’ ‘兩江道’ ‘FORT’ ‘42.001111’ ‘128.851389’ ‘Pochon’ ‘普天’ ‘Ryanggang-do’ ‘兩江道’ ‘FORT’ ‘41.523825’ ‘128.303476’ REM ‘Bocheon’ ‘普天’ ‘Ryanggang-do’ ‘兩江道’ ‘FORT’ ‘41.523825’ ‘128.303476’ ‘Paegam’ ‘白岩’ ‘Ryanggang-do’ ‘兩江道’ ‘FORT’ ‘41.567500’ ‘128.811667’ REM ‘Baegam’ ‘白岩’ ‘Ryanggang-do’ ‘兩江道’ ‘FORT’ ‘41.567500’ ‘128.811667’ ‘Samsu”三水’ ‘Ryanggang-do’ ‘兩江道’ ‘FORT’ ‘41.289517’ ‘128.024286’ ‘Pungso’ ‘豐西’ ‘Ryanggang-do’ ‘兩江道’ ‘FORT’ ‘43.003453’ ‘129.928023’ REM ‘Phungso’ ‘豐西’ ‘Ryanggang-do’ ‘兩江道’ ‘FORT’ ‘43.003453’ ‘129.928023’ REM ‘Pungseo’ ‘豐西’ ‘Ryanggang-do’ ‘兩江道’ ‘FORT’ ‘43.003453’ ‘129.928023’ ‘Unhung’ ‘雲興’ ‘Ryanggang-do’ ‘兩江道’ ‘FORT’ ‘41.304722’ ‘128.501667’ REM ‘Unheung’ ‘雲興’ ‘Ryanggang-do’ ‘兩江道’ ‘FORT’ ‘41.304722’ ‘128.501667’ ‘Sungjibaegam’ ‘承旨白巖’ ‘Ryanggang-do’ ‘兩江道’ ‘FORT’ ‘41.242779’ ‘128.798889’
|
| ‘Wonsan’ ‘元山’ ‘Gangwon-do’ ‘江原道’ ‘CITE’ ‘39.152779’ ‘127.443611’
‘Muncheon’ ‘文川’ ‘Gangwon-do’ ‘江原道’ ‘CITE’ ‘39.258889’ ‘127.356111’ REM ‘Munchon’ ‘文川’ ‘Gangwon-do’ ‘江原道’ ‘CITE’ ‘39.258889’ ‘127.356111’ ‘Anbyeon”安邊’ ‘Gangwon-do’ ‘江原道’ ‘FORT’ ‘39.043333’ ‘127.525278’ REM ‘Anbyon-up’ ‘安邊’ ‘Gangwon-do’ ‘江原道’ ‘FORT’ ‘39.0425”127.523888’ ‘Pangyo’ ‘板橋’ ‘Gangwon-do’ ‘江原道’ ‘FORT’ ‘38.751944’ ‘127.001944’ REM ‘Phangyo”板橋’ ‘Gangwon-do’ ‘江原道’ ‘FORT’ ‘38.751944’ ‘127.001944’ ‘Changdo”昌道’ ‘Gangwon-do’ ‘江原道’ ‘FORT’ ‘38.650241’ ‘127.712789’ ‘Chonnae”川內’ ‘Gangwon-do’ ‘江原道’ ‘FORT’ ‘39.365411’ ‘127.215748’ REM ‘Cheonnae’ ‘川內’ ‘Gangwon-do’ ‘江原道’ ‘FORT’ ‘39.365411’ ‘127.215748’ ‘Poptong”法洞’ ‘Gangwon-do’ ‘江原道’ ‘FORT’ ‘38.975777’ ‘127.082886’ REM ‘Beopdong”法洞’ ‘Gangwon-do’ ‘江原道’ ‘FORT’ ‘38.975777’ ‘127.082886’ ‘Hoeyang”淮陽’ ‘Gangwon-do’ ‘江原道’ ‘FORT’ ‘38.715027’ ‘127.601502’ REM ‘Hoiyang”淮陽’ ‘Gangwon-do’ ‘江原道’ ‘FORT’ ‘38.710281’ ‘127.598328’ ‘Kosan’ ‘高山’ ‘Gangwon-do’ ‘江原道’ ‘CITE’ ‘38.855831’ ‘127.41806’ REM ‘Gosan’ ‘高山’ ‘Gangwon-do’ ‘江原道’ ‘CITE’ ‘38.855831’ ‘127.41806’ ‘Kosong’ ‘高城’ ‘Gangwon-do’ ‘江原道’ ‘FORT’ ‘38.670234’ ‘128.322194’ REM ‘Goseong’ ‘高城’ ‘Gangwon-do’ ‘江原道’ ‘FORT’ ‘38.670234’ ‘128.322194’ ‘Kumgang’ ‘金剛’ ‘Gangwon-do’ ‘江原道’ ‘CITE’ ‘38.623790’ ‘127.988103’ ‘Kimhwa’ ‘金化’ ‘Gangwon-do’ ‘江原道’ ‘CITE’ ‘38.420556’ ‘127.594444’ REM ‘Gimhwa’ ‘金化’ ‘Gangwon-do’ ‘江原道’ ‘CITE’ ‘38.420556’ ‘127.594444’ ‘Pyonggang’ ‘平康’ ‘Gangwon-do’ ‘江原道’ ‘CITE’ ‘38.416667’ ‘127.288889’ REM ‘Phyonggang’ ‘平康’ ‘Gangwon-do’ ‘江原道’ ‘CITE’ ‘38.4”127.3’ REM ‘Pyeonggang’ ‘平康’ ‘Gangwon-do’ ‘江原道’ ‘CITE’ ‘38.4”127.3’ ‘Chorwon’ ‘鐵原’ ‘Gangwon-do’ ‘江原道’ ‘FORT’ ‘38.344222’ ‘126.907069’ ‘Cheorwon”鐵原’ ‘Gangwon-do’ ‘江原道’ ‘FORT’ ‘38.344222’ ‘126.907069’ ‘Tongchon”通川’ ‘Gangwon-do’ ‘江原道’ ‘FORT’ ‘38.935697’ ‘127.879846’ REM ‘Tongcheon’ ‘通川’ ‘Gangwon-do’ ‘江原道’ ‘FORT’ ‘38.935697’ ‘127.879846’ REM ‘Thongchon’ ‘通川’ ‘Gangwon-do’ ‘江原道’ ‘FORT’ ‘38.935697’ ‘127.879846’ ‘Tongchon-up”通川邑’ ‘Gangwon-do’ ‘江原道’ ‘FORT’ ‘38.953892’ ‘127.89167’ ‘Sepo’ ‘洗浦’ ‘Gangwon-do’ ‘江原道’ ‘CITE’ ‘38.642500’ ‘127.358611’ REM ‘Sepho”洗浦’ ‘Gangwon-do’ ‘江原道’ ‘CITE’ ‘38.642500’ ‘127.358611’ ‘Ichon’ ‘伊川’ ‘Gangwon-do’ ‘江原道’ ‘CITE’ ‘38.508056’ ‘126.871944’ REM ‘Icheon’ ‘伊川’ ‘Gangwon-do’ ‘江原道’ ‘CITE’ ‘38.508056’ ‘126.871944’
|
| ‘Kaesong’ ‘開城’ ‘Gyeonggido’ ‘京畿道’ ‘CAPITAL’ ‘37.970829’ ‘126.554443’
REM ‘Gaeseong”開城’ ‘Gyeonggido’ ‘京畿道’ ‘CAPITAL’ ‘37.971667’ ‘126.552778’ |
韓國城市數據 (人口過壹萬), 韓國劃分八『道』類似『州』.
係『道』以下以常住人劃分『特別市』『特例市』『大都市』『市』『郡』.
係『市』『郡』以下劃分『區』.
係『區』以下劃分『洞』『邑』『面』類似『邨』.
係『洞』『邑』『面』 以下劃分『統』『里』.
係『統』『里』以下劃分『班』, 『班』係基層組織.
城市數據分9類.
| 市英文 | 市漢字 | 道英文 | 道漢字 | 國英文 | 國漢字 | 分類 | 經度 | 緯度 |
下列係韓國城市數據庫
| ‘Seoul’ ‘首爾’ ‘Gyeonggido’ ‘京畿道’ ‘CAPITAL’ ‘37.56826’ ‘126.977829’
‘Incheon’ ‘仁川’ ‘Gyeonggido’ ‘京畿道’ ‘CAPITAL’ ‘37.453609’ ‘126.731667’ ‘Ansan’ ‘安山’ ‘Gyeonggido’ ‘京畿道’ ‘CITE’ ‘37.323608’ ‘126.821938’ ‘Anseong’ ‘安城’ ‘Gyeonggido’ ‘京畿道’ ‘CITE’ ‘37.01083’ ‘127.270279’ ‘Anyang’ ‘安養’ ‘Gyeonggido’ ‘京畿道’ ‘CITE’ ‘37.392502’ ‘126.926941’ ‘Bucheon’ ‘富川’ ‘Gyeonggido’ ‘京畿道’ ‘CITE’ ‘37.49889’ ‘126.783058’ ‘Suwon’ ‘水原’ ‘Gyeonggido’ ‘京畿道’ ‘CAPITAL’ ‘37.285833’ ‘127.010000’ REM ‘Suigen’ ‘水原’ ‘Gyeonggido’ ‘京畿道’ ‘CAPITAL’ ‘37.291111’ ‘127.008888’ ‘Uijeongbu’ ‘議政府’ ‘Gyeonggido’ ‘京畿道’ ‘CITE’ ‘37.748611’ ‘127.038889’ REM ‘Vijongbu’ ‘議政府’ ‘Gyeonggido’ ‘京畿道’ ‘CITE’ ‘37.741501’ ‘127.047401’ ‘Goyang’ ‘高陽’ ‘Gyeonggido’ ‘京畿道’ ‘CAPITAL’ ‘37.656391’ ‘126.834999’ ‘Yongin’ ‘龍仁’ ‘Gyeonggido’ ‘京畿道’ ‘CAPITAL’ ‘37.236111’ ‘127.201111’ ‘Hwaseong’ ‘華城’ ‘Gyeonggido’ ‘京畿道’ ‘CAPITAL’ ‘37.206821’ ‘126.816902’ ‘Seongnam’ ‘城南’ ‘Gyeonggido’ ‘京畿道’ ‘CAPITAL’ ‘37.43861’ ‘127.137779’ ‘Namyangju’ ‘南楊州’ ‘Gyeonggido’ ‘京畿道’ ‘CITE’ ‘37.636667’ ‘127.214167’ ‘Pyeongtaek’ ‘平澤’ ‘Gyeonggido’ ‘京畿道’ ‘CITE’ ‘36.994722’ ‘127.088889’ ‘Siheung’ ‘始興’ ‘Gyeonggido’ ‘京畿道’ ‘CITE’ ‘37.380278’ ‘126.803056’ ‘Gimpo’ ‘金浦’ ‘Gyeonggido’ ‘京畿道’ ‘CITE’ ‘37.623611’ ‘126.714167’ ‘Gwangmyeong’ ‘光明’ ‘Gyeonggido’ ‘京畿道’ ‘CITE’ ‘37.477222’ ‘126.866389’ REM ‘Kwangmyong’ ‘光明’ ‘Gyeonggido’ ‘京畿道 ‘ ‘CITE’ ‘37.477219’ ‘126.866386’ ‘Paju’ ‘坡州’ ‘Gyeonggido’ ‘京畿道’ ‘CITE’ ‘37.832778’ ‘126.816944’ ‘Gunpo’ ‘軍浦’ ‘Gyeonggido’ ‘京畿道’ ‘CITE’ ‘37.367500’ ‘126.946944’ ‘Gwangju’ ‘廣州’ ‘Gyeonggido’ ‘京畿道’ ‘CITE’ ‘35.15472’ ‘126.915558’ ‘Icheon’ ‘利川’ ‘Gyeonggido’ ‘京畿道’ ‘CITE’ ‘37.279167’ ‘127.442500’ REM ‘Ichon’ ‘利川’ ‘Gyeonggido’ ‘京畿道’ ‘FORT’ ‘37.279171’ ‘127.442497’ ‘Yangju’ ‘楊州’ ‘Gyeonggido’ ‘京畿道’ ‘CITE’ ‘37.833111’ ‘127.061691’ ‘Guri’ ‘九里’ ‘Gyeonggido’ ‘京畿道’ ‘CITE’ ‘37.594722’ ‘127.142778’ REM ‘Kuri’ ‘九里’ ‘Gyeonggido’ ‘京畿道’ ‘CITE’ ‘37.598598’ ‘127.139397’ ‘Osan’ ‘烏山’ ‘Gyeonggido’ ‘京畿道’ ‘CITE’ ‘37.152222’ ‘127.070557’ ‘Uiwang’ ‘義王’ ‘Gyeonggido’ ‘京畿道’ ‘CITE’ ‘37.344722’ ‘126.968333’ ‘Pocheon’ ‘抱川’ ‘Gyeonggido’ ‘京畿道’ ‘CITE’ ‘37.894444’ ‘127.199167’ ‘Hanam’ ‘河南’ ‘Gyeonggido’ ‘京畿道’ ‘CITE’ ‘37.540001’ ‘127.205559’ ‘Dongducheon’ ‘東豆川’ ‘Gyeonggido’ ‘京畿道’ ‘FORT’ ‘37.913333’ ‘127.063333’ ‘Gwacheon’ ‘果川’ ‘Gyeonggido’ ‘京畿道’ ‘FORT’ ‘37.428889’ ‘126.989167’ ‘Yeoju’ ‘驪州’ ‘Gyeonggido’ ‘京畿道’ ‘CITE’ ‘37.29583’ ‘127.633888’ ‘Yangpyeong’ ‘楊平’ ‘Gyeonggido’ ‘京畿道’ ‘CITE’ ‘37.489722’ ‘127.490278’ REM ‘Yangpyong’ ‘楊平’ ‘Gyeonggido’ ‘京畿道’ ‘CITE’ ‘37.489719’ ‘127.490562’ ‘Gapyeong’ ‘加平’ ‘Gyeonggido’ ‘京畿道’ ‘FORT’ ‘37.831389’ ‘127.513889’ ‘yeoncheongun’ ‘漣川郡’ ‘Gyeonggido’ ‘京畿道’ ‘FORT’ ‘38.09404’ ‘127.075768’ ‘Hwado’ ‘華道’ ‘Gyeonggido’ ‘京畿道’ ‘FORT’ ‘37.6525’ ‘127.307503’ ‘Kanghwa’ ‘江華’ ‘Gyeonggido’ ‘京畿道’ ‘FORT’ ‘37.747219’ ‘126.485558’ ‘Munsan’ ‘文山’ ‘Gyeonggido’ ‘京畿道’ ‘FORT’ ‘37.85944’ ‘126.785004’ ‘Pubal’ ‘夫鉢’ ‘Gyeonggido’ ‘京畿道’ ‘FORT’ ‘37.291672’ ‘127.507782’ ‘Wabu’ ‘瓦阜’ ‘Gyeonggido’ ‘京畿道’ ‘FORT’ ‘37.589722’ ‘127.220284’ ‘Yanggok’ ‘陽谷’ ‘Gyeonggido’ ‘京畿道’ ‘FORT’ ‘37.636669’ ‘127.214172’ ‘Baengnyeongdo’ ‘白翎島’ ‘Gyeonggido’ ‘京畿道’ ‘FORT’ ‘37.959269’ ‘124.665800’ |
| ‘Wonju’ ‘原州’ ‘Gangwondo’ ‘江原道’ ‘CITE’ ‘37.351391’ ‘127.945282’
‘Chuncheon’ ‘春川’ ‘Gangwondo’ ‘江原道’ ‘CITE’ ‘37.874722’ ‘127.734169’ ‘Gangneung’ ‘江陵’ ‘Gangwondo’ ‘江原道’ ‘CITE’ ‘37.755556’ ‘128.896111’ REM ‘Kang-neung’ ‘江陵’ ‘Gangwondo’ ‘江原道’ ‘FORT’ ‘37.755562’ ‘128.896103’ ‘Tonghae’ ‘東海’ ‘Gangwondo’ ‘江原道’ ‘FORT’ ‘37.543892’ ‘129.106934’ REM ‘Donghae’ ‘東海’ ‘Gangwondo’ ‘江原道’ ‘FORT’ ‘37.7’ ‘127’ ‘Sokcho’ ‘束草’ ‘Gangwondo’ ‘江原道’ ‘FORT’ ‘38.208333’ ‘128.591111’ RAM ‘Sogcho’ ‘束草’ ‘Gangwondo’ ‘江原道’ ‘FORT’ ‘38.208328’ ‘128.59111’ ‘Samcheok’ ‘三陟’ ‘Gangwondo’ ‘江原道’ ‘FORT’ ‘37.440556’ ‘129.170833’ REM ‘Santyoku’ ‘三陟’ ‘Gangwondo’ ‘江原道’ ‘FORT’ ‘37.440559’ ‘129.170837’ ‘Taebaek’ ‘太白’ ‘Gangwondo’ ‘江原道’ ‘FORT’ ‘37.1759’ ‘128.988907’ ‘Hongcheon’ ‘洪川’ ‘Gangwondo’ ‘江原道’ ‘FORT’ ‘37.692500’ ‘127.880000’ REM ‘Hongchon’ ‘洪川’ ‘Gangwondo’ ‘江原道’ ‘FORT’ ‘37.691799’ ‘127.885696’ ‘Cheorwon’ ‘鐵原’ ‘Gangwondo’ ‘江原道’ ‘FORT’ ‘38.209167’ ‘127.217500’ ‘Hoengseong’ ‘橫城’ ‘Gangwondo’ ‘江原道’ ‘FORT’ ‘37.489722’ ‘127.987500’ ‘Pyeongchang’ ‘平昌’ ‘Gangwondo’ ‘江原道’ ‘FORT’ ‘37.368889’ ‘128.390278’ ‘Jeongseon’ ‘旌善’ ‘Gangwondo’ ‘江原道’ ‘FORT’ ‘37.379167’ ‘128.664722’ ‘Yeongwol’ ‘寧越’ ‘Gangwondo’ ‘江原道’ ‘FORT’ ‘37.187222’ ‘128.473333’ ‘Inje’ ‘麟蹄’ ‘Gangwondo’ ‘江原道’ ‘FORT’ ‘38.067500’ ‘128.176944’ ‘Goseong’ ‘高城’ ‘Gangwondo’ ‘江原道’ ‘FORT’ ‘38.380833’ ‘128.469722’ REM ‘Kosong’ ‘高城’ ‘Gangwondo’ ‘江原道’ ‘FORT’ ‘38.378811’ ‘128.467606’ ‘Yangyang’ ‘襄陽’ ‘Gangwondo’ ‘江原道’ ‘FORT’ ‘38.066667’ ‘128.616667’ ‘Hwacheon’ ‘華川’ ‘Gangwondo’ ‘江原道’ ‘FORT’ ‘38.10611’ ‘127.706673’ ‘Yanggu’ ‘楊口’ ‘Gangwondo’ ‘江原道’ ‘FORT’ ‘38.105831’ ‘127.989441’ ‘Neietsu’ ‘寧越’ ‘Gangwondo’ ‘江原道’ ‘FORT’ ‘37.184471’ ‘128.468216’ ‘Daegwallyeong’ ‘大關嶺’ ‘Gangwondo’ ‘江原道’ ‘FORT’ ‘37.687146’ ‘128.760572’ |
| ‘Cheongju’ ‘清州’ ‘Chungcheongbukdo’ ‘忠清北道’ ‘CITE’ ‘36.637218’ ‘127.489723’
‘Chungju’ ‘忠州’ ‘Chungcheongbukdo’ ‘忠清北道’ ‘CITE’ ‘36.970556’ ‘127.932222’ ‘Jecheon’ ‘堤川’ ‘Chungcheongbukdo’ ‘忠清北道’ ‘CITE’ ‘37.136111’ ‘128.211944’ ‘Eumseong’ ‘陰城’ ‘Chungcheongbukdo’ ‘忠清北道’ ‘FORT’ ‘36.935278’ ‘127.689722’ ‘Jincheon’ ‘鎭川’ ‘Chungcheongbukdo’ ‘忠清北道’ ‘FORT’ ‘36.856667’ ‘127.443333’ REM ‘Chinchon’ ‘鎭川’ ‘Chungcheongbukdo’ ‘忠清北道’ ‘FORT’ ‘36.85667’ ‘127.443329’ ‘Okcheon’ ‘沃川’ ‘Chungcheongbukdo’ ‘忠清北道’ ‘FORT’ ‘36.300833’ ‘127.568611’ ‘Yong-dong’ ‘永同’ ‘Chungcheongbukdo’ ‘忠清北道’ ‘FORT’ ‘36.174999’ ‘127.77639’ ‘Goesan’ ‘槐山’ ‘Chungcheongbukdo’ ‘忠清北道’ ‘FORT’ ‘36.810833’ ‘127.794722’ REM ‘Koesan’ ‘槐山’ ‘Chungcheongbukdo’ ‘忠清北道’ ‘FORT’ ‘36.810829’ ‘127.794724’ ‘Jeungpyeong’ ‘曾坪’ ‘Chungcheongbukdo’ ‘忠清北道’ ‘FORT’ ‘36.784722’ ‘127.581944’ ‘Boeun’ ‘報恩’ ‘Chungcheongbukdo’ ‘忠清北道’ ‘FORT’ ‘36.484444’ ‘127.718611’ ‘Danyang’ ‘丹陽’ ‘Chungcheongbukdo’ ‘忠清北道’ ‘FORT’ ‘36.985000’ ‘128.362778’ ‘ogcheongun’ ‘沃川郡’ ‘Chungcheongbukdo’ ‘忠清北道’ ‘FORT’ ‘36.301201’ ‘127.568001’ |
| ‘Cheonan’ ‘天安’ ‘Chungcheongnamdo’ ‘忠清南道’ ‘CITE’ ‘36.810000’ ‘127.147500’
REM ‘Tenan’ ‘天安’ ‘Chungcheongnamdo’ ‘忠清南道’ ‘CITE’ ‘36.806499’ ‘127.152199’ ‘Asan’ ‘牙山’ ‘Chungcheongnamdo’ ‘忠清南道’ ‘CITE’ ‘36.783611’ ‘127.004173’ ‘Seosan’ ‘瑞山’ ‘Chungcheongnamdo’ ‘忠清南道’ ‘CITE’ ‘36.781667’ ‘126.452222’ REM ‘Seosan’ ‘瑞山’ ‘Chungcheongnamdo’ ‘忠清南道’ ‘CITE’ ‘36.8’ ‘126.5’ REM ‘Suisan’ ‘瑞山’ ‘Chungcheongnamdo’ ‘忠清南道’ ‘CITE’ ‘36.78167’ ‘126.452217’ ‘Tangjin’ ‘唐津’ ‘Chungcheongnamdo’ ‘忠清南道’ ‘CITE’ ‘36.89444’ ‘126.629723’ REM ‘Dangjin’ ‘唐津’ ‘Chungcheongnamdo’ ‘忠清南道’ ‘CITE’ ‘36.894444’ ‘126.629722’ ‘Gongju’ ‘公州’ ‘Chungcheongnamdo’ ‘忠清南道’ ‘CITE’ ‘36.455556’ ‘127.124722’ REM ‘Kongju’ ‘公州’ ‘Chungcheongnamdo’ ‘忠清南道’ ‘CITE’ ‘36.455559’ ‘127.124718’ ‘Yonmu’ ‘論山’ ‘Chungcheongnamdo’ ‘忠清南道’ ‘CITE’ ‘36.12944’ ‘127.099998’ REM ‘Nonsan’ ‘論山’ ‘Chungcheongnamdo’ ‘忠清南道’ ‘CITE’ ‘36.203892’ ‘127.084717’ ‘Boryeong’ ‘保寧’ ‘Chungcheongnamdo’ ‘忠清南道’ ‘FORT’ ‘36.333333’ ‘126.616667’ ‘Gyeryong’ ‘鷄龍’ ‘Chungcheongnamdo’ ‘忠清南道’ ‘FORT’ ‘36.274722’ ‘127.248889’ ‘Hongseong’ ‘洪城’ ‘Chungcheongnamdo’ ‘忠清南道’ ‘FORT’ ‘36.599444’ ‘126.662778’ REM ‘Hongsung’ ‘洪城’ ‘Chungcheongnamdo’ ‘忠清南道’ ‘FORT’ ‘36.600899’ ‘126.665001’ ‘Yesan’ ‘禮山’ ‘Chungcheongnamdo’ ‘忠清南道’ ‘FORT’ ‘36.677559’ ‘126.84272’ ‘Buyeo’ ‘扶餘’ ‘Chungcheongnamdo’ ‘忠清南道’ ‘FORT’ ‘36.281944’ ‘126.912500’ REM ‘Fuyo’ ‘扶餘’ ‘Chungcheongnamdo’ ‘忠清南道’ ‘FORT’ ‘36.28194’ ‘126.912498’ ‘Seocheon’ ‘舒川’ ‘Chungcheongnamdo’ ‘忠清南道’ ‘FORT’ ‘36.080278’ ‘126.691389’ ‘Taean’ ‘泰安’ ‘Chungcheongnamdo’ ‘忠清南道’ ‘FORT’ ‘36.756389’ ‘126.297778’ ‘Geumsan’ ‘錦山’ ‘Chungcheongnamdo’ ‘忠清南道’ ‘FORT’ ‘36.103056’ ‘127.488889’ REM ‘Kinzan’ ‘錦山’ ‘Chungcheongnamdo’ ‘忠清南道’ ‘FORT’ ‘36.103062’ ‘127.488892’ ‘Cheongyang’ ‘青陽’ ‘Chungcheongnamdo’ ‘忠清南道’ ‘FORT’ ‘36.451111’ ‘126.804444’ ‘Taesal-li’ ‘大撒里’ ‘Chungcheongnamdo’ ‘忠清南道’ ‘FORT’ ‘36.971401’ ‘126.454201’ ‘Taisen-ri’ ‘大川里’ ‘Chungcheongnamdo’ ‘忠清南道’ ‘FORT’ ‘36.349312’ ‘126.597717’ ‘Daejeon’ ‘大德’ ‘Chungcheongnamdo’ ‘忠清南道’ ‘FORT’ ‘36.321388’ ‘127.419724’ ‘Songwon’ ‘天安’ ‘Chungcheongnamdo”忠清南道’ ‘FORT’ ‘36.915562’ ‘127.131393’ |
| ‘Jeonju’ ‘全州’ ‘Jeollabukdo’ ‘全羅北道’ ‘CITE’ ‘35.821941’ ‘127.148888’
‘Iksan’ ‘益山’ ‘Jeollabukdo’ ‘全羅北道’ ‘CITE’ ‘35.94389’ ‘126.954437’ ‘Gunsan’ ‘群山’ ‘Jeollabukdo’ ‘全羅北道’ ‘CITE’ ‘35.978611’ ‘126.711389’ REM ‘Kunsan’ ‘群山’ ‘Jeollabukdo’ ‘全羅北道’ ‘CITE’ ‘35.978611’ ‘126.711388’ ‘Jeongeup’ ‘井邑’ ‘Jeollabukdo’ ‘全羅北道’ ‘CITE’ ‘35.565278’ ‘126.856111’ REM ‘Chongup’ ‘井邑’ ‘Jeollabukdo’ ‘全羅北道’ ‘CITE’ ‘35.5’ ‘126.9’ ‘Gimje’ ‘金堤’ ‘Jeollabukdo’ ‘全羅北道’ ‘CITE’ ‘35.801667’ ‘126.888889’ REM ‘Kimje’ ‘金堤’ ‘Jeollabukdo’ ‘全羅北道’ ‘CITE’ ‘35.80167’ ‘126.888893’ ‘Namwon’ ‘南原’ ‘Jeollabukdo’ ‘全羅北道’ ‘FORT’ ‘35.410000’ ‘127.385833’ REM ‘Nangen’ ‘南原’ ‘Jeollabukdo’ ‘全羅北道’ ‘FORT’ ‘35.41’ ‘127.385834’ ‘Wanju’ ‘完州’ ‘Jeollabukdo’ ‘全羅北道’ ‘FORT’ ‘35.845089’ ‘127.147522’ ‘Gochang’ ‘高敞’ ‘Jeollabukdo’ ‘全羅北道’ ‘FORT’ ‘35.4’ ‘126.7’ REM ‘Kochang’ ‘高敞’ ‘Jeollabukdo’ ‘全羅北道’ ‘FORT’ ‘35.433331’ ‘126.699997’ ‘Buan’ ‘扶安’ ‘Jeollabukdo’ ‘全羅北道’ ‘FORT’ ‘35.728056’ ‘126.731944’ REM ‘Puan’ ‘扶安’ ‘Jeollabukdo’ ‘全羅北道’ ‘FORT’ ‘35.728056’ ‘126.731944’ ‘Sunchang’ ‘淳昌’ ‘Jeollabukdo’ ‘全羅北道’ ‘FORT’ ‘35.373611’ ‘127.142778’ ‘Imsil’ ‘任實’ ‘Jeollabukdo’ ‘全羅北道’ ‘FORT’ ‘35.613056’ ‘127.279444’ REM ‘Imsil’ ‘任實’ ‘Jeollabukdo’ ‘全羅北道’ ‘FORT’ ‘35.61306’ ‘127.279442’ ‘Muju’ ‘茂朱’ ‘Jeollabukdo’ ‘全羅北道’ ‘FORT’ ‘36.006944’ ‘127.660556’ ‘Jinan’ ‘鎮安’ ‘Jeollabukdo’ ‘全羅北道’ ‘FORT’ ‘35.791667’ ‘127.425278’ REM ‘Chinan’ ‘鎮安’ ‘Jeollabukdo’ ‘全羅北道’ ‘FORT’ ‘35.791667’ ‘127.425278’ REM ‘jin-angun’ ‘鎮安郡’ ‘Jeollabukdo’ ‘全羅北道’ ‘FORT’ ‘35.791672’ ‘127.425278’ s’Jangsu’ ‘長水’ ‘Jeollabukdo’ ‘全羅北道’ ‘FORT’ ‘35.646389’ ‘127.519444’ REM ‘Changsu’ ‘長水’ ‘Jeollabukdo’ ‘全羅北道’ ‘FORT’ ‘35.648418’ ‘127.515228’ |
|
‘Kwangju’ ‘光州’ ‘Jeollanamdo’ ‘全羅南道’ ‘CAPITAL’ ‘37.41’ ‘127.257217’ ‘Yeosu’ ‘麗水’ ‘Jeollanamdo’ ‘全羅南道’ ‘CITE’ ‘34.760556’ ‘127.662222’ REM ‘Yosu’ ‘麗水’ ‘Jeollanamdo’ ‘全羅南道’ ‘CITE’ ‘34.7’ ‘127.8’ REM ‘Reisui’ ‘麗水’ ‘Jeollanamdo’ ‘全羅南道’ ‘CITE’ ‘34.744171’ ‘127.737778’ ‘Mokpo’ ‘木浦’ ‘Jeollanamdo’ ‘全羅南道’ ‘CITE’ ‘34.793611’ ‘126.388611’ REM ‘Moppo’ ‘木浦’ ‘Jeollanamdo’ ‘全羅南道’ ‘CITE’ ‘34.79361’ ‘126.388611’ ‘Suncheon’ ‘順天’ ‘Jeollanamdo’ ‘全羅南道’ ‘CITE’ ‘34.950556’ ‘127.487500’ ‘Sunchun’ ‘順天’ ‘Jeollanamdo’ ‘全羅南道’ ‘FORT’ ‘34.948078’ ‘127.489471’ ‘Gwangyang’ ‘光陽’ ‘Jeollanamdo’ ‘全羅南道’ ‘CITE’ ‘34.940278’ ‘127.701667’ REM ‘Kwangyang’ ‘光陽’ ‘Jeollanamdo’ ‘全羅南道’ ‘CITE’ ‘34.975281’ ‘127.589172’ ‘Naju’ ‘羅州’ ‘Jeollanamdo’ ‘全羅南道’ ‘CITE’ ‘35.028332’ ‘126.717499’ ‘Muan’ ‘務安’ ‘Jeollanamdo’ ‘全羅南道’ ‘FORT’ ‘34.989722’ ‘126.471389’ ‘Haenam’ ‘海南’ ‘Jeollanamdo’ ‘全羅南道’ ‘FORT’ ‘34.574167’ ‘126.597500’ ‘Goheung’ ‘高興’ ‘Jeollanamdo’ ‘全羅南道’ ‘FORT’ ‘34.609444’ ‘127.285833’ REM ‘Kohung’ ‘高興’ ‘Jeollanamdo’ ‘全羅南道’ ‘FORT’ ‘34.609444’ ‘127.285833’ ‘Hwasun’ ‘和順’ ‘Jeollanamdo’ ‘全羅南道’ ‘FORT’ ‘35.059444’ ‘126.985000’ ‘Yeongam’ ‘靈巖’ ‘Jeollanamdo’ ‘全羅南道’ ‘FORT’ ‘34.798333’ ‘126.700000’ REM ‘Yongam’ ‘靈巖’ ‘Jeollanamdo’ ‘全羅南道’ ‘FORT’ ‘34.798333’ ‘126.700000’ ‘Yeonggwang’ ‘靈光’ ‘Jeollanamdo’ ‘全羅南道’ ‘FORT’ ‘35.275000’ ‘126.509444’ REM ‘Yonggwang’ ‘靈光’ ‘Jeollanamdo’ ‘全羅南道’ ‘FORT’ ‘35.275000’ ‘126.509444’ ‘Wando’ ‘莞島’ ‘Jeollanamdo’ ‘全羅南道’ ‘FORT’ ‘34.314167’ ‘126.753056’ ‘Damyang’ ‘潭陽’ ‘Jeollanamdo’ ‘全羅南道’ ‘FORT’ ‘35.318889’ ‘126.983889’ REM ‘Tamyang’ ‘潭陽’ ‘Jeollanamdo’ ‘全羅南道’ ‘FORT’ ‘35.318889’ ‘126.983889’ ‘Boseong’ ‘寶城’ ‘Jeollanamdo’ ‘全羅南道’ ‘FORT’ ‘34.770556’ ‘127.081667’ REM ‘Posong’ ‘寶城’ ‘Jeollanamdo’ ‘全羅南道’ ‘FORT’ ‘34.770556’ ‘127.081667’ ‘Jangseong’ ‘長城’ ‘Jeollanamdo’ ‘全羅南道’ ‘FORT’ ‘35.297778’ ‘126.784444’ REM ‘Changsong’ ‘長城’ ‘Jeollanamdo’ ‘全羅南道’ ‘FORT’ ‘35.297778’ ‘126.784444’ ‘Jangheung’ ‘長興’ ‘Jeollanamdo’ ‘全羅南道’ ‘FORT’ ‘34.684444’ ‘126.907500’ REM ‘Changhung’ ‘長興’ ‘Jeollanamdo’ ‘全羅南道’ ‘FORT’ ‘34.684444’ ‘126.907500’ ‘Gangjin’ ‘康津’ ‘Jeollanamdo’ ‘全羅南道’ ‘FORT’ ‘34.640556’ ‘126.770000’ REM ‘Kangjin’ ‘康津’ ‘Jeollanamdo’ ‘全羅南道’ ‘FORT’ ‘34.640556’ ‘126.770000’ ‘Sinan’ ‘新安’ ‘Jeollanamdo’ ‘全羅南道’ ‘FORT’ ‘34.826199’ ‘126.108627’ ‘Hampyeong’ ‘咸平’ ‘Jeollanamdo’ ‘全羅南道’ ‘FORT’ ‘35.063889’ ‘126.519444’ REM ‘Hampyong’ ‘咸平’ ‘Jeollanamdo’ ‘全羅南道’ ‘FORT’ ‘35.063889’ ‘126.519444’ ‘Jindo’ ‘珍島’ ‘Jeollanamdo’ ‘全羅南道’ ‘FORT’ ‘34.483056’ ‘126.261944’ REM ‘Chindo’ ‘珍島’ ‘Jeollanamdo’ ‘全羅南道’ ‘FORT’ ‘34.483056’ ‘126.261944’ ‘Gokseong’ ‘谷城’ ‘Jeollanamdo’ ‘全羅南道’ ‘FORT’ ‘35.280833’ ‘127.295278’ REM ‘Koksong’ ‘谷城’ ‘Jeollanamdo’ ‘全羅南道’ ‘FORT’ ‘35.280833’ ‘127.295278’ ‘Gurye’ ‘求禮’ ‘Jeollanamdo’ ‘全羅南道’ ‘FORT’ ‘35.209444’ ‘127.464444’ REM ‘Kurye’ ‘求禮’ ‘Jeollanamdo’ ‘全羅南道’ ‘FORT’ ‘35.209438’ ‘127.464439’ ‘Beolgyo’ ‘筏橋’ ‘Jeollanamdo’ ‘全羅南道’ ‘FORT’ ‘34.84494’ ‘127.342934’ REM ‘Reiko’ ‘Reiko 靈光郡’ ‘Jeollanamdo’ ‘全羅南道’ ‘FORT’ ‘35.275002’ ‘126.509438’ ‘Heuksando’ ‘黑山島’ ‘Jeollanamdo’ ‘全羅南道’ ‘FORT’ ‘34.683112’ ‘125.427302’
|
|
‘Daegu’ ‘大邱’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘CAPITAL’ ‘35.870281’ ‘128.59111’ ‘Pohang’ ‘浦項’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘CITE’ ‘36.032222’ ‘129.365000’ ‘Gumi’ ‘龜尾’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘CITE’ ‘36.210000’ ‘128.354444’ REM ‘Kumi’ ‘龜尾’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘CITE’ ‘36.113602’ ‘128.335999’ ‘Gyeongsan’ ‘慶山’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘CITE’ ‘35.816667’ ‘128.733333’ REM ‘Kyongsan’ ‘慶山’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘CITE’ ‘35.816667’ ‘128.733333’ ‘Gyeongju’ ‘慶州’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘CITE’ ‘35.850000’ ‘129.216667’ REM ‘Kyongju’ ‘慶州’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘CITE’ ‘35.850000’ ‘129.216667’ REM ‘Kyonju’ ‘慶州’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘CITE’ ‘35.842781’ ‘129.21167’ ‘Andong’ ‘安東’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘CITE’ ‘36.565559’ ‘128.725006’ ‘Gimcheon’ ‘金泉’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘CITE’ ‘36.121761’ ‘128.119812’ REM ‘Kimchon’ ‘金泉’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘CITE’ ‘36.119167’ ‘128.115278’ ‘Yeongju’ ‘榮州’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘CITE’ ‘36.821667’ ‘128.630833’ REM ‘Yongju’ ‘榮州’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘CITE’ ‘36.821667’ ‘128.630833’ REM ‘Eisen’ ‘榮州’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘FORT’ ‘36.821671’ ‘128.630829’ ‘Sangju’ ‘尚州’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘CITE’ ‘36.415278’ ‘128.160556’ REM ‘Sangju’ ‘尚州’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘CITE’ ‘36.415279’ ‘128.160553’ ‘Yeongcheon’ ‘永川’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘CITE’ ‘35.973333’ ‘128.938611’ REM ‘Yongchon’ ‘永川’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘CITE’ ‘35.973333’ ‘128.938611’ REM ‘Eisen’ ‘永川’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘FORT’ ‘35.967499’ ‘128.930832’ ‘Mungyeong’ ‘聞慶’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘FORT’ ‘36.593889’ ‘128.201389’ REM ‘Mungyong’ ‘聞慶’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘FORT’ ‘36.594582’ ‘128.199463’ ‘Chilgok’ ‘漆谷’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘CITE’ ‘35.994444’ ‘128.399722’ ‘Uiseong’ ‘義城’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘CITE’ ‘36.350000’ ‘128.683333’ REM ‘Uisong’ ‘義城’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘CITE’ ‘36.350000’ ‘128.683333’ ‘Uljin’ ‘蔚珍’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘FORT’ ‘36.983333’ ‘129.383333’ ‘Yecheon’ ‘醴泉’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘FORT’ ‘36.655556’ ‘128.456944’ REM ‘Yechon’ ‘醴泉’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘FORT’ ‘36.655556’ ‘128.456944’ ‘Cheongdo’ ‘清道’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘FORT’ ‘35.643611’ ‘128.743056’ REM ‘Chongdo’ ‘清道’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘FORT’ ‘35.643611’ ‘128.743056’ ‘Seongju’ ‘星州’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘FORT’ ‘35.917778’ ‘128.285833’ REM Songju’ ‘星州’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘FORT’ ‘35.917778’ ‘128.285833’ ‘Yeongdeok’ ‘盈德’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘FORT’ ‘36.410000’ ‘129.375000’ REM ‘Yongdok’ ‘盈德’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘FORT’ ‘36.410000’ ‘129.375000’ ‘Goryeong’ ‘高靈’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘FORT’ ‘35.730278’ ‘128.268889’ REM ‘Koryong’ ‘高靈’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘FORT’ ‘35.730278’ ‘128.268889’ ‘Bonghwa’ ‘奉化’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘FORT’ ‘36.888056’ ‘128.746389’ REM ‘Ponghwa’ ‘奉化’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘FORT’ ‘36.888056’ ‘128.746389’ ‘Cheongsong’ ‘青松’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘FORT’ ‘36.43351’ ‘129.057007’ REM ‘Cheongsong gun’ ‘青松郡’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘FORT’ ‘36.43351’ ‘129.057007’ REM ‘Chongsong’ ‘青松’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘FORT’ ‘36.432778’ ‘129.060000’ ‘Yeongyang’ ‘英陽’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘FORT’ ‘36.664167’ ‘129.118611’ REM ‘Yongyang’ ‘英陽’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘FORT’ ‘36.664167’ ‘129.118611’ ‘Ulleung’ ‘鬱陵’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘FORT’ ‘37.483333’ ‘130.900000’ REM ‘Ullung’ ‘鬱陵’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘FORT’ ‘37.483333’ ‘130.900000’ ‘Enjitsu’ ‘延日’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘FORT’ ‘35.994171’ ‘129.345001’ ‘Hayang’ ‘河陽’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘FORT’ ‘35.91333’ ‘128.820007’ ‘Heung-hai’ ‘興海’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘FORT’ ‘36.112499’ ‘129.352219’ ‘Hoko’ ‘霍科’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘FORT’ ‘36.032219’ ‘129.365005’ ‘Hwawon’ ‘花元’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘FORT’ ‘35.80167’ ‘128.500824’ ‘Jenzan’ ‘珍山’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘FORT’ ‘36.240829’ ‘128.297501’ ‘Keizan’ ‘慶山’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘FORT’ ‘35.82333’ ‘128.737778’ ‘Kunwi’ ‘軍威’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘FORT’ ‘36.234718’ ‘128.572784’ ‘Waegwan’ ‘倭館’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘FORT’ ‘35.991749’ ‘128.397324’ ‘Ulleungdo’ ‘鬱陵島’ ‘Gyeongsangbukdo’ ‘慶尚北道’ ‘FORT’ ‘37.484587’ ‘130.905727’
|
|
‘Pusan’ ‘釜山’ ‘Gyeongsangnamdo’ ‘慶尚南道’ ‘CAPITAL’ ‘35.102779’ ‘129.040283’ ‘Ungsang’ ‘梁山’ ‘Gyeongsangnamdo’ ‘慶尚南道’ ‘CITE’ ‘35.406109’ ‘129.16861’ ‘Ulsan’ ‘蔚山’ ‘Gyeongsangnamdo’ ‘慶尚南道’ ‘CAPITAL’ ‘35.53722’ ‘129.316666’ ‘Changwon’ ‘昌原’ ‘Gyeongsangnamdo’ ‘慶尚南道’ ‘CAPITAL’ ‘35.228062’ ‘128.681107’ ‘Chinhae’ ‘鎮海’ ‘Gyeongsangnamdo’ ‘慶尚南道’ ‘CITE’ ‘35.149441’ ‘128.659714’ ‘Chinju’ ‘晉州’ ‘Gyeongsangnamdo’ ‘慶尚南道’ ‘CITE’ ‘35.19278’ ‘128.084717’ ‘Gimhae’ ‘金海’ ‘Gyeongsangnamdo’ ‘慶尚南道’ ‘CITE’ ‘35.234167’ ‘128.881111’ REM ‘Kimhae’ ‘金海’ ‘Gyeongsangnamdo’ ‘慶尚南道’ ‘CITE’ ‘35.234169’ ‘128.881104’ ‘Jinju’ ‘晉州’ ‘Gyeongsangnamdo’ ‘慶尚南道’ ‘CITE’ ‘35.192778’ ‘128.084722’ REM ‘Chinju’ ‘晉州’ ‘Gyeongsangnamdo’ ‘慶尚南道’ ‘CITE’ ‘35.192778’ ‘128.084722’ ‘Yangsan’ ‘梁山’ ‘Gyeongsangnamdo’ ‘慶尚南道’ ‘CITE’ ‘35.338612’ ‘129.038605’ ‘Geoje’ ‘巨濟’ ‘Gyeongsangnamdo’ ‘慶尚南道’ ‘CITE’ ‘34.850278’ ‘128.588611’ REM ‘Koje’ ‘巨濟’ ‘Gyeongsangnamdo’ ‘慶尚南道’ ‘CITE’ ‘34.850278’ ‘128.588611’ REM ‘Kyosai’ ‘巨濟’ ‘Gyeongsangnamdo’ ‘慶尚南道’ ‘CITE’ ‘34.850281’ ‘128.588608’ ‘Tongyeong’ ‘統營’ ‘Gyeongsangnamdo’ ‘慶尚南道’ ‘FORT’ ‘34.845833’ ‘128.423611’ REM ‘Tongyong’ ‘統營’ ‘Gyeongsangnamdo’ ‘慶尚南道’ ‘FORT’ ‘34.845833’ ‘128.423611’ ‘Sacheon’ ‘泗川’ ‘Gyeongsangnamdo’ ‘慶尚南道’ ‘CITE’ ‘35.080315’ ‘128.083302’ REM ‘Sachon’ ‘泗川’ ‘Gyeongsangnamdo’ ‘慶尚南道’ ‘CITE’ ‘35.080315’ ‘128.083302’ ‘Miryang’ ‘密陽’ ‘Gyeongsangnamdo’ ‘慶尚南道’ ‘CITE’ ‘35.493328’ ‘128.748886’ ‘Haman’ ‘咸安’ ‘Gyeongsangnamdo’ ‘慶尚南道’ ‘FORT’ ‘35.236944’ ‘128.421389’ ‘Geochang’ ‘居昌’ ‘Gyeongsangnamdo’ ‘慶尚南道’ ‘FORT’ ‘35.686111’ ‘127.910278’ REM ‘Kochang’ ‘居昌’ ‘Gyeongsangnamdo’ ‘慶尚南道’ ‘FORT’ ‘35.686111’ ‘127.910278’ ‘Changnyeong’ ‘昌寧’ ‘Gyeongsangnamdo’ ‘慶尚南道’ ‘FORT’ ‘35.541451’ ‘128.495056’ REM ‘Changnyong’ ‘昌寧’ ‘Gyeongsangnamdo’ ‘慶尚南道’ ‘FORT’ ‘35.540278’ ‘128.499444’ ‘Goseong’ ‘固城’ ‘Gyeongsangnamdo’ ‘慶尚南道’ ‘FORT’ ‘34.972778’ ‘128.323611’ REM ‘Kosong’ ‘固城’ ‘Gyeongsangnamdo’ ‘慶尚南道’ ‘FORT’ ‘34.972778’ ‘128.323611’ ‘Namhae’ ‘南海’ ‘Gyeongsangnamdo’ ‘慶尚南道’ ‘FORT’ ‘34.839444’ ‘127.894444’ ‘Hapcheon’ ‘陜川’ ‘Gyeongsangnamdo’ ‘慶尚南道’ ‘FORT’ ‘35.565556’ ‘128.159444’ REM ‘Hapchon’ ‘陜川’ ‘Gyeongsangnamdo’ ‘慶尚南道’ ‘FORT’ ‘35.565556’ ‘128.159444’ ‘Hadong’ ‘河東’ ‘Gyeongsangnamdo’ ‘慶尚南道’ ‘FORT’ ‘35.069444’ ‘127.749167’ ‘Hamyang’ ‘咸陽’ ‘Gyeongsangnamdo’ ‘慶尚南道’ ‘FORT’ ‘35.518333’ ‘127.727222’ ‘Sancheong’ ‘山清’ ‘Gyeongsangnamdo’ ‘慶尚南道’ ‘FORT’ ‘35.414444’ ‘127.874444’ REM ‘Sanchong’ ‘山清’ ‘Gyeongsangnamdo’ ‘慶尚南道’ ‘FORT’ ‘35.414444’ ‘127.874444’ ‘Uiryeong’ ‘宜寧’ ‘Gyeongsangnamdo’ ‘慶尚南道’ ‘FORT’ ‘35.319167’ ‘128.261111’ REM ‘Uiryong’ ‘宜寧’ ‘Gyeongsangnamdo’ ‘慶尚南道’ ‘FORT’ ‘35.319167’ ‘128.261111’ ‘Kijang’ ‘機張’ ‘Gyeongsangnamdo’ ‘慶尚南道’ ‘FORT’ ‘35.244171’ ‘129.213882’ ‘Masan’ ‘馬山’ ‘Gyeongsangnamdo’ ‘慶尚南道’ ‘CITE’ ‘35.208061’ ‘128.572495’ ‘Naeso’ ‘内西’ ‘Gyeongsangnamdo’ ‘慶尚南道’ ‘FORT’ ‘35.249722’ ‘128.520004’ ‘Sinhyeon’ ‘新縣’ ‘Gyeongsangnamdo’ ‘慶尚南道’ ‘FORT’ ‘34.8825’ ‘128.626663’ ‘BUnited States of American’ ‘美國駐韓釜山領事館’ ‘Gyeongsangnamdo’ ‘慶尚南道’ ‘FORT’ ‘35.178082’ ‘129.074635’ |
| ‘Jeju’ ‘濟州’ ‘Chejudo’ ‘濟州島’ ‘CITE’ ‘33.5’ ‘126.5’
REM ‘Cheju’ ‘濟州’ ‘Chejudo’ ‘濟州島’ ‘CITE’ ‘33.50972’ ‘126.521942’ ‘Seogwipo’ ‘西歸浦’ ‘Chejudo’ ‘濟州島’ ‘CITE’ ‘33.253551’ ‘126.561009’ REM ‘Sogwipo’ ‘西歸浦’ ‘Chejudo’ ‘濟州島’ ‘CITE’ ‘33.253551’ ‘126.561009’ ‘Gaigeturi’ ‘涯月’ ‘Chejudo’ ‘濟州島’ ‘FORT’ ‘33.464439’ ‘126.318329’ ‘Gosan’ ‘高山’ ‘Chejudo’ ‘濟州島’ ‘FORT’ ‘33.304933’ ‘126.179070’ ‘Seongsan’ ‘城山’ ‘Chejudo’ ‘濟州島’ ‘FORT’ ‘33.464547’ ‘126.935271’ |
日本城市數據超過一千(人口過壹萬), 日本『市』再細一级係『町』仝『丁』太多冇記錄, 武士係『丁』, 农民係『町』.
城市數據分9類.
| 市英文 | 市漢字 | 縣英文 | 縣漢字 | 國英文 | 國漢字 | 分類 | 經度 | 緯度 |
都城分級以常住居民劃分, 外加『山』『島』『湖』『海角』.
| HOUSE | 壹門寨-屋-1以上 |
| HAMLET | 两門邨-1千以上 |
| FORT | 叁門堡壘-要塞-1萬以上 |
| CITE | 肆門城-10萬以上 |
| CAPITAL | 捌門都-100萬以上 |
| MOUNTAIN | 山 |
| ISLAND | 島 |
| CAPE | 海角 |
| LAKE | 湖 |
下列係日本城市數據庫
| ‘Sapporo’ ‘札幌’ ‘Hokkaido’ ‘北海道’ ‘CITE’ ‘43.064171’ ‘141.346939’
‘Abashiri’ ‘網走’ ‘Hokkaido’ ‘北海道’ ‘FORT’ ‘44.021271’ ‘144.269714’ ‘Akabira’ ‘赤平’ ‘Hokkaido’ ‘北海道’ ‘FORT’ ‘43.551392’ ‘142.053055’ ‘Asahikawa’ ‘旭川’ ‘Hokkaido’ ‘北海道’ ‘FORT’ ‘43.76778’ ‘142.370285’ ‘Ashibetsu’ ‘蘆別’ ‘Hokkaido’ ‘北海道’ ‘FORT’ ‘43.50972’ ‘142.185562’ ‘Bibai’ ‘美唄’ ‘Hokkaido’ ‘北海道’ ‘FORT’ ‘43.324718’ ‘141.858612’ ‘Bihoro’ ‘美幌’ ‘Hokkaido’ ‘北海道’ ‘FORT’ ‘43.822781’ ‘144.104446’ ‘Chitose’ ‘千歳’ ‘Hokkaido’ ‘北海道’ ‘FORT’ ‘42.819439’ ‘141.652222’ ‘Date’ ‘伊達’ ‘Hokkaido’ ‘北海道’ ‘FORT’ ‘42.46806’ ‘140.868057’ ‘Ebetsu’ ‘江別’ ‘Hokkaido’ ‘北海道’ ‘FORT’ ‘43.108059’ ‘141.550568’ ‘Fukagawa’ ‘深川’ ‘Hokkaido’ ‘北海道’ ‘FORT’ ‘43.708061’ ‘142.039169’ ‘Hakodate’ ‘函館’ ‘Hokkaido’ ‘北海道’ ‘CITE’ ‘41.775829’ ‘140.736664’ ‘Ishikari’ ‘石狩’ ‘Hokkaido’ ‘北海道’ ‘FORT’ ‘43.239719’ ‘141.353897’ ‘Iwamizawa’ ‘岩見澤’ ‘Hokkaido’ ‘北海道’ ‘FORT’ ‘43.200279’ ‘141.75972’ ‘Iwanai’ ‘岩内’ ‘Hokkaido’ ‘北海道’ ‘FORT’ ‘42.974442’ ‘140.508896’ ‘Kamiiso’ ‘上磯’ ‘Hokkaido’ ‘北海道’ ‘FORT’ ‘41.816669’ ‘140.649994’ ‘Kamikawa’ ‘上川’ ‘Hokkaido’ ‘北海道’ ‘HAMLET’ ‘43.847222’ ‘142.770556’ ‘Kitahiroshima’ ‘北廣島’ ‘Hokkaido’ ‘北海道’ ‘FORT’ ‘42.97583’ ‘141.567215’ ‘Kitami’ ‘北見’ ‘Hokkaido’ ‘北海道’ ‘CITE’ ‘43.803059’ ‘143.890823’ ‘Kushiro’ ‘釧路’ ‘Hokkaido’ ‘北海道’ ‘CITE’ ‘42.974998’ ‘144.374725’ ‘Makubetsu’ ‘幕別’ ‘Hokkaido’ ‘北海道’ ‘FORT’ ‘45.371391’ ‘141.821106’ ‘Mombetsu’ ‘紋別’ ‘Hokkaido’ ‘北海道’ ‘FORT’ ‘44.352501’ ‘143.352493’ ‘Muroran’ ‘室蘭市’ ‘Hokkaido’ ‘北海道’ ‘FORT’ ‘42.317219’ ‘140.988068’ ‘Nayoro’ ‘名寄’ ‘Hokkaido’ ‘北海道’ ‘FORT’ ‘44.350559’ ‘142.457779’ ‘Nemuro’ ‘根室’ ‘Hokkaido’ ‘北海道’ ‘FORT’ ‘43.323608’ ‘145.574997’ ‘Niseko Town’ ‘二世古町’ ‘Hokkaido’ ‘北海道’ ‘HAMLET’ ‘42.778709’ ‘140.669037’ ‘Obihiro’ ‘帶廣’ ‘Hokkaido’ ‘北海道’ ‘CITE’ ‘42.917221’ ‘143.204437’ ‘Otaru’ ‘小樽’ ‘Hokkaido’ ‘北海道’ ‘CITE’ ‘43.189442’ ‘141.002213’ ‘Otofuke’ ‘音更’ ‘Hokkaido’ ‘北海道’ ‘FORT’ ‘42.991669’ ‘143.200287’ ‘Rishiri Town’ ‘利尻町’ ‘Hokkaido’ ‘北海道’ ‘HAMLET’ ‘45.159279’ ‘141.196289’ ‘Rumoi’ ‘留萌’ ‘Hokkaido’ ‘北海道’ ‘FORT’ ‘43.934441’ ‘141.642776’ ‘Shibetsu’ ‘標津’ ‘Hokkaido’ ‘北海道’ ‘HAMLET’ ‘43.658989’ ‘145.131973’ ‘Shimo-furano’ ‘下富良野’ ‘Hokkaido’ ‘北海道’ ‘FORT’ ‘43.349998’ ‘142.383331’ ‘Shiraoi’ ‘白老’ ‘Hokkaido’ ‘北海道’ ‘FORT’ ‘42.549999’ ‘141.350006’ ‘Shizunai’ ‘静内’ ‘Hokkaido’ ‘北海道’ ‘FORT’ ‘42.333889’ ‘142.366943’ ‘Sunagawa’ ‘砂川’ ‘Hokkaido’ ‘北海道’ ‘FORT’ ‘43.486389’ ‘141.905563’ ‘Takikawa’ ‘瀧川’ ‘Hokkaido’ ‘北海道’ ‘FORT’ ‘43.55278’ ‘141.906387’ ‘Tobetsu’ ‘當別’ ‘Hokkaido’ ‘北海道’ ‘FORT’ ‘43.216942’ ‘141.516937’ ‘Tomakomai’ ‘苫小牧’ ‘Hokkaido’ ‘北海道’ ‘CITE’ ‘42.63694’ ‘141.603333’ ‘Utashinai’ ‘歌志内’ ‘Hokkaido’ ‘北海道’ ‘HAMLET’ ‘43.51667’ ‘142.050003’ ‘Wakkanai’ ‘稚内’ ‘Hokkaido’ ‘北海道’ ‘FORT’ ‘45.409439’ ‘141.673889’ ‘Yoichi’ ‘余市’ ‘Hokkaido’ ‘北海道’ ‘FORT’ ‘43.203892’ ‘140.770279’ ‘Esashi’ ‘江差’ ‘Hokkaido’ ‘北海道’ ‘HAMLET’ ‘41.869167’ ‘140.127500’ ‘Haboro’ ‘羽幌’ ‘Hokkaido’ ‘北海道’ ‘HAMLET’ ‘44.360556’ ‘141.697222’ ‘Kitamiesashi’ ‘北見枝幸’ ‘Hokkaido’ ‘北海道’ ‘FORT’ ‘44.939361’ ‘142.577361’ ‘Kutchan’ ‘俱知安’ ‘Hokkaido’ ‘北海道’ ‘FORT’ ‘42.901667’ ‘140.758889’ ‘Suttsu’ ‘壽都’ ‘Hokkaido’ ‘北海道’ ‘HAMLET’ ‘42.791111’ ‘140.228889’ ‘Urakawa’ ‘浦河’ ‘Hokkaido’ ‘北海道’ ‘FORT’ ‘42.168333’ ‘142.768333’ ‘Yubari’ ‘夕張’ ‘Hokkaido’ ‘北海道’ ‘HAMLET’ ‘43.056667’ ‘141.973889’ ‘Wakkanai’ ‘稚内’ ‘Hokkaido’ ‘北海道’ ‘FORT’ ‘45.415556’ ‘141.673056’ ‘Shibetsu’ ‘士別’ ‘Hokkaido’ ‘北海道’ ‘FORT’ ‘44.178611’ ‘142.400000’ ‘Mikasa’ ‘三笠’ ‘Hokkaido’ ‘北海道’ ‘HAMLET’ ‘43.245556’ ‘141.875278’ ‘Furano’ ‘富良野’ ‘Hokkaido’ ‘北海道’ ‘FORT’ ‘43.341944’ ‘142.383056’ ‘Noboribetsu’ ‘登別’ ‘Hokkaido’ ‘北海道’ ‘FORT’ ‘42.412778’ ‘141.106667’ ‘Eniwa’ ‘惠庭’ ‘Hokkaido’ ‘北海道’ ‘FORT’ ‘42.882500’ ‘141.577778’ ‘Hokuto’ ‘北斗’ ‘Hokkaido’ ‘北海道’ ‘FORT’ ‘41.824167’ ‘140.653056’ |
| ‘Hirosaki’ ‘弘前’ ‘Aomori ken’ ‘青森縣’ ‘CITE’ ‘40.59306’ ‘140.472504’
‘Aomori’ ‘青森’ ‘Aomori ken’ ‘青森縣’ ‘CITE’ ‘40.82444’ ‘140.740005’ ‘Hachinohe’ ‘八戶’ ‘Aomori ken’ ‘青森縣’ ‘FORT’ ‘40.512222’ ‘141.488333’ ‘Kuroishi’ ‘黑石’ ‘Aomori ken’ ‘青森縣’ ‘FORT’ ‘40.638889’ ‘140.592224’ ‘Goshogawara’ ‘五所川原’ ‘Aomori ken’ ‘青森縣’ ‘FORT’ ‘40.80444’ ‘140.441391’ ‘Towada’ ‘十和田’ ‘Aomori ken’ ‘青森縣’ ‘FORT’ ‘40.612778’ ‘141.205833’ ‘Misawa’ ‘三澤’ ‘Aomori ken’ ‘青森縣’ ‘FORT’ ‘40.683609’ ‘141.359726’ ‘Kizukuri’ ‘木造’ ‘Aomori ken’ ‘青森縣’ ‘FORT’ ‘40.80611’ ‘140.386108’ ‘Mutsu’ ‘陸奧’ ‘Aomori ken’ ‘青森縣’ ‘FORT’ ‘41.28944’ ‘141.216934’ ‘Fukaura’ ‘深浦’ ‘Aomori ken’ ‘青森縣’ ‘HAMLET’ ‘40.647778’ ‘139.927500’ ‘Tsugaru’ ‘津輕’ ‘Aomori ken’ ‘青森縣’ ‘FORT’ ‘40.808611’ ‘140.380000’ ‘Hirakawa’ ‘平川’ ‘Aomori ken’ ‘青森縣’ ‘FORT’ ‘40.584167’ ‘140.566389’ |
| ‘Hanamaki’ ‘花卷’ ‘Iwate ken’ ‘岩手縣’ ‘FORT’ ‘39.383331’ ‘141.116669’
‘Mizusawa’ ‘水澤’ ‘Iwate ken’ ‘岩手縣’ ‘FORT’ ‘39.133331’ ‘141.133331’ ‘Morioka’ ‘盛岡’ ‘Iwate ken’ ‘岩手縣’ ‘CITE’ ‘39.703609’ ‘141.152496’ ‘Kamaishi’ ‘釜石’ ‘Iwate ken’ ‘岩手縣’ ‘FORT’ ‘39.26667’ ‘141.883331’ ‘Ichinohe’ ‘一戶’ ‘Iwate ken’ ‘岩手縣’ ‘FORT’ ‘40.20694’ ‘141.301666’ ‘Ichinoseki’ ‘一關’ ‘Iwate ken’ ‘岩手縣’ ‘CITE’ ‘38.916672’ ‘141.133331’ ‘Kitakami’ ‘北上’ ‘Iwate ken’ ‘岩手縣’ ‘FORT’ ‘39.283329’ ‘141.116669’ ‘Miyako’ ‘宮古’ ‘Iwate ken’ ‘岩手縣’ ‘FORT’ ‘39.636669’ ‘141.952499’ ‘Ofunato’ ‘大船渡’ ‘Iwate ken’ ‘岩手縣’ ‘FORT’ ‘39.071671’ ‘141.716675’ ‘Otsuchi’ ‘大槌’ ‘Iwate ken’ ‘岩手縣’ ‘FORT’ ‘39.366669’ ‘141.899994’ ‘Shizukuishi’ ‘雫石’ ‘Iwate ken’ ‘岩手縣’ ‘FORT’ ‘39.683331’ ‘140.983337’ ‘Tono’ ‘遠野’ ‘Iwate ken’ ‘岩手縣’ ‘FORT’ ‘39.316669’ ‘141.533325’ ‘Yamada’ ‘山田’ ‘Iwate ken’ ‘岩手縣’ ‘FORT’ ‘39.466671’ ‘141.949997’ ‘Ryori’ ‘綾里’ ‘Iwate ken’ ‘岩手縣’ ‘FORT’ ‘39.054266’ ‘141.799253’ ‘Kuji’ ‘久慈’ ‘Iwate ken’ ‘岩手縣’ ‘FORT’ ‘40.190556’ ‘141.775556’ ‘Rikuzentakata’ ‘陸前高田’ ‘Iwate ken’ ‘岩手縣’ ‘FORT’ ‘39.020556’ ‘141.633056’ ‘Ninohe’ ‘二戶’ ‘Iwate ken’ ‘岩手縣’ ‘FORT’ ‘40.271389’ ‘141.304722’ ‘Hachimantai’ ‘八幡平’ ‘Iwate ken’ ‘岩手縣’ ‘FORT’ ‘39.956389’ ‘141.071667’ ‘Oshu’ ‘奧州’ ‘Iwate ken’ ‘岩手縣’ ‘FORT’ ‘39.144444’ ‘141.139167’ ‘Takizawa’ ‘瀧澤’ ‘Iwate ken’ ‘岩手縣’ ‘FORT’ ‘39.734722’ ‘141.076944’ |
| ‘Sendai’ ‘仙臺’ ‘Miyagi ken’ ‘宮城縣’ ‘CITE’ ‘38.26889’ ‘140.871933’
‘Furukawa’ ‘古川’ ‘Miyagi ken’ ‘宮城縣’ ‘FORT’ ‘38.571671’ ‘140.955566’ ‘Ishinomaki’ ‘石卷’ ‘Miyagi ken’ ‘宮城縣’ ‘CITE’ ‘38.416672’ ‘141.300003’ ‘Iwanuma’ ‘岩沼’ ‘Miyagi ken’ ‘宮城縣’ ‘FORT’ ‘38.104721’ ‘140.859436’ ‘Kakuda’ ‘角田’ ‘Miyagi ken’ ‘宮城縣’ ‘FORT’ ‘37.966671’ ‘140.783325’ ‘Kogota’ ‘小牛田’ ‘Miyagi ken’ ‘宮城縣’ ‘FORT’ ‘38.549999’ ‘141.050003’ ‘Marumori’ ‘丸森’ ‘Miyagi ken’ ‘宮城縣’ ‘FORT’ ‘37.916672’ ‘140.766663’ ‘Matsushima’ ‘松島’ ‘Miyagi ken’ ‘宮城縣’ ‘HOUSE’ ‘38.373569’ ‘141.06105’ ‘Okawara’ ‘大河原’ ‘Miyagi ken’ ‘宮城縣’ ‘FORT’ ‘38.049999’ ‘140.733612’ ‘Rifu’ ‘利府’ ‘Miyagi ken’ ‘宮城縣’ ‘FORT’ ‘38.323608’ ‘140.974442’ ‘Shiogama’ ‘鹽竈’ ‘Miyagi ken’ ‘宮城縣’ ‘FORT’ ‘38.316669’ ‘141.033325’ ‘Shiroishi’ ‘白石’ ‘Miyagi ken’ ‘宮城縣’ ‘FORT’ ‘38.00333’ ‘140.618332’ ‘Tomiya’ ‘富谷’ ‘Miyagi ken’ ‘宮城縣’ ‘FORT’ ‘38.393059’ ‘140.886108’ ‘Watari’ ‘亙理’ ‘Miyagi ken’ ‘宮城縣’ ‘FORT’ ‘38.035’ ‘140.851105’ ‘Yamoto’ ‘矢本’ ‘Miyagi ken’ ‘宮城縣’ ‘FORT’ ‘38.42738’ ‘141.214874’ ‘Wakuya’ ‘涌谷’ ‘Miyagi ken’ ‘宮城縣’ ‘FORT’ ‘38.533329’ ‘141.133331’ ‘Osaki’ ‘大崎’ ‘Miyagi ken’ ‘宮城縣’ ‘CITE’ ‘38.577222’ ‘140.955556’ ‘Kesennuma’ ‘氣仙沼’ ‘Miyagi ken’ ‘宮城縣’ ‘FORT’ ‘38.908056’ ‘141.570000’ ‘Natori’ ‘名取’ ‘Miyagi ken’ ‘宮城縣’ ‘FORT’ ‘38.171667’ ‘140.891944’ ‘Tagajo’ ‘多賀城’ ‘Miyagi ken’ ‘宮城縣’ ‘FORT’ ‘38.293889’ ‘141.004167’ ‘Kurihara’ ‘栗原’ ‘Miyagi ken’ ‘宮城縣’ ‘FORT’ ‘38.730000’ ‘141.021389’ ‘Tome’ ‘登米’ ‘Miyagi ken’ ‘宮城縣’ ‘FORT’ ‘38.691944’ ‘141.187778’ ‘Higashimatsushima’ ‘東松島’ ‘Miyagi ken’ ‘宮城縣’ ‘FORT’ ‘38.426389’ ‘141.211111’ |
| ‘Akita’ ‘秋田’ ‘Akita ken’ ‘秋田縣’ ‘CITE’ ‘39.716671’ ‘140.116669’
‘Akita Shi’ ‘秋田市’ ‘Akita ken’ ‘秋田縣’ ‘CITE’ ‘39.71806’ ‘140.103333’ ‘Yuzawa’ ‘湯澤’ ‘Akita ken’ ‘秋田縣’ ‘FORT’ ‘39.160475’ ‘140.496853’ ‘Yokote’ ‘橫手’ ‘Akita ken’ ‘秋田縣’ ‘FORT’ ‘39.299999’ ‘140.566666’ ‘Tenno’ ‘天王’ ‘Akita ken’ ‘秋田縣’ ‘FORT’ ‘39.900002’ ‘139.966675’ ‘Takanosu’ ‘鷹巣’ ‘Akita ken’ ‘秋田縣’ ‘FORT’ ‘40.221939’ ‘140.369446’ ‘Omagari’ ‘大曲’ ‘Akita ken’ ‘秋田縣’ ‘FORT’ ‘39.450001’ ‘140.483337’ ‘Odate’ ‘大館’ ‘Akita ken’ ‘秋田縣’ ‘FORT’ ‘40.268608’ ‘140.568329’ ‘Noshiro’ ‘能代’ ‘Akita ken’ ‘秋田縣’ ‘FORT’ ‘40.203892’ ‘140.02417’ ‘Kazuno’ ‘鹿角’ ‘Akita ken’ ‘秋田縣’ ‘FORT’ ‘40.183609’ ‘140.787216’ ‘Kakudate’ ‘角館’ ‘Akita ken’ ‘秋田縣’ ‘FORT’ ‘39.583328’ ‘140.566666’ ‘Oga’ ‘男鹿’ ‘Akita ken’ ‘秋田縣’ ‘FORT’ ‘39.886667’ ‘139.847500’ ‘Yurihonjo’ ‘由利本莊’ ‘Akita ken’ ‘秋田縣’ ‘FORT’ ‘39.385833’ ‘140.048889’ ‘Katagami’ ‘潟上’ ‘Akita ken’ ‘秋田縣’ ‘FORT’ ‘39.857222’ ‘140.013056’ ‘Daisen’ ‘大仙’ ‘Akita ken’ ‘秋田縣’ ‘FORT’ ‘39.453056’ ‘140.475556’ ‘Kitaakita’ ‘北秋田’ ‘Akita ken’ ‘秋田縣’ ‘FORT’ ‘40.226111’ ‘140.370833’ ‘Senboku’ ‘仙北’ ‘Akita ken’ ‘秋田縣’ ‘FORT’ ‘39.700000’ ‘140.730556’ ‘Nikaho’ ‘仁賀保’ ‘Akita ken’ ‘秋田縣’ ‘FORT’ ‘39.203056’ ‘139.907778’ |
| ‘Yamagata’ ‘山形’ ‘Yamagata ken’ ‘山形縣’ ‘CITE’ ‘38.240559’ ‘140.363327’
‘Fukura’ ‘吹浦’ ‘Yamagata ken’ ‘山形縣’ ‘FORT’ ‘34.25’ ‘134.716675’ ‘Yuza’ ‘遊佐’ ‘Yamagata ken’ ‘山形縣’ ‘FORT’ ‘39.014722’ ‘139.908889’ ‘Yonezawa’ ‘米澤’ ‘Yamagata ken’ ‘山形縣’ ‘FORT’ ‘37.916672’ ‘140.116669’ ‘Tsuruoka’ ‘鶴岡’ ‘Yamagata ken’ ‘山形縣’ ‘CITE’ ‘38.721668’ ‘139.821671’ ‘Tendo’ ‘天童’ ‘Yamagata ken’ ‘山形縣’ ‘FORT’ ‘38.353611’ ‘140.36972’ ‘Takahata’ ‘高畠’ ‘Yamagata ken’ ‘山形縣’ ‘FORT’ ‘38.002499’ ‘140.191116’ ‘Shinjo’ ‘新庄’ ‘Yamagata ken’ ‘山形縣’ ‘FORT’ ‘38.75861’ ‘140.300827’ ‘Sakata’ ‘酒田’ ‘Yamagata ken’ ‘山形縣’ ‘CITE’ ‘38.916672’ ‘139.854996’ ‘Sagae’ ‘寒河江’ ‘Yamagata ken’ ‘山形縣’ ‘FORT’ ‘38.372501’ ‘140.272507’ ‘Obanazawa’ ‘尾花澤’ ‘Yamagata ken’ ‘山形縣’ ‘FORT’ ‘38.603329’ ‘140.401947’ ‘Nagai’ ‘長井’ ‘Yamagata ken’ ‘山形縣’ ‘FORT’ ‘38.103611’ ‘140.035004’ ‘Kaminoyama’ ‘上山’ ‘Yamagata ken’ ‘山形縣’ ‘FORT’ ‘38.153889’ ‘140.273605’ ‘Higashine’ ‘東根’ ‘Yamagata ken’ ‘山形縣’ ‘FORT’ ‘38.438889’ ‘140.400558’ ‘Murayama’ ‘村山’ ‘Yamagata ken’ ‘山形縣’ ‘FORT’ ‘38.483333’ ‘140.380278’ ‘Nanyo’ ‘南陽’ ‘Yamagata ken’ ‘山形縣’ ‘FORT’ ‘38.055000’ ‘140.148333’ |
| ‘Aizuwakamatsu’ ‘會津若松’ ‘Fukushima ken’ ‘福島縣’ ‘CITE’ ‘37.494722’ ‘139.929722’
‘Fukushima’ ‘福島’ ‘Fukushima ken’ ‘福島縣’ ‘CITE’ ‘37.760833’ ‘140.474722’ ‘Wakamatsu’ ‘若松’ ‘Fukushima ken’ ‘福島縣’ ‘CITE’ ‘37.494722’ ‘139.929722’ ‘Shirakawa’ ‘白河’ ‘Fukushima ken’ ‘福島縣’ ‘FORT’ ‘37.126389’ ‘140.210833’ ‘Onahama’ ‘小名濱’ ‘Fukushima ken’ ‘福島縣’ ‘FORT’ ‘36.95461’ ‘140.90378’ ‘Yanagawa’ ‘梁川’ ‘Fukushima ken’ ‘福島縣’ ‘FORT’ ‘37.849998’ ‘140.600006’ ‘Sukagawa’ ‘須賀川’ ‘Fukushima ken’ ‘福島縣’ ‘FORT’ ‘37.283329’ ‘140.383331’ ‘Nihommatsu’ ‘二本松’ ‘Fukushima ken’ ‘福島縣’ ‘FORT’ ‘37.583328’ ‘140.433334’ ‘Motomiya’ ‘本宮’ ‘Fukushima ken’ ‘福島縣’ ‘FORT’ ‘37.51667’ ‘140.399994’ ‘Miharu’ ‘三春’ ‘Fukushima ken’ ‘福島縣’ ‘FORT’ ‘37.433331’ ‘140.483337’ ‘Koriyama’ ‘郡山’ ‘Fukushima ken’ ‘福島縣’ ‘CITE’ ‘37.400002’ ‘140.383331’ ‘Kitakata’ ‘喜多方’ ‘Fukushima ken’ ‘福島縣’ ‘FORT’ ‘37.650002’ ‘139.866669’ ‘Iwaki’ ‘磐城’ ‘Fukushima ken’ ‘福島縣’ ‘CITE’ ‘37.049999’ ‘140.883331’ ‘Ishikawa’ ‘石川’ ‘Fukushima ken’ ‘福島縣’ ‘FORT’ ‘37.150002’ ‘140.449997’ ‘Inawashiro’ ‘豬苗代’ ‘Fukushima ken’ ‘福島縣’ ‘FORT’ ‘37.566669’ ‘140.116669’ ‘Hobara’ ‘保原’ ‘Fukushima ken’ ‘福島縣’ ‘HAMLET’ ‘37.816669’ ‘140.550003’ ‘Funehiki’ ‘船引’ ‘Fukushima ken’ ‘福島縣’ ‘HAMLET’ ‘37.433331’ ‘140.583328’ ‘Shirakawa’ ‘白河’ ‘Fukushima ken’ ‘福島縣’ ‘FORT’ ‘37.126389’ ‘140.210833’ ‘Soma’ ‘相馬’ ‘Fukushima ken’ ‘福島縣’ ‘FORT’ ‘37.796667’ ‘140.919722’ ‘Tamura’ ‘田村’ ‘Fukushima ken’ ‘福島縣’ ‘FORT’ ‘37.440556’ ‘140.576111’ ‘Minamisoma’ ‘南相馬’ ‘Fukushima ken’ ‘福島縣’ ‘FORT’ ‘37.642222’ ‘140.957222’ ‘Date’ ‘伊達’ ‘Fukushima ken’ ‘福島縣’ ‘FORT’ ‘37.819167’ ‘140.563056’ |
| ‘Mito’ ‘水戶’ ‘Ibaraki ken’ ‘茨城縣’ ‘CITE’ ‘36.341389’ ‘140.446671’
‘Hitachi’ ‘日立’ ‘Ibaraki ken’ ‘茨城縣’ ‘CITE’ ‘36.599998’ ‘140.649994’ ‘Ami’ ‘阿見’ ‘Ibaraki ken’ ‘茨城縣’ ‘FORT’ ‘36.033329’ ‘140.199997’ ‘Katsuta’ ‘勝田’ ‘Ibaraki ken’ ‘茨城縣’ ‘CITE’ ‘36.383331’ ‘140.533325’ ‘Kashima’ ‘鹿嶋’ ‘Ibaraki ken’ ‘茨城縣’ ‘FORT’ ‘35.965359’ ‘140.644745’ ‘Kasama’ ‘笠間’ ‘Ibaraki ken’ ‘茨城縣’ ‘FORT’ ‘36.383331’ ‘140.266663’ ‘Iwai’ ‘岩井’ ‘Ibaraki ken’ ‘茨城縣’ ‘FORT’ ‘36.049999’ ‘139.899994’ ‘Ishige’ ‘石下’ ‘Ibaraki ken’ ‘茨城縣’ ‘FORT’ ‘36.116669’ ‘139.966675’ ‘Inashiki’ ‘稻敷’ ‘Ibaraki ken’ ‘茨城縣’ ‘FORT’ ‘35.956329’ ‘140.323563’ ‘Hitachi-Naka’ ‘常陸那珂’ ‘Ibaraki ken’ ‘茨城縣’ ‘CITE’ ‘36.396591’ ‘140.53479’ ‘Hasaki’ ‘波崎’ ‘Ibaraki ken’ ‘茨城縣’ ‘FORT’ ‘35.73333’ ‘140.833328’ ‘Funaishikawa’ ‘船石川’ ‘Ibaraki ken’ ‘茨城縣’ ‘FORT’ ‘36.466671’ ‘140.566666’ ‘Fujishiro’ ‘藤代’ ‘Ibaraki ken’ ‘茨城縣’ ‘HAMLET’ ‘35.916672’ ‘140.116669’ ‘Daigo’ ‘大子’ ‘Ibaraki ken’ ‘茨城縣’ ‘FORT’ ‘36.76667’ ‘140.350006’ ‘Edosaki’ ‘江戶崎’ ‘Ibaraki ken’ ‘茨城縣’ ‘FORT’ ‘35.950001’ ‘140.316666’ ‘Ishioka’ ‘石岡’ ‘Ibaraki ken’ ‘茨城縣’ ‘FORT’ ‘36.183331’ ‘140.266663’ ‘Itako’ ‘潮來’ ‘Ibaraki ken’ ‘茨城縣’ ‘FORT’ ‘35.933331’ ‘140.550003’ ‘Iwase’ ‘岩瀬’ ‘Ibaraki ken’ ‘茨城縣’ ‘FORT’ ‘36.349998’ ‘140.100006’ ‘Tateno’ ‘立野’ ‘Ibaraki ken’ ‘茨城縣’ ‘FORT’ ‘36.043774’ ‘140.113287’ ‘Yuki’ ‘結城’ ‘Ibaraki ken’ ‘茨城縣’ ‘FORT’ ‘36.299999’ ‘139.883331’ ‘Ushiku’ ‘牛久’ ‘Ibaraki ken’ ‘茨城縣’ ‘FORT’ ‘35.966671’ ‘140.133331’ ‘Tsukuba’ ‘筑波’ ‘Ibaraki ken’ ‘茨城縣’ ‘CITE’ ‘36.200001’ ‘140.100006’ ‘Takahagi’ ‘高萩’ ‘Ibaraki ken’ ‘茨城縣’ ‘FORT’ ‘36.716671’ ‘140.716675’ ‘Shimodate’ ‘下館’ ‘Ibaraki ken’ ‘茨城縣’ ‘FORT’ ‘36.299999’ ‘139.983337’ ‘Sakai’ ‘境’ ‘Ibaraki ken’ ‘茨城縣’ ‘FORT’ ‘36.099998’ ‘139.800003’ ‘Ryugasaki’ ‘龍崎’ ‘Ibaraki ken’ ‘茨城縣’ ‘FORT’ ‘35.900002’ ‘140.183334’ ‘Okunoya’ ‘奥谷’ ‘Ibaraki ken’ ‘茨城縣’ ‘FORT’ ‘36.283329’ ‘140.416672’ ‘Oarai’ ‘大洗’ ‘Ibaraki ken’ ‘茨城縣’ ‘FORT’ ‘36.316669’ ‘140.600006’ ‘Naka’ ‘中’ ‘Ibaraki ken’ ‘茨城縣’ ‘FORT’ ‘36.049999’ ‘140.166672’ ‘Moriya’ ‘守谷市’ ‘Ibaraki ken’ ‘茨城縣’ ‘FORT’ ‘35.933331’ ‘140’ ‘Mitsukaido’ ‘水海道’ ‘Ibaraki ken’ ‘茨城縣’ ‘FORT’ ‘36.01667’ ‘139.983337’ ‘Kitaibaraki’ ‘北茨城’ ‘Ibaraki ken’ ‘茨城縣’ ‘FORT’ ‘36.783329’ ‘140.75’ ‘Koga’ ‘古河’ ‘Ibaraki ken’ ‘茨城縣’ ‘CITE’ ‘36.183331’ ‘139.716675’ ‘Makabe’ ‘真壁’ ‘Ibaraki ken’ ‘茨城縣’ ‘FORT’ ‘36.26667’ ‘140.100006’ ‘Omiya’ ‘大宮’ ‘Ibaraki ken’ ‘茨城縣’ ‘FORT’ ‘36.549999’ ‘140.416672’ ‘Tomobe’ ‘友部’ ‘Ibaraki ken’ ‘茨城縣’ ‘FORT’ ‘36.349998’ ‘140.300003’ ‘Toride’ ‘取手’ ‘Ibaraki ken’ ‘茨城縣’ ‘CITE’ ‘35.900002’ ‘140.083328’ ‘Tsuchiura’ ‘土浦’ ‘Ibaraki ken’ ‘茨城縣’ ‘CITE’ ‘36.078333’ ‘140.204444’ ‘Chikusei’ ‘筑西’ ‘Ibaraki ken’ ‘茨城縣’ ‘CITE’ ‘36.306944’ ‘139.983056’ ‘Shimotsuma’ ‘下妻’ ‘Ibaraki ken’ ‘茨城縣’ ‘CITE’ ‘36.184444’ ‘139.968333’ ‘Joso’ ‘常總’ ‘Ibaraki ken’ ‘茨城縣’ ‘FORT’ ‘36.023611’ ‘139.993889’ ‘Hitachiota’ ‘常陸太田’ ‘Ibaraki ken’ ‘茨城縣’ ‘FORT’ ‘36.538333’ ‘140.530833’ ‘Takahagi’ ‘高萩’ ‘Ibaraki ken’ ‘茨城縣’ ‘FORT’ ‘36.713611’ ‘140.709444’ ‘Bando’ ‘坂東’ ‘Ibaraki ken’ ‘茨城縣’ ‘FORT’ ‘36.048333’ ‘139.888611’ ‘Hitachiomiya’ ‘常陸大宮’ ‘Ibaraki ken’ ‘茨城縣’ ‘FORT’ ‘36.542500’ ‘140.410833’ ‘Naka’ ‘那珂’ ‘Ibaraki ken’ ‘茨城縣’ ‘FORT’ ‘36.457500’ ‘140.486667’ ‘Kasumigaura’ ‘霞浦’ ‘Ibaraki ken’ ‘茨城縣’ ‘FORT’ ‘36.151667’ ‘140.237222’ ‘Sakuragawa’ ‘櫻川’ ‘Ibaraki ken’ ‘茨城縣’ ‘FORT’ ‘36.327222’ ‘140.090556’ ‘Kamisu’ ‘神棲’ ‘Ibaraki ken’ ‘茨城縣’ ‘FORT’ ‘35.890000’ ‘140.664444’ ‘Namegata’ ‘行方’ ‘Ibaraki ken’ ‘茨城縣’ ‘FORT’ ‘35.990556’ ‘140.489167’ ‘Hokota’ ‘鉾田’ ‘Ibaraki ken’ ‘茨城縣’ ‘FORT’ ‘36.158611’ ‘140.516389’ ‘Tsukubamirai’ ‘筑波未來’ ‘Ibaraki ken’ ‘茨城縣’ ‘FORT’ ‘35.963056’ ‘140.036944’ ‘Omitama’ ‘小美玉’ ‘Ibaraki ken’ ‘茨城縣’ ‘FORT’ ‘36.239167’ ‘140.352500’ |
| ‘Utsunomiya’ ‘宇都宮’ ‘Tochigi ken’ ‘栃木縣’ ‘CITE’ ‘36.56583’ ‘139.883606’
‘Ashikaga’ ‘足利’ ‘Tochigi ken’ ‘栃木縣’ ‘FORT’ ‘36.333328’ ‘139.449997’ ‘Ujiie’ ‘氏家’ ‘Tochigi ken’ ‘栃木縣’ ‘FORT’ ‘36.683331’ ‘139.966675’ ‘Tochigi’ ‘栃木’ ‘Tochigi ken’ ‘栃木縣’ ‘CITE’ ‘36.383331’ ‘139.733337’ ‘Yaita’ ‘矢板’ ‘Tochigi ken’ ‘栃木縣’ ‘FORT’ ‘36.799999’ ‘139.933334’ ‘Tanuma’ ‘田沼’ ‘Tochigi ken’ ‘栃木縣’ ‘FORT’ ‘36.366669’ ‘139.583328’ ‘Sano’ ‘佐野’ ‘Tochigi ken’ ‘栃木縣’ ‘CITE’ ‘36.316669’ ‘139.583328’ ‘Nikko’ ‘日光’ ‘Tochigi ken’ ‘栃木縣’ ‘FORT’ ‘36.719722’ ‘139.698056’ ‘Motegi’ ‘茂木’ ‘Tochigi ken’ ‘栃木縣’ ‘FORT’ ‘36.51667’ ‘140.183334’ ‘Mibu’ ‘壬生’ ‘Tochigi ken’ ‘栃木縣’ ‘FORT’ ‘36.416672’ ‘139.800003’ ‘Fukiage’ ‘吹上’ ‘Tochigi ken’ ‘栃木縣’ ‘FORT’ ‘36.099998’ ‘139.449997’ ‘Imaichi’ ‘今市’ ‘Tochigi ken’ ‘栃木縣’ ‘HAMLET’ ‘36.716671’ ‘139.683334’ ‘Kaminokawa’ ‘上三川’ ‘Tochigi ken’ ‘栃木縣’ ‘FORT’ ‘36.433331’ ‘139.916672’ ‘Kanuma’ ‘鹿沼’ ‘Tochigi ken’ ‘栃木縣’ ‘CITE’ ‘36.549999’ ‘139.733337’ ‘Nasukarasuyama ‘ ‘那須烏山’ ‘Tochigi ken’ ‘栃木縣’ ‘FORT’ ‘36.656944’ ‘140.151389’ ‘Karasuyama’ ‘烏山’ ‘Tochigi ken’ ‘栃木縣’ ‘HAMLET’ ‘36.650738’ ‘140.155102’ ‘Kuroiso’ ‘黑磯’ ‘Tochigi ken’ ‘栃木縣’ ‘FORT’ ‘36.966671’ ‘140.050003’ ‘Mashiko’ ‘益子’ ‘Tochigi ken’ ‘栃木縣’ ‘FORT’ ‘36.466671’ ‘140.100006’ ‘Mooka’ ‘真岡’ ‘Tochigi ken’ ‘栃木縣’ ‘FORT’ ‘36.433331’ ‘140.016663’ ‘Otawara’ ‘大田原’ ‘Tochigi ken’ ‘栃木縣’ ‘FORT’ ‘36.866669’ ‘140.033325’ ‘Oyama’ ‘小山’ ‘Tochigi ken’ ‘栃木縣’ ‘CITE’ ‘36.299999’ ‘139.800003’ ‘Nasushiobara’ ‘那須鹽原’ ‘Tochigi ken’ ‘栃木縣’ ‘CITE’ ‘36.961667’ ‘140.046111’ ‘Sakura’ ‘櫻’ ‘Tochigi ken’ ‘栃木縣’ ‘FORT’ ‘36.685278’ ‘139.966417’ ‘Fujioka’ ‘藤岡’ ‘Tochigi ken’ ‘栃木縣’ ‘FORT’ ‘36.255621’ ‘139.649903’ |
| ‘Maebashi’ ‘前橋’ ‘Gunma ken’ ‘群馬縣’ ‘CITE’ ‘36.391109’ ‘139.060837’
‘Yoshii’ ‘吉井’ ‘Gunma ken’ ‘群馬縣’ ‘FORT’ ‘36.254167’ ‘138.988889’ ‘Tomioka’ ‘富岡’ ‘Gunma ken’ ‘群馬縣’ ‘FORT’ ‘36.260000’ ‘138.890000’ ‘Tatebayashi’ ‘館林’ ‘Gunma ken’ ‘群馬縣’ ‘FORT’ ‘36.25’ ‘139.533325’ ‘Takasaki’ ‘高崎’ ‘Gunma ken’ ‘群馬縣’ ‘CITE’ ‘36.333328’ ‘139.016663’ ‘Sakai’ ‘境’ ‘Gunma ken’ ‘群馬縣’ ‘FORT’ ‘36.277076’ ‘139.256867’ ‘Ota’ ‘太田’ ‘Gunma ken’ ‘群馬縣’ ‘CITE’ ‘36.299999’ ‘139.366669’ ‘Numata’ ‘沼田’ ‘Gunma ken’ ‘群馬縣’ ‘FORT’ ‘36.633331’ ‘139.050003’ ‘Nakanojo’ ‘中之條’ ‘Gunma ken’ ‘群馬縣’ ‘FORT’ ‘36.583328’ ‘138.850006’ ‘Kiryu’ ‘桐生’ ‘Gunma ken’ ‘群馬縣’ ‘CITE’ ‘36.400002’ ‘139.333328’ ‘Kaneko’ ‘金古町’ ‘Gunma ken’ ‘群馬縣’ ‘FORT’ ‘36.406897’ ‘139.002505’ ‘Isesaki’ ‘伊勢崎’ ‘Gunma ken’ ‘群馬縣’ ‘CITE’ ‘36.316669’ ‘139.199997’ ‘Fujioka’ ‘藤岡’ ‘Gunma ken’ ‘群馬縣’ ‘FORT’ ‘36.250158’ ‘139.083322’ ‘Annaka’ ‘安中’ ‘Gunma ken’ ‘群馬縣’ ‘FORT’ ‘36.316669’ ‘138.899994’ ‘Omama’ ‘大間間’ ‘Gunma ken’ ‘群馬縣’ ‘FORT’ ‘36.433331’ ‘139.283325’ ‘Shibukawa’ ‘澀川’ ‘Gunma ken’ ‘群馬縣’ ‘FORT’ ‘36.489444’ ‘139.000556’ ‘Tamamura’ ‘玉村’ ‘Gunma ken’ ‘群馬縣’ ‘FORT’ ‘36.299999’ ‘139.116669’ ‘Midori’ ‘綠’ ‘Gunma ken’ ‘群馬縣’ ‘FORT’ ‘36.394722’ ‘139.281111’ |
| ‘Saitama’ ‘埼玉’ ‘Saitama ken’ ‘埼玉縣’ ‘CAPITAL’ ‘35.90807’ ‘139.65657’
‘Ageo’ ‘上尾’ ‘Saitama ken’ ‘埼玉縣’ ‘FORT’ ‘35.969719’ ‘139.588608’ ‘Shiki’ ‘志木’ ‘Saitama ken’ ‘埼玉縣’ ‘FORT’ ‘35.833328’ ‘139.583328’ ‘Morohongo’ ‘毛呂本郷’ ‘Saitama ken’ ‘埼玉縣’ ‘FORT’ ‘35.935558’ ‘139.304443’ ‘Menuma’ ‘妻沼’ ‘Saitama ken’ ‘埼玉縣’ ‘CITE’ ‘36.216671’ ‘139.383331’ ‘Konosu’ ‘鴻巢’ ‘Saitama ken’ ‘埼玉縣’ ‘CITE’ ‘36.049999’ ‘139.516663’ ‘Kodama’ ‘兒玉’ ‘Saitama ken’ ‘埼玉縣’ ‘FORT’ ‘36.183331’ ‘139.133331’ ‘Kawagoe’ ‘川越’ ‘Saitama ken’ ‘埼玉縣’ ‘CITE’ ‘35.908611’ ‘139.485275’ ‘Kawaguchi’ ‘川口’ ‘Saitama ken’ ‘埼玉縣’ ‘CITE’ ‘35.805’ ‘139.720566’ ‘Kazo’ ‘加須’ ‘Saitama ken’ ‘埼玉縣’ ‘CITE’ ‘36.116669’ ‘139.600006’ ‘Kasukabe’ ‘春日部’ ‘Saitama ken’ ‘埼玉縣’ ‘CITE’ ‘35.976391’ ‘139.753616’ ‘Fujimi’ ‘富士見’ ‘Saitama ken’ ‘埼玉縣’ ‘CITE’ ‘35.856667’ ‘139.549167’ ‘Fujimino’ ‘富士見野’ ‘Saitama ken’ ‘埼玉縣’ ‘CITE’ ‘35.879444’ ‘139.519722’ ‘Kamifukuoka’ ‘上福岡’ ‘Saitama ken’ ‘埼玉縣’ ‘CITE’ ‘35.872501’ ‘139.50972’ ‘Iwatsuki’ ‘岩槻’ ‘Saitama ken’ ‘埼玉縣’ ‘CITE’ ‘35.94278’ ‘139.69194’ ‘Honjo’ ‘本庄’ ‘Saitama ken’ ‘埼玉縣’ ‘FORT’ ‘36.23333’ ‘139.183334’ ‘Hanno’ ‘飯能’ ‘Saitama ken’ ‘埼玉縣’ ‘FORT’ ‘35.85194’ ‘139.318054’ ‘Hanyu’ ‘羽生’ ‘Saitama ken’ ‘埼玉縣’ ‘FORT’ ‘36.166672’ ‘139.533325’ ‘Gyoda’ ‘行田’ ‘Saitama ken’ ‘埼玉縣’ ‘FORT’ ‘36.133331’ ‘139.449997’ ‘Chichibu’ ‘秩父’ ‘Saitama ken’ ‘埼玉縣’ ‘FORT’ ‘35.99028’ ‘139.076385’ ‘Asaka’ ‘朝霞’ ‘Saitama ken’ ‘埼玉縣’ ‘FORT’ ‘35.804722’ ‘139.601944’ ‘Fukaya’ ‘深谷’ ‘Saitama ken’ ‘埼玉縣’ ‘FORT’ ‘36.200001’ ‘139.283325’ ‘Hasuda’ ‘蓮田’ ‘Saitama ken’ ‘埼玉縣’ ‘FORT’ ‘35.975559’ ‘139.650833’ ‘Hatogaya’ ‘川口’ ‘Saitama ken’ ‘埼玉縣’ ‘CITE’ ‘35.834171’ ‘139.736389’ ‘Kisai’ ‘騎西’ ‘Saitama ken’ ‘埼玉縣’ ‘FORT’ ‘36.099998’ ‘139.583328’ ‘Kuki’ ‘久喜’ ‘Saitama ken’ ‘埼玉縣’ ‘CITE’ ‘36.066669’ ‘139.666672’ ‘Kumagaya’ ‘熊谷’ ‘Saitama ken’ ‘埼玉縣’ ‘CITE’ ‘36.133331’ ‘139.383331’ ‘Koshigaya’ ‘越谷’ ‘Saitama ken’ ‘埼玉縣’ ‘CITE’ ‘35.883331’ ‘139.783325’ ‘Kurihashi’ ‘栗橋’ ‘Saitama ken’ ‘埼玉縣’ ‘FORT’ ‘36.133331’ ‘139.699997’ ‘Oi’ ‘大井中宿’ ‘Saitama ken’ ‘埼玉縣’ ‘CITE’ ‘35.851109’ ‘139.516663’ ‘Ogawa’ ‘小川’ ‘Saitama ken’ ‘埼玉縣’ ‘FORT’ ‘36.049999’ ‘139.266663’ ‘Okegawa’ ‘桶川’ ‘Saitama ken’ ‘埼玉縣’ ‘FORT’ ‘36.002778’ ‘139.558611’ ‘Sakado’ ‘坂戶’ ‘Saitama ken’ ‘埼玉縣’ ‘CITE’ ‘35.95694’ ‘139.388885’ ‘Shiraoka’ ‘白岡’ ‘Saitama ken’ ‘埼玉縣’ ‘FORT’ ‘36.01667’ ‘139.666672’ ‘Shobu’ ‘菖蒲’ ‘Saitama ken’ ‘埼玉縣’ ‘FORT’ ‘36.066669’ ‘139.600006’ ‘Soka’ ‘草加’ ‘Saitama ken’ ‘埼玉縣’ ‘CITE’ ‘35.820278’ ‘139.804443’ ‘Sugito’ ‘杉戶’ ‘Saitama ken’ ‘埼玉縣 ‘FORT’ ‘36.033329’ ‘139.733337’ ‘Toda’ ‘戶田’ ‘Saitama ken’ ‘埼玉縣’ ‘FORT’ ‘35.809441’ ‘139.692505’ ‘Tokorozawa’ ‘所澤’ ‘Saitama ken’ ‘埼玉縣’ ‘CITE’ ‘35.79916’ ‘139.469025’ ‘Wako’ ‘和光’ ‘Saitama ken’ ‘埼玉縣’ ‘FORT’ ‘35.78944’ ‘139.623337’ ‘Warabi’ ‘蕨’ ‘Saitama ken’ ‘埼玉縣’ ‘FORT’ ‘35.826389’ ‘139.704437’ ‘Yashio’ ‘八潮’ ‘Saitama ken’ ‘埼玉縣’ ‘FORT’ ‘35.822552’ ‘139.83905’ ‘Yono’ ‘與野’ ‘Saitama ken’ ‘埼玉縣’ ‘FORT’ ‘35.883331’ ‘139.633331’ ‘Yorii’ ‘寄居’ ‘Saitama ken’ ‘埼玉縣’ ‘FORT’ ‘36.116669’ ‘139.199997’ ‘Yoshikawa’ ‘吉川’ ‘Saitama ken’ ‘埼玉縣’ ‘FORT’ ‘35.885281’ ‘139.839447’ ‘Higashimatsuyama’ ‘東松山’ ‘Saitama ken’ ‘埼玉縣’ ‘FORT’ ‘36.042222’ ‘139.400000’ ‘Sayama’ ‘狹山’ ‘Saitama ken’ ‘埼玉縣’ ‘CITE’ ‘35.853056’ ‘139.412222’ ‘Iruma’ ‘入間’ ‘Saitama ken’ ‘埼玉縣’ ‘CITE’ ‘35.835833’ ‘139.391111’ ‘Niiza’ ‘新座’ ‘Saitama ken’ ‘埼玉縣’ ‘CITE’ ‘35.793611’ ‘139.565278’ ‘Kitamoto’ ‘北本’ ‘Saitama ken’ ‘埼玉縣’ ‘FORT’ ‘36.026944’ ‘139.530278’ ‘Misato’ ‘三鄉’ ‘Saitama ken’ ‘埼玉縣’ ‘CITE’ ‘35.830278’ ‘139.872222’ ‘Satte’ ‘幸手’ ‘Saitama ken’ ‘埼玉縣’ ‘FORT’ ‘36.078056’ ‘139.725833’ ‘Tsurugashima’ ‘鶴島’ ‘Saitama ken’ ‘埼玉縣’ ‘FORT’ ‘35.934444’ ‘139.393056’ ‘Hidaka’ ‘日高’ ‘Saitama ken’ ‘埼玉縣’ ‘FORT’ ‘35.907778’ ‘139.339167’ |
| ‘Chiba’ ‘千葉’ ‘Chiba ken’ ‘千葉縣’ ‘CAPITAL’ ‘35.604721’ ‘140.123337’
‘Abiko’ ‘我孫子’ ‘Chiba ken’ ‘千葉縣’ ‘FORT’ ‘35.866669’ ‘140.016663’ ‘Yotsukaido’ ‘四街道’ ‘Chiba ken’ ‘千葉縣’ ‘CITE’ ‘35.650002’ ‘140.166672’ ‘Yachimata’ ‘八街’ ‘Chiba ken’ ‘千葉縣’ ‘FORT’ ‘35.650002’ ‘140.316666’ ‘Urayasu’ ‘浦安’ ‘Chiba ken’ ‘千葉縣’ ‘CITE’ ‘35.670559’ ‘139.888611’ ‘Shiroi’ ‘白井’ ‘Chiba ken’ ‘千葉縣’ ‘FORT’ ‘35.799999’ ‘140.066666’ ‘Omigawa’ ‘小見川’ ‘Chiba ken’ ‘千葉縣’ ‘FORT’ ‘35.849998’ ‘140.616669’ ‘Ohara’ ‘大原’ ‘Chiba ken’ ‘千葉縣’ ‘FORT’ ‘35.25’ ‘140.383331’ ‘Noda’ ‘野田’ ‘Chiba ken’ ‘千葉縣’ ‘CITE’ ‘35.941109’ ‘139.858063’ ‘Oami’ ‘大網’ ‘Chiba ken’ ‘千葉縣’ ‘FORT’ ‘35.51667’ ‘140.316666’ ‘Narashino’ ‘習志野’ ‘Chiba ken’ ‘千葉縣’ ‘CITE’ ‘35.683331’ ‘140.033325’ ‘Narita’ ‘成田’ ‘Chiba ken’ ‘千葉縣’ ‘CITE’ ‘35.783329’ ‘140.316666’ ‘Naruto’ ‘成東’ ‘Chiba ken’ ‘千葉縣’ ‘FORT’ ‘35.599998’ ‘140.416672’ ‘Nagareyama’ ‘流山’ ‘Chiba ken’ ‘千葉縣’ ‘CITE’ ‘35.8563’ ‘139.902664’ ‘Mobara’ ‘茂原’ ‘Chiba ken’ ‘千葉縣’ ‘FORT’ ‘35.416672’ ‘140.300003’ ‘Matsudo’ ‘松戶’ ‘Chiba ken’ ‘千葉縣’ ‘CITE’ ‘35.783329’ ‘139.899994’ ‘Kashiwa’ ‘柏’ ‘Chiba ken’ ‘千葉縣’ ‘CITE’ ‘35.854439’ ‘139.968887’ ‘Katori’ ‘香取’ ‘Chiba ken’ ‘千葉縣’ ‘FORT’ ‘35.897671’ ‘140.499435’ ‘Ichihara’ ‘市原’ ‘Chiba ken’ ‘千葉縣’ ‘CITE’ ‘35.51667’ ‘140.083328’ ‘Ichikawa’ ‘市川’ ‘Chiba ken’ ‘千葉縣’ ‘CITE’ ‘35.719719’ ‘139.924713’ ‘Funabashi’ ‘船橋’ ‘Chiba ken’ ‘千葉縣’ ‘CITE’ ‘35.693062’ ‘139.983337’ ‘Asahi’ ‘旭’ ‘Chiba ken’ ‘千葉縣’ ‘FORT’ ‘35.716671’ ‘140.649994’ ‘Futtsu’ ‘富津’ ‘Chiba ken’ ‘千葉縣’ ‘FORT’ ‘35.305279’ ‘139.818604’ ‘Kamagaya’ ‘鎌谷’ ‘Chiba ken’ ‘千葉縣’ ‘CITE’ ‘35.776741’ ‘140.000748’ ‘Katsuura’ ‘勝浦’ ‘Chiba ken’ ‘千葉縣’ ‘FORT’ ‘35.133331’ ‘140.300003’ ‘Kimitsu’ ‘君津’ ‘Chiba ken’ ‘千葉縣’ ‘FORT’ ‘35.325279’ ‘139.891113’ ‘Kisarazu’ ‘木更津’ ‘Chiba ken’ ‘千葉縣’ ‘CITE’ ‘35.374722’ ‘139.922501’ ‘Kawaguchi’ ‘鴨川’ ‘Chiba ken’ ‘千葉縣’ ‘FORT’ ‘35.099998’ ‘140.100006’ ‘Sakura’ ‘佐倉’ ‘Chiba ken’ ‘千葉縣’ ‘CITE’ ‘35.716671’ ‘140.233337’ ‘Shisui’ ‘酒酒井’ ‘Chiba ken’ ‘千葉縣’ ‘FORT’ ‘35.716671’ ‘140.266663’ ‘Tateyama’ ‘館山’ ‘Chiba ken’ ‘千葉縣’ ‘FORT’ ‘34.98333’ ‘139.866669’ ‘Togane’ ‘東金’ ‘Chiba ken’ ‘千葉縣’ ‘FORT’ ‘35.549999’ ‘140.366669’ ‘Yokaichiba’ ‘八日市場’ ‘Chiba ken’ ‘千葉縣’ ‘FORT’ ‘35.700001’ ‘140.550003’ ‘Choshi’ ‘銚子’ ‘Chiba ken’ ‘千葉縣’ ‘FORT’ ‘35.734722’ ‘140.826667’ ‘Yachiyo’ ‘八千代’ ‘Chiba ken’ ‘千葉縣’ ‘CITE’ ‘35.722500’ ‘140.100000’ ‘Kamagaya’ ‘鎌谷’ ‘Chiba ken’ ‘千葉縣’ ‘CITE’ ‘35.776944’ ‘140.000833’ ‘Sodegaura’ ‘袖浦’ ‘Chiba ken’ ‘千葉縣’ ‘FORT’ ‘35.430000’ ‘139.954444’ ‘Inzai’ ‘印西’ ‘Chiba ken’ ‘千葉縣’ ‘CITE’ ‘35.832222’ ‘140.145833’ ‘Tomisato’ ‘富里’ ‘Chiba ken’ ‘千葉縣’ ‘FORT’ ‘35.726667’ ‘140.343056’ ‘Isumi’ ‘夷隅’ ‘Chiba ken’ ‘千葉縣’ ‘FORT’ ‘35.253889’ ‘140.385278’ ‘Sosa’ ‘匝瑳’ ‘Chiba ken’ ‘千葉縣’ ‘FORT’ ‘35.707778’ ‘140.564167’ ‘Minamiboso’ ‘南房總’ ‘Chiba ken’ ‘千葉縣’ ‘FORT’ ‘35.043056’ ‘139.840000’ ‘Sanmu’ ‘山武’ ‘Chiba ken’ ‘千葉縣’ ‘FORT’ ‘35.603056’ ‘140.413611’ ‘Oamishirasato’ ‘大網白里’ ‘Chiba ken’ ‘千葉縣’ ‘FORT’ ‘35.521667’ ‘140.321111’ |
| ‘Tokyo’ ‘東京’ ‘Tokyo to’ ‘東京都’ ‘CAPITAL’ ‘35.689499’ ‘139.691711’
‘Hachioji’ ‘八王子’ ‘東京都’ ‘CITE’ ‘35.65583’ ‘139.323883’ ‘Tachikawa’ ‘立川’ ‘Tokyo to’ ‘東京都’ ‘CITE’ ‘35.69278’ ‘139.41806’ ‘Adachi’ ‘足立’ ‘Tokyo to’ ‘東京都’ ‘CITE’ ‘35.775000’ ‘139.804444’ ‘Arakawa’ ‘荒川’ ‘Tokyo to’ ‘東京都’ ‘CITE’ ‘35.736111’ ‘139.783333’ ‘Bunkyo’ ‘文京’ ‘Tokyo to’ ‘東京都’ ‘CITE’ ‘35.708056’ ‘139.752222’ ‘Chiyoda’ ‘千代田’ ‘Tokyo to’ ‘東京都’ ‘FORT’ ‘35.683333’ ‘139.750000’ ‘Chuo’ ‘中央’ ‘Tokyo to’ ‘東京都’ ‘CITE’ ‘35.670556’ ‘139.771944’ ‘Edogawa’ ‘江戶川’ ‘Tokyo to’ ‘東京都’ ‘CITE’ ‘35.706667’ ‘139.868333’ ‘Itabashi’ ‘板橋’ ‘Tokyo to’ ‘東京都’ ‘CITE’ ‘35.751111’ ‘139.709167’ ‘Katsushika’ ‘葛飾’ ‘Tokyo to’ ‘東京都’ ‘CITE’ ‘35.743333’ ‘139.847222’ ‘Kita’ ‘北區’ ‘Tokyo to’ ‘東京都’ ‘CITE’ ‘35.752778’ ‘139.733611’ ‘Koto’ ‘江東’ ‘Tokyo to’ ‘東京都’ ‘CITE’ ‘35.672778’ ‘139.817222’ ‘Meguro’ ‘目黑’ ‘Tokyo to’ ‘東京都’ ‘CITE’ ‘35.641389’ ‘139.698333’ ‘Minato’ ‘港’ ‘Tokyo to’ ‘東京都’ ‘CITE’ ‘35.658056’ ‘139.751667’ ‘Nakano’ ‘中野’ ‘Tokyo to’ ‘東京都’ ‘CITE’ ‘35.707222’ ‘139.663611’ ‘Ota’ ‘大田’ ‘Tokyo to’ ‘東京都’ ‘CITE’ ‘35.561389’ ‘139.716111’ ‘Setagaya’ ‘世田谷’ ‘Tokyo to’ ‘東京都’ ‘CITE’ ‘35.646667’ ‘139.653333’ ‘Shibuya’ ‘澀谷’ ‘Tokyo to’ ‘東京都’ ‘CITE’ ‘35.663611’ ‘139.697778’ ‘Shinagawa’ ‘品川’ ‘Tokyo to’ ‘東京都’ ‘CITE’ ‘35.609167’ ‘139.730278’ ‘Shinagawa-ku’ ‘品川區’ ‘Tokyo to’ ‘東京都’ ‘CITE’ ‘35.60902’ ‘139.730164’ ‘Shinjuku’ ‘新宿’ ‘Tokyo to’ ‘東京都’ ‘CITE’ ‘35.693889’ ‘139.703333’ ‘Suginami’ ‘杉並’ ‘Tokyo to’ ‘東京都’ ‘CITE’ ‘35.699444’ ‘139.636389’ ‘Sumida’ ‘墨田’ ‘Tokyo to’ ‘東京都’ ‘CITE’ ‘35.710556’ ‘139.801389’ ‘Taito’ ‘台東’ ‘Tokyo to’ ‘東京都’ ‘CITE’ ‘35.712500’ ‘139.780000’ ‘Toshima’ ‘豐島’ ‘Tokyo to’ ‘東京都’ ‘CITE’ ‘35.726111’ ‘139.716667’ ‘Nerima’ ‘練馬’ ‘Tokyo to’ ‘東京都’ ‘CITE’ ‘35.735556’ ‘139.651667’ ‘Musashino’ ‘武藏野’ ‘Tokyo to’ ‘東京都’ ‘CITE’ ‘35.717778’ ‘139.566111’ ‘Mitaka’ ‘三鷹’ ‘Tokyo to’ ‘東京都’ ‘CITE’ ‘35.683611’ ‘139.559444’ ‘Ome’ ‘青梅’ ‘Tokyo to’ ‘東京都’ ‘CITE’ ‘35.788056’ ‘139.275833’ ‘Fuchu’ ‘府中’ ‘Tokyo to’ ‘東京都’ ‘CITE’ ‘35.668889’ ‘139.477778’ ‘Akishima’ ‘昭島’ ‘Tokyo to’ ‘東京都’ ‘CITE’ ‘35.705556’ ‘139.353611’ ‘Chofu’ ‘調布’ ‘Tokyo to’ ‘東京都’ ‘CITE’ ‘35.650556’ ‘139.540556’ ‘Machida’ ‘町田’ ‘Tokyo to’ ‘東京都’ ‘CITE’ ‘35.540279’ ‘139.450836’ ‘Koganei’ ‘小金井’ ‘Tokyo to’ ‘東京都’ ‘CITE’ ‘35.699444’ ‘139.503056’ ‘Kodaira’ ‘小平’ ‘Tokyo to’ ‘東京都’ ‘CITE’ ‘35.728611’ ‘139.477500’ ‘Hino’ ‘日野’ ‘Tokyo to’ ‘東京都’ ‘CITE’ ‘35.671389’ ‘139.395278’ ‘Higashimurayama’ ‘東村山’ ‘Tokyo to’ ‘東京都’ ‘CITE’ ‘35.754722’ ‘139.468611’ ‘Kokubunji’ ‘國分寺’ ‘Tokyo to’ ‘東京都’ ‘CITE’ ‘35.702221’ ‘139.475555’ ‘Kunitachi’ ‘國立’ ‘Tokyo to’ ‘東京都’ ‘FORT’ ‘35.674438’ ‘139.434998’ ‘Fussa’ ‘福生’ ‘Tokyo to’ ‘東京都’ ‘FORT’ ‘35.736671’ ‘139.323608’ ‘Komae’ ‘狛江’ ‘Tokyo to’ ‘東京都’ ‘FORT’ ‘35.636391’ ‘139.574432’ ‘Higashiyamato’ ‘東大和’ ‘Tokyo to’ ‘東京都’ ‘FORT’ ‘35.745278’ ‘139.426389’ ‘Kiyose’ ‘清瀨’ ‘Tokyo to’ ‘東京都’ ‘FORT’ ‘35.785833’ ‘139.526389’ ‘Higashikurume’ ‘東久留米’ ‘Tokyo to’ ‘東京都’ ‘FORT’ ‘35.758056’ ‘139.529722’ ‘Musashimurayama’ ‘武藏村山’ ‘Tokyo to’ ‘東京都’ ‘FORT’ 35.754722, 139.387222 ‘Tama’ ‘多摩’ ‘Tokyo to’ ‘東京都’ ‘FORT’ ‘35.636944’ ‘139.446389’ ‘Inagi’ ‘稻城’ ‘Tokyo to’ ‘東京都’ ‘FORT’ ‘35.638056’ ‘139.504444’ ‘Hamura’ ‘羽村’ ‘Tokyo to’ ‘東京都’ ‘FORT’ ‘35.767222’ ‘139.310833’ ‘Akiruno’ ‘秋留野’ ‘Tokyo to’ ‘東京都’ ‘FORT’ ‘35.728779’ ‘139.294144’ ‘Nishi-Tokyo’ ‘西東京’ ‘Tokyo to’ ‘東京都’ ‘CITE’ ‘35.725262’ ‘139.5383’ ‘Itsukaichi’ ‘五日市’ ‘Tokyo to’ ‘東京都’ ‘FORT’ ‘35.725281’ ‘139.217773’ ‘Kami-renjaku’ ‘上連雀’ ‘Tokyo to’ ‘東京都’ ‘FORT’ ‘35.683331’ ‘139.550003’ ‘Tanashi’ ‘田無’ ‘Tokyo to’ ‘東京都’ ‘FORT’ ‘35.723888’ ‘139.522217’ ‘Hoya’ ‘保谷’ ‘Tokyo to’ ‘東京都’ ‘FORT’ ‘35.741667’ ‘139.558889’ ‘Oshima’ ‘大島’ ‘Tokyo to’ ‘東京都’ ‘HAMLET’ ‘34.750278’ ‘139.355556’ ‘Toshima’ ‘利島’ ‘Tokyo to’ ‘東京都’ ‘HOUSE’ ‘34.528480’ ‘139.280682’ ‘Kozushima’ ‘神津島’ ‘Tokyo to’ ‘東京都’ ‘HAMLET’ ‘34.205556’ ‘139.134444’ ‘Niijima’ ‘新島’ ‘Tokyo to’ ‘東京都’ ‘HAMLET’ ‘34.376944’ ‘139.256667’ ‘Shikinejima’ ‘式根島’ ‘Tokyo to’ ‘東京都’ ‘HOUSE’ ‘34.330676’ ‘139.214603’ ‘Miyakejima’ ‘三宅島’ ‘Tokyo to’ ‘東京都’ ‘HOUSE’ ‘34.075770’ ‘139.478432’ ‘Mikurajima’ ‘御藏島’ ‘Tokyo to’ ‘東京都’ ‘HOUSE’ ‘33.897545’ ‘139.595823’ ‘Hachijojima’ ‘八丈島’ ‘Tokyo to’ ‘東京都’ ‘HAMLET’ ‘33.109444’ ‘139.790833’ ‘Hachijōkojima’ ‘八丈小島’ ‘Tokyo to’ ‘東京都’ ‘HOUSE’ ‘33.125278’ ‘139.688333’ ‘Aogashima’ ‘青島’ ‘Tokyo to’ ‘東京都’ ‘HOUSE’ ‘32.466667’ ‘139.763611’ ‘Udoneshima’ ‘鵜渡根島’ ‘Tokyo to’ ‘東京都’ ‘HOUSE’ ‘34.471242’ ‘139.293334’ ‘Torishima’ ‘鳥島’ ‘Tokyo to’ ‘東京都’ ‘HOUSE’ ‘30.483705’ ‘140.289702’ ‘Chichijima’ ‘父島’ ‘Tokyo to’ ‘東京都’ ‘HAMLET’ ‘27.077778’ ‘142.216667’ ‘Hahajima’ ‘母島’ ‘Tokyo to’ ‘東京都’ ‘HOUSE’ ‘26.673432’ ‘142.154046’ ‘Anijima’ ‘兄島’ ‘Tokyo to’ ‘東京都’ ‘ISLAND’ ‘27.121389’ ‘142.214167’ ‘Ototojima’ ‘弟島’ ‘Tokyo to’ ‘東京都’ ‘ISLAND’ ‘27.166667’ ‘142.191667’ ‘Chichijima’ ‘孫島’ ‘Tokyo to’ ‘東京都’ ‘ISLAND’ ‘27.194528’ ‘142.195889’ ‘Nishijima’ ‘西島’ ‘Tokyo to’ ‘東京都’ ‘ISLAND’ ‘27.117667’ ‘142.167417’ ‘Higashijima’ ‘東島’ ‘Tokyo to’ ‘東京都’ ‘ISLAND’ ‘27.093556’ ‘142.245139’ ‘Minamijima’ ‘南島’ ‘Tokyo to’ ‘東京都’ ‘ISLAND’ ‘27.038447’ ‘142.175661’ ‘Iwoto’ ‘硫磺島’ ‘Tokyo to’ ‘東京都’ ‘HAMLET’ ‘24.783889’ ‘141.312778’ ‘Miyakejima’ ‘三宅島’ ‘Tokyo to’ ‘東京都’ ‘ISLAND’ ‘34.093600’ ‘139.526100’ ‘Minamitorishima’ ‘南鳥島’ ‘Tokyo to’ ‘東京都’ ‘ISLAND’ ‘24.286667’ ‘153.980556’ ‘Okinotorishima’ ‘沖之鳥’ ‘Tokyo to’ ‘東京都’ ‘ISLAND’ ‘20.423000’ ‘136.073861’ |
| ‘Yokohama’ ‘橫濱’ ‘Kanagawa Ken’ ‘神奈川縣’ ‘CAPITAL’ ‘35.447781’ ‘139.642502’
‘Yokosuka’ ‘橫須賀’ ‘Kanagawa Ken’ ‘神奈川縣’ ‘CITE’ ‘35.283611’ ‘139.667221’ ‘Kawasaki’ ‘川崎’ ‘Kanagawa Ken’ ‘神奈川縣’ ‘CITE’ ‘35.520561’ ‘139.717224’ ‘Hiratsuka’ ‘平塚’ ‘Kanagawa Ken’ ‘神奈川縣’ ‘CITE’ ‘35.323059’ ‘139.342224’ ‘Kamakura’ ‘鎌倉’ ‘Kanagawa Ken’ ‘神奈川縣’ ‘CITE’ ‘35.308891’ ‘139.550278’ ‘Yugawara’ ‘湯河原’ ‘Kanagawa Ken’ ‘神奈川縣’ ‘FORT’ ‘35.150002’ ‘139.066666’ ‘Fujisawa’ ‘藤澤’ ‘Kanagawa Ken’ ‘神奈川縣’ ‘CITE’ ‘35.341942’ ‘139.470001’ ‘Odawara’ ‘小田原’ ‘Kanagawa Ken’ ‘神奈川縣’ ‘CITE’ ‘35.255562’ ‘139.159714’ ‘Chigasaki’ ‘茅崎’ ‘Kanagawa Ken’ ‘神奈川’ ‘CITE’ ‘35.326111’ ‘139.403885’ ‘Miura’ ‘三浦’ ‘Kanagawa Ken’ ‘神奈川縣’ ‘FORT’ ‘35.139999’ ‘139.619171’ ‘Minami-rinkan’ ‘南林間’ ‘Kanagawa Ken’ ‘神奈川縣’ ‘FORT’ ‘35.48333’ ‘139.449997’ ‘Isehara’ ‘伊勢原’ ‘Kanagawa Ken’ ‘神奈川縣’ ‘CITE’ ‘35.39056’ ‘139.307785’ ‘Hayama’ ‘葉山’ ‘Kanagawa Ken’ ‘神奈川縣’ ‘FORT’ ‘35.26667’ ‘139.583328’ ‘Atsugi’ ‘厚木’ ‘Kanagawa Ken’ ‘神奈川縣’ ‘FORT’ ‘35.438889’ ‘139.359726’ ‘Hadano’ ‘秦野’ ‘Kanagawa Ken’ ‘神奈川縣’ ‘FORT’ ‘35.371109’ ‘139.223618’ ‘Hakone’ ‘箱根’ ‘Kanagawa Ken’ ‘神奈川縣’ ‘FORT’ ‘35.183331’ ‘139.033325’ ‘Ninomiya’ ‘二宮’ ‘Kanagawa Ken’ ‘神奈川縣’ ‘FORT’ ‘35.303329’ ‘139.253326’ ‘Oiso’ ‘大磯’ ‘Kanagawa Ken’ ‘神奈川縣’ ‘FORT’ ‘35.303059’ ‘139.30278’ ‘Sagamihara’ ‘Kanagawa Ken’ ‘相模原’ ‘神奈川縣’ ‘CITE’ ‘35.553059’ ‘139.354446’ ‘Zama’ ‘座間’ ‘Kanagawa Ken’ ‘神奈川縣’ ‘CITE’ ‘35.488892’ ‘139.388611’ ‘Zushi’ ‘逗子’ ‘Kanagawa Ken’ ‘神奈川縣’ ‘FORT’ ‘35.291672’ ‘139.585556’ ‘Yamato’ ‘大和’ ‘Kanagawa Ken’ ‘神奈川縣’ ‘FORT’ ‘35.487500’ ‘139.458056’ ‘Ebina’ ‘海老名’ ‘Kanagawa Ken’ ‘神奈川縣’ ‘FORT’ ‘35.446389’ ‘139.390833’ ‘Minamiashigara’ ‘南足柄’ ‘Kanagawa Ken’ ‘神奈川縣’ ‘FORT’ ‘35.320833’ ‘139.099722’ ‘Ayase’ ‘綾瀨’ ‘Kanagawa Ken’ ‘神奈川縣’ ‘FORT’ ‘35.437222’ ‘139.426111’ |
| ‘Niigata’ ‘新潟’ ‘Niigata ken’ ‘新潟縣’ ‘CITE’ ‘37.902222’ ‘139.023605’
‘Nagaoka’ ‘長岡’ ‘Niigata ken’ ‘新潟縣’ ‘CITE’ ‘37.450001’ ‘138.850006’ ‘Sanjo’ ‘三條’ ‘Niigata ken’ ‘新潟縣’ ‘FORT’ ‘37.616669’ ‘138.949997’ ‘Kashiwazaki’ ‘柏崎’ ‘Niigata ken’ ‘新潟縣’ ‘FORT’ ‘37.366669’ ‘138.550003’ ‘Shibata’ ‘新發田’ ‘Niigata ken’ ‘新潟縣’ ‘FORT’ ‘37.950001’ ‘139.333328’ ‘Arai’ ‘新井’ ‘Niigata ken’ ‘新潟縣’ ‘HAMLET’ ‘37.01667’ ‘138.25’ ‘Gosen’ ‘五泉’ ‘Niigata ken’ ‘新潟縣’ ‘FORT’ ‘37.73333’ ‘139.166672’ ‘Aikawa’ ‘相川’ ‘Niigata ken’ ‘新潟縣’ ‘FORT’ ‘38.028873’ ‘138.240210’ ‘Tsubame’ ‘燕’ ‘Niigata ken’ ‘新潟縣’ ‘FORT’ ‘37.650002’ ‘138.933334’ ‘Tsubame’ ‘燕’ ‘Niigata ken’ ‘新潟縣’ ‘FORT’ ‘37.650002’ ‘138.933334’ ‘Tochio’ ‘栃尾’ ‘Niigata ken’ ‘新潟縣’ ‘FORT’ ‘37.472393’ ‘138.988044’ ‘Mitsuke’ ‘見附’ ‘Niigata ken’ ‘新潟縣’ ‘FORT’ ‘37.533329’ ‘138.933334’ ‘Maki’ ‘巻’ ‘Niigata ken’ ‘新潟縣’ ‘FORT’ ‘37.756913’ ‘138.889468’ ‘Joetsu’ ‘上越’ ‘Niigata ken’ ‘新潟縣’ ‘CITE’ ‘37.148281’ ‘138.23642’ ‘Itoigawa’ ‘糸魚川’ ‘Niigata ken’ ‘新潟縣’ ‘FORT’ ‘37.033329’ ‘137.850006’ ‘Kameda’ ‘龜田’ ‘Niigata ken’ ‘新潟縣’ ‘FORT’ ‘37.866669’ ‘139.116669’ ‘Kamo’ ‘加茂’ ‘Niigata ken’ ‘新潟縣’ ‘FORT’ ‘37.650002’ ‘139.050003’ ‘Muikamachi’ ‘六日町’ ‘Niigata ken’ ‘新潟縣’ ‘FORT’ ‘37.066669’ ‘138.883331’ ‘Murakami’ ‘村上’ ‘Niigata ken’ ‘新潟縣’ ‘FORT’ ‘38.23333’ ‘139.483337’ ‘Muramatsu’ ‘村松’ ‘Niigata ken’ ‘新潟縣’ ‘FORT’ ‘37.683331’ ‘139.183334’ ‘Tokamachi’ ‘十日町’ ‘Niigata ken’ ‘新潟縣’ ‘FORT’ ‘37.133331’ ‘138.766663’ ‘Yoshida’ ‘吉田’ ‘Niigata ken’ ‘新潟縣’ ‘FORT’ ‘37.683331’ ‘138.883331’ ‘Takada’ ‘高田’ ‘Niigata ken’ ‘新潟縣’ ‘FORT’ ‘37.109900’ ‘138.255908’ ‘Shiozawa’ ‘鹽澤’ ‘Niigata ken’ ‘新潟縣’ ‘FORT’ ‘37.033329’ ‘138.850006’ ‘Ryotsu’ ‘兩津’ ‘Niigata ken’ ‘新潟縣’ ‘FORT’ ‘38.083328’ ‘138.433334’ ‘Ojiya’ ‘小千谷’ ‘Niigata ken’ ‘新潟縣’ ‘FORT’ ‘37.299999’ ‘138.800003’ ‘Niitsu’ ‘新津’ ‘Niigata ken’ ‘新潟縣’ ‘FORT’ ‘37.799999’ ‘139.116669’ ‘Shirone’ ‘白根’ ‘Niigata ken’ ‘新潟縣’ ‘FORT’ ‘37.76667’ ‘139.016663’ ‘Suibara’ ‘水原’ ‘Niigata ken’ ‘新潟縣’ ‘FORT’ ‘37.833328’ ‘139.233337’ ‘Myoko’ ‘妙高’ ‘Niigata ken’ ‘新潟縣’ ‘FORT’ ‘37.025278’ ‘138.253611’ ‘Sado’ ‘佐渡’ ‘Niigata ken’ ‘新潟縣’ ‘FORT’ ‘38.044444’ ‘138.389722’ ‘Agano’ ‘阿賀野’ ‘Niigata ken’ ‘新潟縣’ ‘FORT’ ‘37.834444’ ‘139.226111’ ‘Uonuma’ ‘魚沼’ ‘Niigata ken’ ‘新潟縣’ ‘FORT’ ‘37.236389’ ‘138.963889’ ‘Minamiuonuma’ ‘南魚沼’ ‘Niigata ken’ ‘新潟縣’ ‘FORT’ ‘37.065556’ ‘138.876111’ ‘Tainai’ ‘胎內’ ‘Niigata ken’ ‘新潟縣’ ‘FORT’ ‘38.059722’ ‘139.410278’ |
| ‘Toyama’ ‘富山’ ‘Toyama ken’ ‘富山縣’ ‘CITE’ ‘36.695278’ ‘137.211395’
‘Takaoka’ ‘高岡’ ‘Toyama ken’ ‘富山縣’ ‘CITE’ ‘36.749167’ ‘137.020556’ ‘Fukumitsu’ ‘福光’ ‘Toyama ken’ ‘富山縣’ ‘HAMLET’ ‘36.549999’ ‘136.866669’ ‘Fushiki’ ‘伏木’ ‘Toyama ken’ ‘富山縣’ ‘FORT’ ‘36.785491’ ‘137.052021’ ‘Yatsuo’ ‘八尾’ ‘Toyama ken’ ‘富山縣’ ‘FORT’ ‘36.566669’ ‘137.133331’ ‘Uozu’ ‘魚津’ ‘Toyama ken’ ‘富山縣’ ‘FORT’ ‘36.799999’ ‘137.399994’ ‘Shimminato’ ‘新湊’ ‘Toyama ken’ ‘富山縣’ ‘FORT’ ‘36.783329’ ‘137.066666’ ‘Nyuzen’ ‘入善’ ‘Toyama ken’ ‘富山縣’ ‘FORT’ ‘36.933331’ ‘137.5’ ‘Namerikawa’ ‘滑川市’ ‘Toyama ken’ ‘富山縣’ ‘FORT’ ‘36.76667’ ‘137.333328’ ‘Nanto’ ‘南礪’ ‘Toyama ken’ ‘富山縣’ ‘FORT’ ‘36.569221’ ‘136.911621’ ‘Kamiichi’ ‘上市’ ‘Toyama ken’ ‘富山縣’ ‘FORT’ ‘36.700001’ ‘137.366669’ ‘Himi’ ‘冰見’ ‘Toyama ken’ ‘富山縣’ ‘FORT’ ‘36.849998’ ‘136.983337’ ‘Kosugi’ ‘小杉’ ‘Toyama ken’ ‘富山縣’ ‘FORT’ ‘36.716671’ ‘137.100006’ ‘Kurobe’ ‘黑部’ ‘Toyama ken’ ‘富山縣’ ‘FORT’ ‘36.871389’ ‘137.447778’ ‘Tonami’ ‘礪波’ ‘Toyama ken’ ‘富山縣’ ‘FORT’ ‘36.647500’ ‘136.962222’ ‘Oyabe’ ‘小矢部’ ‘Toyama ken’ ‘富山縣’ ‘FORT’ ‘36.675556’ ‘136.868611’ ‘Imizu’ ‘射水’ ‘Toyama ken’ ‘富山縣’ ‘FORT’ ‘36.730556’ ‘137.075556’ |
| ‘Kanazawa’ ‘金澤’ ‘Ishikawa ken’ ‘石川縣’ ‘CITE’ ‘36.59444’ ‘136.625565’
‘Nanao’ ‘七尾’ ‘Ishikawa ken’ ‘石川縣’ ‘CITE’ ‘37.043056’ ‘136.967500’ ‘Hakui’ ‘羽咋’ ‘Ishikawa ken’ ‘石川縣’ ‘FORT’ ‘36.883331’ ‘136.783325’ ‘Nonoichi’ ‘野野市’ ‘Ishikawa ken’ ‘石川縣’ ‘FORT’ ‘36.533329’ ‘136.616669’ ‘Komatsu’ ‘小松’ ‘Ishikawa ken’ ‘石川縣’ ‘CITE’ ‘36.40263’ ‘136.450882’ ‘Matsuto’ ‘松任’ ‘Ishikawa ken’ ‘石川縣’ ‘FORT’ ‘36.51667’ ‘136.566666’ ‘Tsubata’ ‘津幡’ ‘Ishikawa ken’ ‘石川縣’ ‘FORT’ ‘36.666672’ ‘136.733337’ ‘Tsubata’ ‘津幡’ ‘Ishikawa ken’ ‘石川縣’ ‘FORT’ ‘36.666672’ ‘136.733337’ ‘Tsurugi’ ‘鶴来’ ‘Ishikawa ken’ ‘石川縣’ ‘FORT’ ‘36.450001’ ‘136.633331’ ‘Wajima’ ‘輪島’ ‘Ishikawa ken’ ‘石川縣’ ‘FORT’ ‘37.390556’ ‘136.899167’ ‘Suzu’ ‘珠洲’ ‘Ishikawa ken’ ‘石川縣’ ‘FORT’ ‘37.436389’ ‘137.260556’ ‘Kaga’ ‘加賀’ ‘Ishikawa ken’ ‘石川縣’ ‘FORT’ ‘36.302778’ ‘136.315000’ ‘Kahoku’ ‘河北’ ‘Ishikawa ken’ ‘石川縣’ ‘FORT’ ‘36.719722’ ‘136.706667’ ‘Hakusan’ ‘白山’ ‘Ishikawa ken’ ‘石川縣’ ‘CITE’ ‘36.514444’ ‘136.565556’ ‘Nomi’ ‘能美’ ‘Ishikawa ken’ ‘石川縣’ ‘FORT’ ‘36.446944’ ‘136.554167’ |
| ‘Fukui’ ‘福井’ ‘Fukui ken’ ‘福井縣’ ‘CITE’ ‘36.06443’ ‘136.222565’
‘Tsuruga’ ‘敦賀’ ‘Fukui ken’ ‘福井縣’ ‘FORT’ ‘35.64547’ ‘136.055801’ ‘Mikuni’ ‘三國’ ‘Fukui ken’ ‘福井縣’ ‘FORT’ ‘36.21706’ ‘136.151855’ ‘Ono’ ‘大野’ ‘Fukui ken’ ‘福井縣’ ‘FORT’ ‘35.98106’ ‘136.487274’ ‘Sabae’ ‘鯖江市’ ‘Fukui ken’ ‘福井縣’ ‘FORT’ ‘35.946468’ ‘136.184982’ ‘Takefu’ ‘武生’ ‘Fukui ken’ ‘福井縣’ ‘FORT’ ‘35.903931’ ‘136.16687’ ‘Obama’ ‘小濱’ ‘Fukui ken’ ‘福井縣’ ‘FORT’ ‘35.495762’ ‘135.746033’ ‘Maruoka’ ‘丸岡’ ‘Fukui ken’ ‘福井縣’ ‘FORT’ ‘36.1534’ ‘136.270294’ ‘Katsuyama’ ‘勝山’ ‘Fukui ken’ ‘福井縣’ ‘FORT’ ‘36.061729’ ‘136.501007’ ‘Awara’ ‘蘆原’ ‘Fukui ken’ ‘福井縣’ ‘FORT’ ‘36.211389’ ‘136.228889’ ‘Echizen’ ‘越前’ ‘Fukui ken’ ‘福井縣’ ‘FORT’ ‘35.903611’ ‘136.168611’ ‘Sakai’ ‘坂井’ ‘Fukui ken’ ‘福井縣’ ‘FORT’ ‘36.166944’ ‘136.231389’ |
| ‘Kofu’ ‘甲府’ ‘Yamanashi ken’ ‘山梨縣’ ‘CITE’ ‘35.663891’ ‘138.568329’
‘Fujiyoshida’ ‘富士吉田’ ‘Yamanashi ken’ ‘山梨縣’ ‘FORT’ ‘35.487500’ ‘138.807778’ ‘Tsuru’ ‘都留’ ‘Yamanashi ken’ ‘山梨縣’ ‘FORT’ ‘35.551667’ ‘138.905556’ ‘Yamanashi’ ‘山梨’ ‘Yamanashi ken’ ‘山梨縣’ ‘FORT’ ‘35.693333’ ‘138.686944’ ‘Otsuki’ ‘大月’ ‘Yamanashi ken’ ‘山梨縣’ ‘FORT’ ‘35.599998’ ‘138.933334’ ‘Nirasaki’ ‘韮崎’ ‘Yamanashi ken’ ‘山梨縣’ ‘FORT’ ‘35.700001’ ‘138.449997’ ‘Minamiarupusu’ ‘南阿爾卑斯’ ‘Yamanashi ken’ ‘山梨縣’ ‘FORT’ ‘35.608333’ ‘138.465000’ ‘Kai’ ‘甲斐’ ‘Yamanashi ken’ ‘山梨縣’ ‘FORT’ ‘35.660833’ ‘138.515833’ ‘Fuefuki’ ‘笛吹’ ‘Yamanashi ken’ ‘山梨縣’ ‘FORT’ ‘35.647222’ ‘138.639722’ ‘Hokuto’ ‘北杜’ ‘Yamanashi ken’ ‘山梨縣’ ‘FORT’ ‘35.776389’ ‘138.423611’ ‘Uenohara’ ‘上野原’ ‘Yamanashi ken’ ‘山梨縣’ ‘FORT’ ‘35.616669’ ‘139.116669’ ‘Koshu’ ‘甲州’ ‘Yamanashi ken’ ‘山梨縣’ ‘FORT’ ‘35.704444’ ‘138.729444’ ‘Chuo’ ‘中央’ ‘Yamanashi ken’ ‘山梨縣’ ‘FORT’ ‘35.599722’ ‘138.517222’ ‘Enzan’ ‘鹽山’ ‘Yamanashi ken’ ‘山梨縣’ ‘FORT’ ‘35.700001’ ‘138.733337’ ‘Isawa’ ‘石和’ ‘Yamanashi ken’ ‘山梨縣’ ‘HAMLET’ ‘35.650002’ ‘138.633331’ ‘Ryuo’ ‘竜王’ ‘Yamanashi ken’ ‘山梨縣’ ‘FORT’ ‘35.660279’ ‘138.506218’ ‘Kawaguchiko’ ‘河口湖’ ‘Yamanashi ken’ ‘山梨縣’ ‘LAKE’ ‘35.515000’ ‘138.756667’ ‘Fujikawaguchiko’ ‘富士河口湖’ ‘Yamanashi ken’ ‘山梨縣’ ‘FORT’ ‘35.48933’ ‘138.688324’ ‘Fuji’ ‘富士’ ‘Yamanashi ken’ ‘山梨縣’ ‘HOUSE’ ‘35.166672’ ‘138.683334’ ‘Fujisan’ ‘富士山’ ‘Yamanashi ken’ ‘山梨縣’ ‘MOUNTAIN’ ‘35.4’ ‘138.7’ |
| ‘Nagano’ ‘長野’ ‘Nagano ken’ ‘長野縣’ ‘CITE’ ‘36.65139’ ‘138.181107’
‘Matsumoto’ ‘松本’ ‘Nagano ken’ ‘長野縣’ ‘CITE’ ‘36.23333’ ‘137.966675’ ‘Ueda’ ‘上田’ ‘Nagano ken’ ‘長野縣’ ‘CITE’ ‘36.400002’ ‘138.266663’ ‘Toyoshina’ ‘豐科’ ‘Nagano ken’ ‘長野縣’ ‘FORT’ ‘36.299911’ ‘137.901077’ ‘Tatsuno’ ‘辰野’ ‘Nagano ken’ ‘長野縣’ ‘FORT’ ‘35.984261’ ‘137.997208’ ‘Nakano’ ‘中野’ ‘Nagano ken’ ‘長野縣’ ‘FORT’ ‘36.741667’ ‘138.369444’ ‘Karuizawa’ ‘輕井澤’ ‘Nagano ken’ ‘長野縣’ ‘FORT’ ‘36.348333’ ‘138.596944’ ‘Maruko’ ‘丸子’ ‘Nagano ken’ ‘長野縣’ ‘FORT’ ‘36.316669’ ‘138.266663’ ‘Komoro’ ‘小諸’ ‘Nagano ken’ ‘長野縣’ ‘FORT’ ‘36.316669’ ‘138.433334’ ‘Chino’ ‘茅野’ ‘Nagano ken’ ‘長野縣’ ‘FORT’ ‘35.9944’ ‘138.154282’ ‘Anan’ ‘阿南’ ‘Nagano ken’ ‘長野縣’ ‘FORT’ ‘33.916672’ ‘134.649994’ ‘Hotaka’ ‘穂高’ ‘Nagano ken’ ‘長野縣’ ‘HAMLET’ ‘36.3396’ ‘137.882538’ ‘Iida’ ‘飯田’ ‘Nagano ken’ ‘長野縣’ ‘CITE’ ‘35.51965’ ‘137.82074’ ‘Iiyama’ ‘飯山’ ‘Nagano ken’ ‘長野縣’ ‘FORT’ ‘36.849998’ ‘138.366669’ ‘Ina’ ‘伊那’ ‘Nagano ken’ ‘長野縣’ ‘FORT’ ‘35.82756’ ‘137.953781’ ‘Okaya’ ‘岡谷’ ‘Nagano ken’ ‘長野縣’ ‘FORT’ ‘36.056591’ ‘138.045105’ ‘Omachi’ ‘大町’ ‘Nagano ken’ ‘長野縣’ ‘FORT’ ‘36.5’ ‘137.866669’ ‘Saku’ ‘佐久’ ‘Nagano ken’ ‘長野縣’ ‘CITE’ ‘36.216671’ ‘138.483337’ ‘Shiojiri’ ‘鹽尻’ ‘Nagano ken’ ‘長野縣’ ‘FORT’ ‘36.099998’ ‘137.966675’ ‘Suwa’ ‘諏訪’ ‘Nagano ken’ ‘長野縣’ ‘FORT’ ‘36.037991’ ‘138.113083’ ‘Suzaka’ ‘須坂’ ‘Nagano ken’ ‘長野縣’ ‘FORT’ ‘36.650002’ ‘138.316666’ ‘Komagane’ ‘駒根’ ‘Nagano ken’ ‘長野縣’ ‘FORT’ ‘35.728889’ ‘137.933889’ ‘Chikuma’ ‘千曲’ ‘Nagano ken’ ‘長野縣’ ‘FORT’ ‘36.530556’ ‘138.115000’ ‘Tomi’ ‘東御’ ‘Nagano ken’ ‘長野縣’ ‘FORT’ ‘36.359444’ ‘138.330278’ ‘Azumino’ ‘安曇野’ ‘Nagano ken’ ‘長野縣’ ‘FORT’ ‘36.303889’ ‘137.905556’ |
| ‘Gifu’ ‘岐阜’ ‘Gifu ken’ ‘岐阜縣’ ‘CITE’ ‘35.422909’ ‘136.760391’
‘Godo’ ‘神戶’ ‘Gifu ken’ ‘岐阜縣’ ‘FORT’ ‘35.416672’ ‘136.600006’ ‘Gujo’ ‘郡上’ ‘Gifu ken’ ‘岐阜縣’ ‘FORT’ ‘35.736912’ ‘136.958527’ ‘Tajimi’ ‘多治見’ ‘Gifu ken’ ‘岐阜縣’ ‘CITE’ ‘35.316669’ ‘137.133331’ ‘Ogaki’ ‘大垣’ ‘Gifu ken’ ‘岐阜縣’ ‘CITE’ ‘35.349998’ ‘136.616669’ ‘Nakatsugawa’ ‘中津川’ ‘Gifu ken’ ‘岐阜縣’ ‘FORT’ ‘35.48333’ ‘137.5’ ‘Kakamigahara’ ‘各務原’ ‘Gifu ken’ ‘岐阜縣’ ‘CITE’ ‘35.416672’ ‘136.866669’ ‘Kasamatsucho’ ‘笠松町’ ‘Gifu ken’ ‘岐阜縣’ ‘FORT’ ‘35.366669’ ‘136.766663’ ‘Mino’ ‘美濃’ ‘Gifu ken’ ‘岐阜縣’ ‘FORT’ ‘35.533329’ ‘136.916672’ ‘Minokamo’ ‘美濃加茂’ ‘Gifu ken’ ‘岐阜縣’ ‘FORT’ ‘35.481991’ ‘137.021667’ ‘Mitake’ ‘御嵩町’ ‘Gifu ken’ ‘岐阜縣’ ‘FORT’ ‘35.416672’ ‘137.133331’ ‘Mizunami’ ‘瑞浪’ ‘Gifu ken’ ‘岐阜縣’ ‘FORT’ ‘35.366669’ ‘137.25’ ‘Takayama’ ‘高山’ ‘Gifu ken’ ‘岐阜縣’ ‘FORT’ ‘36.139694’ ‘137.257528’ ‘Tarui’ ‘垂井’ ‘Gifu ken’ ‘岐阜縣’ ‘FORT’ ‘35.366669’ ‘136.533325’ ‘Toki’ ‘土岐’ ‘Gifu ken’ ‘岐阜縣’ ‘FORT’ ‘35.349998’ ‘137.183334’ ‘Seki’ ‘關’ ‘Gifu ken’ ‘岐阜縣’ ‘FORT’ ‘35.495833’ ‘136.918056’ ‘Hashima’ ‘羽島’ ‘Gifu ken’ ‘岐阜縣’ ‘FORT’ ‘35.320000’ ‘136.703333’ ‘Ena’ ‘惠那’ ‘Gifu ken’ ‘岐阜縣’ ‘FORT’ ‘35.449167’ ‘137.412778’ ‘Kani’ ‘可兒’ ‘Gifu ken’ ‘岐阜縣’ ‘FORT’ ‘35.426111’ ‘137.061389’ ‘Yamagata’ ‘山縣’ ‘Gifu ken’ ‘岐阜縣’ ‘FORT’ ‘35.506111’ ‘136.781389’ ‘Mizuho’ ‘瑞穗’ ‘Gifu ken’ ‘岐阜縣’ ‘FORT’ ‘35.391944’ ‘136.690833’ ‘Motosu’ ‘本巢’ ‘Gifu ken’ ‘岐阜縣’ ‘FORT’ ‘35.483056’ ‘136.678611’ ‘Hida’ ‘飛驒’ ‘Gifu ken’ ‘岐阜縣’ ‘FORT’ ‘36.238056’ ‘137.186111’ ‘Gero’ ‘下呂’ ‘Gifu ken’ ‘岐阜縣’ ‘FORT’ ‘35.805833’ ‘137.244167’ ‘Kaizu’ ‘海津’ ‘Gifu ken’ ‘岐阜縣’ ‘FORT’ ‘35.220556’ ‘136.636389’ |
| ‘Shizuoka’ ‘靜岡’ ‘Shizuoka ken’ ‘靜岡縣’ ‘CAPITAL’ ‘34.97694’ ‘138.383057’
‘Hamamatsu’ ‘濱松’ ‘Shizuoka ken’ ‘靜岡縣’ ‘CITE’ ‘34.700001’ ‘137.733337’ ‘Numazu’ ‘沼津’ ‘Shizuoka ken’ ‘靜岡縣’ ‘CITE’ ‘35.099998’ ‘138.866669’ ‘Atami’ ‘熱海’ ‘Shizuoka ken’ ‘靜岡縣’ ‘FORT’ ‘35.089439’ ‘139.068604’ ‘Shimada’ ‘島田’ ‘Shizuoka ken’ ‘靜岡縣’ ‘CITE’ ‘34.816669’ ‘138.183334’ ‘Mishima’ ‘三島’ ‘Shizuoka ken’ ‘靜岡縣’ ‘CITE’ ‘35.116669’ ‘138.916672’ ‘Kosai’ ‘湖西’ ‘Shizuoka ken’ ‘靜岡縣’ ‘FORT’ ‘34.718399’ ‘137.531754’ ‘Kanaya’ ‘金谷’ ‘Shizuoka ken’ ‘靜岡縣’ ‘FORT’ ‘34.816669’ ‘138.133331’ ‘Ito’ ‘伊東’ ‘Shizuoka ken’ ‘靜岡縣’ ‘FORT’ ‘34.966671’ ‘139.083328’ ‘Fuji’ ‘富士’ ‘Shizuoka ken’ ‘靜岡縣’ ‘HOUSE’ ‘35.166672’ ‘138.683334’ ‘Fujieda’ ‘藤枝’ ‘Shizuoka ken’ ‘靜岡縣’ ‘FORT’ ‘34.866669’ ‘138.266663’ ‘Fujinomiya’ ‘富士宮’ ‘Shizuoka ken’ ‘靜岡縣’ ‘FORT’ ‘35.216671’ ‘138.616669’ ‘Fukuroi’ ‘袋井’ ‘Shizuoka ken’ ‘靜岡縣’ ‘FORT’ ‘34.750278’ ‘137.924722’ ‘Gotemba’ ‘御殿場’ ‘Shizuoka ken’ ‘靜岡縣’ ‘FORT’ ‘35.299999’ ‘138.933334’ ‘Haibara’ ‘榛原郡’ ‘Shizuoka ken’ ‘靜岡縣’ ‘FORT’ ‘34.533329’ ‘135.949997’ ‘Hamakita’ ‘濱北’ ‘Shizuoka ken’ ‘靜岡縣’ ‘FORT’ ‘34.799999’ ‘137.783325’ ‘Heda’ ‘戶田’ ‘Shizuoka ken’ ‘靜岡縣’ ‘HAMLET’ ‘34.966671’ ‘138.766663’ ‘Iwata’ ‘磐田’ ‘Shizuoka ken’ ‘靜岡縣’ ‘CITE’ ‘34.700001’ ‘137.850006’ ‘Kakegawa’ ‘掛川’ ‘Shizuoka ken’ ‘靜岡縣’ ‘CITE’ ‘34.76667’ ‘138.016663’ ‘Mori’ ‘森’ ‘Shizuoka ken’ ‘靜岡縣’ ‘FORT’ ‘34.833328’ ‘137.933334’ ‘Oyama’ ‘小山’ ‘Shizuoka ken’ ‘靜岡縣’ ‘FORT’ ‘34.599998’ ‘138.216675’ ‘Sagara’ ‘相良’ ‘Shizuoka ken’ ‘靜岡縣’ ‘FORT’ ‘34.683331’ ‘138.199997’ ‘Shimoda’ ‘下田’ ‘Shizuoka ken’ ‘靜岡縣’ ‘FORT’ ‘34.666672’ ‘138.949997’ ‘Yaizu’ ‘燒津’ ‘Shizuoka ken’ ‘靜岡縣’ ‘CITE’ ‘34.866669’ ‘138.333328’ ‘Ajiro’ ‘網代’ ‘Shizuoka ken’ ‘靜岡縣’ ‘FORT’ ‘35.043481’ ‘139.081411’ ‘Irozaki’ ‘石廊崎’ ‘Shizuoka ken’ ‘靜岡縣’ ‘CAPE’ ‘34.601989’ ‘138.846127’ ‘Omaezaki’ ‘御前崎’ ‘Shizuoka ken’ ‘靜岡縣’ ‘FORT’ ‘34.638056’ ‘138.128056’ ‘Susono’ ‘裾野’ ‘Shizuoka ken’ ‘靜岡縣’ ‘FORT’ ‘35.173889’ ‘138.906667’ ‘Izu’ ‘伊豆’ ‘Shizuoka ken’ ‘靜岡縣’ ‘FORT’ ‘34.976667’ ‘138.946944’ ‘Kikugawa’ ‘菊川’ ‘Shizuoka ken’ ‘靜岡縣’ ‘FORT’ ‘34.757778’ ‘138.084722’ ‘Izunokuni’ ‘伊豆之國’ ‘Shizuoka ken’ ‘靜岡縣’ ‘FORT’ ‘35.027778’ ‘138.928889’ ‘Makinohara’ ‘牧之原’ ‘Shizuoka ken’ ‘靜岡縣’ ‘FORT’ ‘34.740000’ ‘138.224722’ |
| ‘Nagoya’ ‘名古屋’ ‘Aichi ken’ ‘愛知縣’ ‘CAPITAL’ ‘35.181469’ ‘136.906403’
‘Toyohashi’ ‘豐橋’ ‘Aichi ken’ ‘愛知縣’ ‘CITE’ ‘34.76667’ ‘137.383331’ ‘Okazaki’ ‘岡崎’ ‘Aichi ken’ ‘愛知縣’ ‘CITE’ ‘34.950001’ ‘137.166672’ ‘Toyohama’ ‘豐浜’ ‘Aichi ken’ ‘愛知縣’ ‘FORT’ ‘34.700001’ ‘136.933334’ ‘Toyokawa’ ‘豐川’ ‘Aichi ken’ ‘愛知縣’ ‘CITE’ ‘34.816669’ ‘137.399994’ ‘Toyota’ ‘豐田’ ‘Aichi ken’ ‘愛知縣’ ‘CITE’ ‘35.083328’ ‘137.149994’ ‘Toyoake’ ‘豐明’ ‘Aichi ken’ ‘愛知縣’ ‘CITE’ ‘35.053611’ ‘137.012778’ ‘Anjo’ ‘安城’ ‘Aichi ken’ ‘愛知縣’ ‘FORT’ ‘34.958279’ ‘137.080536’ ‘Taketoyo’ ‘武豐’ ‘Aichi ken’ ‘愛知縣’ ‘FORT’ ‘34.849998’ ‘136.916672’ ‘Tahara’ ‘田原’ ‘Aichi ken’ ‘愛知縣’ ‘FORT’ ‘34.666672’ ‘137.266663’ ‘Seto’ ‘瀨戶’ ‘Aichi ken’ ‘愛知縣’ ‘CITE’ ‘35.23333’ ‘137.100006’ ‘Nishio’ ‘西尾’ ‘Aichi ken’ ‘愛知縣’ ‘CITE’ ‘34.866669’ ‘137.050003’ ‘Kuroda’ ‘黑田’ ‘Aichi ken’ ‘愛知縣’ ‘FORT’ ‘35.349998’ ‘136.783325’ ‘Komaki’ ‘小牧’ ‘Aichi ken’ ‘愛知縣’ ‘CITE’ ‘35.283329’ ‘136.916672’ ‘Kasugai’ ‘春日井’ ‘Aichi ken’ ‘愛知縣’ ‘CITE’ ‘35.24762’ ‘136.97229’ ‘Iwakura’ ‘岩倉’ ‘Aichi ken’ ‘愛知縣’ ‘FORT’ ‘35.283329’ ‘136.866669’ ‘Handa’ ‘半田’ ‘Aichi ken’ ‘愛知縣’ ‘CITE’ ‘34.883331’ ‘136.933334’ ‘Chita’ ‘知多’ ‘Aichi ken’ ‘愛知縣’ ‘FORT’ ‘34.996667’ ‘136.864722’ ‘Chiryu’ ‘知立’ ‘Aichi ken’ ‘愛知縣’ ‘FORT’ ‘35.001389’ ‘137.050833’ ‘Gamagori’ ‘蒲郡’ ‘Aichi ken’ ‘愛知縣’ ‘FORT’ ‘34.833328’ ‘137.233337’ ‘Hekinan’ ‘碧南’ ‘Aichi ken’ ‘愛知縣’ ‘FORT’ ‘34.883331’ ‘136.983337’ ‘Ichinomiya’ ‘一宮’ ‘Aichi ken’ ‘愛知縣’ ‘CITE’ ‘35.299999’ ‘136.800003’ ‘Inazawa’ ‘稻澤’ ‘Aichi ken’ ‘愛知縣’ ‘CITE’ ‘35.248056’ ‘136.780278’ ‘Inuyama’ ‘犬山’ ‘Aichi ken’ ‘愛知縣’ ‘FORT’ ‘35.379951’ ‘136.942947’ ‘Ishiki’ ‘一色’ ‘Aichi ken’ ‘愛知縣’ ‘FORT’ ‘34.799999’ ‘137.016663’ ‘Kanie’ ‘蟹江’ ‘Aichi ken’ ‘愛知縣’ ‘FORT’ ‘35.133331’ ‘136.800003’ ‘Kariya’ ‘刈谷’ ‘Aichi ken’ ‘愛知縣’ ‘CITE’ ‘34.98333’ ‘136.983337’ ‘Konan’ ‘江南’ ‘Aichi ken’ ‘愛知縣’ ‘CITE’ ‘35.33165’ ‘136.870422’ ‘Kozakai-cho’ ‘小坂井町’ ‘Aichi ken’ ‘愛知縣’ ‘FORT’ ‘34.799999’ ‘137.358887’ ‘Miyoshi’ ‘三好’ ‘Aichi ken’ ‘愛知縣’ ‘FORT’ ‘35.083328’ ‘137.066666’ ‘Obu’ ‘大府’ ‘Aichi ken’ ‘愛知縣’ ‘CITE’ ‘35.011667’ ‘136.963889’ ‘Shinshiro’ ‘新城’ ‘Aichi ken’ ‘愛知縣’ ‘FORT’ ‘34.898889’ ‘137.497778’ ‘Tokai’ ‘東海’ ‘Aichi ken’ ‘愛知縣’ ‘CITE’ ‘35.023056’ ‘136.902222’ ‘Owariasahi’ ‘尾張旭’ ‘Aichi ken’ ‘愛知縣’ ‘CITE’ ‘35.216667’ ‘137.035278’ ‘Nisshin’ ‘日進’ ‘Aichi ken’ ‘愛知縣’ ‘CITE’ ‘35.131944’, 137.039444 ‘Aisai’ ‘愛西’ ‘Aichi ken’ ‘愛知縣’ ‘FORT’ ‘35.152778’ ‘136.728333’ ‘Kiyosu’ ‘清須’ ‘Aichi ken’ ‘愛知縣’ ‘FORT’ ‘35.199722’ ‘136.852778’ ‘Kitanagoya’ ‘北名古屋’ ‘Aichi ken’ ‘愛知縣’ ‘FORT’ ‘35.245556’ ‘136.865833’ ‘Yatomi’ ‘彌富’ ‘Aichi ken’ ‘愛知縣’ ‘FORT’ ‘35.110000’ ‘136.724722’ ‘Ama’ ‘海部’ ‘Aichi ken’ ‘愛知縣’ ‘FORT’ ‘35.200556’ ‘136.783333’ ‘Nagakute’ ‘長久手’ ‘Aichi ken’ ‘愛知縣’ ‘FORT’ ‘35.265334’ ‘136.709274’ ‘Sobue’ ‘祖父江’ ‘Aichi ken’ ‘愛知縣’ ‘FORT’ ‘35.265334’ ‘136.709274’ ‘Takahama’ ‘高濱’ ‘Aichi ken’ ‘愛知縣’ ‘FORT’ ‘34.916672’ ‘136.983337’ ‘Tokoname’ ‘常滑’ ‘Aichi ken’ ‘愛知縣’ ‘FORT’ ‘34.883331’ ‘136.850006’ ‘Tsushima’ ‘津島’ ‘Aichi ken’ ‘愛知縣’ ‘FORT’ ‘35.166672’ ‘136.716675’ ‘Irako’ ‘伊良湖’ ‘Aichi ken’ ‘愛知縣’ ‘FORT’ ‘34.587806’ ‘137.041319’ |
| ‘Tsu’ ‘津’ ‘Mie ken’ ‘三重縣’ ‘CITE’ ‘34.730282’ ‘136.508606’
‘Tsu’ ‘津’ ‘Mie ken’ ‘三重縣’ ‘CITE’ ‘34.730282’ ‘136.508606’ ‘Yokkaichi’ ‘四日市’ ‘Mie ken’ ‘三重縣’ ‘CITE’ ‘34.966671’ ‘136.616669’ ‘Hisai’ ‘久居’ ‘Mie ken’ ‘三重縣’ ‘FORT’ ‘34.666672’ ‘136.466675’ ‘Ueno’ ‘上野’ ‘Mie ken’ ‘三重縣’ ‘CITE’ ‘34.770142’ ‘136.127142’ ‘Toba’ ‘鳥羽’ ‘Mie ken’ ‘三重縣’ ‘FORT’ ‘34.48333’ ‘136.850006’ ‘Owase’ ‘尾鷲’ ‘Mie ken’ ‘三重縣’ ‘FORT’ ‘34.066669’ ‘136.199997’ ‘Matsuzaka’ ‘松阪’ ‘Mie ken’ ‘三重縣’ ‘CITE’ ‘34.566669’ ‘136.533325’ ‘Kuwana’ ‘桑名’ ‘Mie ken’ ‘三重縣’ ‘CITE’ ‘35.066669’ ‘136.699997’ ‘Komono’ ‘菰野’ ‘Mie ken’ ‘三重縣’ ‘FORT’ ’35’ ‘136.516663’ ‘Kameyama’ ‘龜山’ ‘Mie ken’ ‘三重縣’ ‘FORT’ ‘34.849998’ ‘136.449997’ ‘Iga’ ‘伊賀’ ‘Mie ken’ ‘三重縣’ ‘FORT’ ‘34.768551’ ‘136.130127’ ‘Ise’ ‘伊勢’ ‘Mie ken’ ‘三重縣’ ‘CITE’ ‘34.48333’ ‘136.699997’ ‘Kawage’ ‘河芸’ ‘Mie ken’ ‘三重縣’ ‘FORT’ ‘34.80447’ ‘136.546448’ ‘Suzuka’ ‘鈴鹿’ ‘Mie ken’ ‘三重縣’ ‘CITE’ ‘34.883331’ ‘136.583328’ ‘Nabari’ ‘名張’ ‘Mie ken’ ‘三重縣’ ‘FORT’ ‘34.616669’ ‘136.083328’ ‘Kumano’ ‘熊野’ ‘Mie ken’ ‘三重縣’ ‘FORT’ ‘33.888889’ ‘136.100278’ ‘Inabe’ ‘員弁’ ‘Mie ken’ ‘三重縣’ ‘FORT’ ‘35.158056’ ‘136.517222’ ‘Shima’ ‘志摩’ ‘Mie ken’ ‘三重縣’ ‘FORT’ ‘34.328056’ ‘136.829722’ |
| ‘Otsu’ ‘大津’ ‘Shiga ken’ ‘滋賀縣’ ‘CITE’ ‘35.00444’ ‘135.868332’
‘Hikone’ ‘彥根’ ‘Shiga ken’ ‘滋賀縣’ ‘CITE’ ‘35.25’ ‘136.25’ ‘Hino’ ‘日野’ ‘Shiga ken’ ‘滋賀縣’ ‘FORT’ ‘35.018056’ ‘136.246111’ ‘Kusatsu’ ‘草津’ ‘Shiga ken’ ‘滋賀縣’ ‘CITE’ ‘35.01667’ ‘135.966675’ ‘Kitahama’ ‘北濱’ ‘Shiga ken’ ‘滋賀縣’ ‘FORT’ ‘35.166672’ ‘135.916672’ ‘Minakuchi’ ‘水口’ ‘Shiga ken’ ‘滋賀縣’ ‘FORT’ ‘34.966671’ ‘136.166672’ ‘Moriyama’ ‘守山’ ‘Shiga ken’ ‘滋賀縣’ ‘FORT’ ‘35.066669’ ‘135.983337’ ‘Omihachiman’ ‘近江八幡’ ‘Shiga ken’ ‘滋賀縣’ ‘FORT’ ‘35.128609’ ‘136.097595’ ‘Yasu’ ‘野洲’ ‘Shiga ken’ ‘滋賀縣’ ‘FORT’ ‘35.068008’ ‘136.02327’ ‘Youkaichi’ ‘東近江’ ‘Shiga ken’ ‘滋賀縣’ ‘CITE’ ‘35.116261’ ‘136.197678’ ‘Nagahama’ ‘長濱’ ‘Shiga ken’ ‘滋賀縣’ ‘CITE’ ‘35.383331’ ‘136.266663’ ‘Ritto’ ‘栗東’ ‘Shiga ken’ ‘滋賀縣’ ‘FORT’ ‘35.021667’ ‘135.998056’ ‘Koka’ ‘甲賀’ ‘Shiga ken’ ‘滋賀縣’ ‘FORT’ ‘34.966111’ ‘136.166389’ ‘Konan’ ‘湖南’ ‘Shiga ken’ ‘滋賀縣’ ‘FORT’ ‘35.004167’ ‘136.084722’ ‘Takashima’ ‘高島’ ‘Shiga ken’ ‘滋賀縣’ ‘FORT’ ‘35.353056’ ‘136.035833’ ‘Maibara’ ‘米原’ ‘Shiga ken’ ‘滋賀縣’ ‘FORT’ ‘35.315000’ ‘136.291667’ |
| ‘Kyoto’ ‘京都’ ‘Kyoto fu’ ‘京都府’ ‘CAPITAL’ ‘35.021069’ ‘135.753845’
‘Nagaokakyo’ ‘長岡京’ ‘Kyoto fu’ ‘京都府’ ‘FORT’ ‘34.926944’ ‘135.695833’ ‘Kyotanabe’ ‘京田邊’ ‘Kyoto fu’ ‘京都府’ ‘FORT’ ‘34.814444’ ‘135.767778’ ‘Kyotango’ ‘京丹後’ ‘Kyoto fu’ ‘京都府’ ‘FORT’ ‘35.624167’ ‘135.060833’ ‘Yawata’ ‘八幡’ ‘Kyoto fu’ ‘京都府’ ‘FORT’ ‘34.87009’ ‘135.702698’ ‘Tanabe’ ‘田邊’ ‘Kyoto fu’ ‘京都府’ ‘FORT’ ‘34.816669’ ‘135.766663’ ‘Miyazu’ ‘宮津’ ‘Kyoto fu’ ‘京都府’ ‘FORT’ ‘35.533329’ ‘135.183334’ ‘Kameoka’ ‘龜岡’ ‘Kyoto fu’ ‘京都府’ ‘FORT’ ‘35.013611’ ‘135.573611’ ‘Ayabe’ ‘綾部’ ‘Kyoto fu’ ‘京都府’ ‘FORT’ ‘35.299999’ ‘135.25’ ‘Fukuchiyama’ ‘福知山’ ‘Kyoto fu’ ‘京都府’ ‘FORT’ ‘35.299999’ ‘135.116669’ ‘Kamigyo-ku’ ‘上京區’ ‘Kyoto fu’ ‘京都府’ ‘FORT’ ‘35.029541’ ‘135.756653’ ‘Maizuru’ ‘舞鶴’ ‘Kyoto fu’ ‘京都府’ ‘FORT’ ‘35.450001’ ‘135.333328’ ‘Muko’ ‘向日’ ‘Kyoto fu’ ‘京都府’ ‘FORT’ ‘34.96545’ ‘135.704147’ ‘Uji’ ‘宇治’ ‘Kyoto fu’ ‘京都府’ ‘CITE’ ‘34.883331’ ‘135.800003’ ‘Joyo’ ‘城陽’ ‘Kyoto fu’ ‘京都府’ ‘FORT’ ‘34.853056’ ‘135.780000’ ‘Nantan’ ‘南丹’ ‘Kyoto fu’ ‘京都府’ ‘FORT’ ‘35.107500’ ‘135.470278’ ‘Kizugawa’ ‘木津川’ ‘Kyoto fu’ ‘京都府’ ‘FORT’ ‘34.737222’ ‘135.820000’ |
| ‘Osaka’ ‘大阪’ ‘Osaka-fu’ ‘大阪府’ ‘CAPITAL’ ‘34.693741’ ‘135.502182’
‘Sakai’ ‘堺’ ‘Osaka-fu’ ‘大阪府’ ‘CITE’ ‘34.583328’ ‘135.466675’ ‘Yao’ ‘八尾’ ‘Osaka-fu’ ‘大阪府’ ‘CITE’ ‘34.616669’ ‘135.600006’ ‘Moriguchi’ ‘守口’ ‘Osaka-fu’ ‘大阪府’ ‘CITE’ ‘34.73333’ ‘135.566666’ ‘Mino’ ‘箕面’ ‘Osaka-fu’ ‘大阪府’ ‘CITE’ ‘34.826908’ ‘135.470566’ ‘Kishiwada’ ‘岸和田’ ‘Osaka-fu’ ‘大阪府’ ‘CITE’ ‘34.466671’ ‘135.366669’ ‘Ibaraki’ ‘茨木’ ‘Osaka-fu’ ‘大阪府’ ‘CITE’ ‘34.81641’ ‘135.568283’ ‘Daito’ ‘大東’ ‘Osaka-fu’ ‘大阪府’ ‘FORT’ ‘34.700001’ ‘135.616669’ ‘Hirakata’ ‘枚方’ ‘Osaka-fu’ ‘大阪府’ ‘CITE’ ‘34.813519’ ‘135.649139’ ‘Ikeda’ ‘池田’ ‘Osaka-fu’ ‘大阪府’ ‘CITE’ ‘34.822079’ ‘135.429794’ ‘Suita’ ‘吹田’ ‘Osaka-fu’ ‘大阪府’ ‘CITE’ ‘34.761429’ ‘135.515671’ ‘Izumi’ ‘和泉’ ‘Osaka-fu’ ‘大阪府’ ‘CITE’ ‘34.48333’ ‘135.433334’ ‘Izumiotsu’ ‘泉大津’ ‘Osaka-fu’ ‘大阪府’ ‘FORT’ ‘34.5’ ‘135.399994’ ‘Kaizuka’ ‘貝塚’ ‘Osaka-fu’ ‘大阪府’ ‘FORT’ ‘34.450001’ ‘135.350006’ ‘Kadoma’ ‘門真’ ‘Osaka-fu’ ‘大阪府’ ‘CITE’ ‘34.73333’ ‘135.583328’ ‘Kashihara’ ‘柏原’ ‘Osaka-fu’ ‘大阪府’ ‘FORT’ ‘34.583328’ ‘135.616669’ ‘Kawanishi’ ‘川西’ ‘Osaka-fu’ ‘大阪府’ ‘FORT’ ‘34.816669’ ‘135.416672’ ‘Matsubara’ ‘松原’ ‘Osaka-fu’ ‘大阪府’ ‘CITE’ ‘34.566669’ ‘135.550003’ ‘Neyagawa’ ‘寢屋川’ ‘Osaka-fu’ ‘大阪府’ ‘CITE’ ‘34.766151’ ‘135.627594’ ‘Takaishi’ ‘高石’ ‘Osaka-fu’ ‘大阪府’ ‘FORT’ ‘34.51667’ ‘135.433334’ ‘Takatsuki’ ‘高槻’ ‘Osaka-fu’ ‘大阪府’ ‘CITE’ ‘34.848331’ ‘135.616776’ ‘Tondabayashi’ ‘富田林’ ‘Osaka-fu’ ‘大阪府’ ‘CITE’ ‘34.499722’ ‘135.597222’ ‘Toyonaka’ ‘豐中’ ‘Osaka-fu’ ‘大阪府’ ‘CITE’ ‘34.78244’ ‘135.469315’ ‘Izumisano’ ‘泉佐野’ ‘Osaka-fu’ ‘大阪府’ ‘CITE’ ‘34.406944’ ‘135.327500’ ‘Kawachinagano’ ‘河內長野’ ‘Osaka-fu’ ‘大阪府’ ‘CITE’ ‘34.458056’ ‘135.564167’ ‘Settsu’ ‘攝津’ ‘Osaka-fu’ ‘大阪府’ ‘FORT’ ‘34.777222’ ‘135.561944’ ‘Fujiidera’ ‘藤井寺’ ‘Osaka-fu’ ‘大阪府’ ‘FORT’ ‘34.574167’ ‘135.597500’ ‘Higashiosaka’ ‘東大阪’ ‘Osaka-fu’ ‘大阪府’ ‘FORT’ ‘34.679444’ ‘135.600833’ ‘Sennan’ ‘泉南’ ‘Osaka-fu’ ‘大阪府’ ‘FORT’ ‘34.365833’ ‘135.273333’ ‘Shijōnawate’ ‘四條畷’ ‘Osaka-fu’ ‘大阪府’ ‘FORT’ ‘34.740000’ ‘135.639444’ ‘Katano’ ‘交野’ ‘Osaka-fu’ ‘大阪府’ ‘FORT’ ‘34.788056’ ‘135.680000’ ‘Osakasayama’ ‘大阪狹山’ ‘Osaka-fu’ ‘大阪府’ ‘FORT’ ‘34.503611’ ‘135.555556’ ‘Hannan’ ‘阪南’ ‘Osaka-fu’ ‘大阪府’ ‘FORT’ ‘34.359444’ ‘135.239722’ |
| ‘Kobe’ ‘神戶’ ‘Hyogo-ken’ ‘兵庫縣’ ‘CAPITAL’ ‘34.691299’ ‘135.182999’
‘Himeji’ ‘姫路’ ‘Hyogo-ken’ ‘兵庫縣’ ‘CITE’ ‘34.816669’ ‘134.699997’ ‘Amagasaki’ ‘尼崎’ ‘Hyogo-ken’ ‘兵庫縣’ ‘CITE’ ‘34.716671’ ‘135.416672’ ‘Akashi’ ‘明石’ ‘Hyogo-ken’ ‘兵庫縣’ ‘CITE’ ‘34.633331’ ‘134.983337’ ‘Nishinomiya’ ‘西宮’ ‘Hyogo-ken’ ‘兵庫縣’ ‘CITE’ ‘34.716671’ ‘135.333328’ ‘Kakogawa’ ‘加古川’ ‘兵庫縣’ ‘CITE’ ‘34.76667’ ‘134.850006’ ‘Sumoto’ ‘洲本’ ‘Hyogo-ken’ ‘兵庫縣’ ‘FORT’ ‘34.349998’ ‘134.899994’ ‘Ashiya’ ‘蘆屋’ ‘兵庫縣’ ‘FORT’ ‘34.728069’ ‘135.302643’ ‘Yamasaki’ ‘山崎’ ‘Hyogo-ken’ ‘兵庫縣’ ‘FORT’ ‘35.002889’ ‘134.539640’ ‘Tatsuno’ ‘龍野’ ‘Hyogo-ken’ ‘兵庫縣’ ‘FORT’ ‘34.866669’ ‘134.550003’ ‘Takarazuka’ ‘寶塚’ ‘Hyogo-ken’ ‘兵庫縣’ ‘CITE’ ‘34.799358’ ‘135.356964’ ‘Sanda’ ‘三田’ ‘Hyogo-ken’ ‘兵庫縣’ ‘CITE’ ‘34.883331’ ‘135.233337’ ‘Miki’ ‘三木’ ‘Hyogo-ken’ ‘兵庫縣’ ‘FORT’ ‘34.799999’ ‘134.983337’ ‘Aioi’ ‘相生’ ‘Hyogo-ken’ ‘兵庫縣’ ‘FORT’ ‘34.803612’ ‘134.468063’ ‘Ako’ ‘赤穗’ ‘Hyogo-ken’ ‘兵庫縣’ ‘FORT’ ‘34.75’ ‘134.399994’ ‘Itami’ ‘伊丹’ ‘Hyogo-ken’ ‘兵庫縣’ ‘CITE’ ‘34.784271’ ‘135.40126’ ‘Nishiwaki’ ‘西脇’ ‘Hyogo-ken’ ‘兵庫縣’ ‘FORT’ ‘34.98333’ ‘134.966675’ ‘Ono’ ‘小野’ ‘Hyogo-ken’ ‘兵庫縣’ ‘FORT’ ‘34.849998’ ‘134.933334’ ‘Sasayama’ ‘篠山’ ‘Hyogo-ken’ ‘兵庫縣’ ‘FORT’ ‘35.066669’ ‘135.216675’ ‘Tambasasayama’ ‘丹波篠山’ ‘Hyogo-ken’ ‘兵庫縣’ ‘CITE’ ‘35.075833’ ‘135.219167’ ‘Shirahama’ ‘白浜’ ‘Hyogo-ken’ ‘兵庫縣’ ‘FORT’ ‘34.783329’ ‘134.716675’ ‘Toyooka’ ‘豐岡’ ‘Hyogo-ken’ ‘兵庫縣’ ‘FORT’ ‘35.533329’ ‘134.833328’ ‘Yashiro’ ‘社’ ‘Hyogo-ken’ ‘兵庫縣’ ‘FORT’ ‘34.916672’ ‘134.966675’ ‘Takasago’ ‘高砂’ ‘Hyogo-ken’ ‘兵庫縣’ ‘FORT’ ‘34.765833’ ‘134.790556’ ‘Kawanishi’ ‘川西’ ‘Hyogo-ken’ ‘兵庫縣’ ‘CITE’ ‘34.830278’ ‘135.417222’ ‘Kasai’ ‘加西’ ‘Hyogo-ken’ ‘兵庫縣’ ‘CITE’ ‘34.927778’ ‘134.841944’ ‘Kato’ ‘加東’ ‘Hyogo-ken’ ‘兵庫縣’ ‘CITE’ ‘34.918591’ ‘134.973448’ ‘Yabu’ ‘養父’ ‘Hyogo-ken’ ‘兵庫縣’ ‘FORT’ ‘35.404722’ ‘134.767500’ ‘Tanba’ ‘丹波’ ‘Hyogo-ken’ ‘兵庫縣’ ‘FORT’ ‘35.176944’ ‘135.035833’ ‘Minamiawaji’ ‘南淡路’ ‘Hyogo-ken’ ‘兵庫縣’ ‘FORT’ ‘34.294444’ ‘134.779722’ ‘Awaji’ ‘淡路’ ‘Hyogo-ken’ ‘兵庫縣’ ‘FORT’ ‘34.439722’ ‘134.915000’ ‘Asago’ ‘朝來’ ‘Hyogo-ken’ ‘兵庫縣’ ‘FORT’ ‘35.339722’ ‘134.853056’ ‘Shiso’ ‘宍粟’ ‘Hyogo-ken’ ‘兵庫縣’ ‘FORT’ ‘35.004444’ ‘134.549444’ |
| ‘Nara’ ‘奈良’ ‘Nara-ken’ ‘奈良縣’ ‘CITE’ ‘34.685051’ ‘135.804855’
‘Yamatotakada’ ‘大和高田’ ‘Nara-ken’ ‘奈良縣’ ‘FORT’ ‘34.515000’ ‘135.736389’ ‘Yamatokoriyama’ ‘大和郡山’ ‘Nara-ken’ ‘奈良縣’ ‘CITE’ ‘34.649444’ ‘135.782778’ ‘Tenri’ ‘天理’ ‘Nara-ken’ ‘奈良縣’ ‘FORT’ ‘34.583328’ ‘135.833328’ ‘Kashihara’ ‘橿原’ ‘Nara-ken’ ‘奈良縣’ ‘CITE’ ‘34.508961’ ‘135.792892’ ‘Sakurai’ ‘櫻井’ ‘Nara-ken’ ‘奈良縣’ ‘FORT’ ‘34.518611’ ‘135.843333’ ‘Gojo’ ‘五條’ ‘Nara-ken’ ‘奈良縣’ ‘FORT’ ‘34.349998’ ‘135.699997’ ‘Gose’ ‘御所’ ‘Nara-ken’ ‘奈良縣’ ‘FORT’ ‘34.450001’ ‘135.733337’ ‘Ikoma’ ‘生駒’ ‘Nara-ken’ ‘奈良縣’ ‘CITE’ ‘34.683331’ ‘135.699997’ ‘Kashiba’ ‘香芝’ ‘Nara-ken’ ‘奈良縣’ ‘FORT’ ‘34.541389’ ‘135.699167’ ‘Katsuragi’ ‘葛城’ ‘Nara-ken’ ‘奈良縣’ ‘FORT’ ‘34.489167’ ‘135.726389’ ‘Uda’ ‘宇陀’ ‘Nara-ken’ ‘奈良縣’ ‘FORT’ ‘34.528056’ ‘135.952222’ ‘Yoshino-cho’ ‘吉野町’ ‘Nara-ken’ ‘奈良縣’ ‘FORT’ ‘34.396111’ ‘135.857681’ ‘Tawaramoto’ ‘田原本’ ‘Nara-ken’ ‘奈良縣’ ‘FORT’ ‘34.549999’ ‘135.800003’ |
| ‘Wakayama’ ‘和歌山’ ‘Wakayama ken’ ‘和歌山縣’ ‘CITE’ ‘34.226109’ ‘135.167496’
‘Shingu’ ‘新宮’ ‘Wakayama ken’ ‘和歌山縣’ ‘FORT’ ‘33.73333’ ‘135.983337’ ‘Kainan’ ‘海南’ ‘Wakayama ken’ ‘和歌山縣’ ‘FORT’ ‘34.150002’ ‘135.199997’ ‘Tanabe’ ‘田邊’ ‘Wakayama ken’ ‘和歌山縣’ ‘FORT’ ‘33.73333’ ‘135.366669’ ‘Gobo’ ‘御坊’ ‘Wakayama ken’ ‘和歌山縣’ ‘FORT’ ‘33.883331’ ‘135.149994’ ‘Hashimoto’ ‘橋本’ ‘Wakayama ken’ ‘和歌山縣’ ‘FORT’ ‘34.316669’ ‘135.616669’ ‘Arida’ ‘有田’ ‘Wakayama ken’ ‘和歌山縣’ ‘FORT’ ‘34.083056’ ‘135.127778’ ‘Kinokawa’ ‘紀之川’ ‘Wakayama ken’ ‘和歌山縣’ ‘FORT’ ‘34.269722’ ‘135.362778’ ‘Iwade’ ‘岩出’ ‘Wakayama ken’ ‘和歌山縣’ ‘FORT’ ‘34.256389’ ‘135.311389’ ‘Shionomisaki’ ‘潮岬’ ‘Wakayama ken’ ‘和歌山縣’ ‘CAPE’ ‘33.433056’ ‘135.762500’ ‘Shimminatocho’ 新湊町’ ‘Wakayama ken’ ‘和歌山縣’ ‘FORT’ ‘34.183331’ ‘135.199997’ ‘Koya’ ‘高野’ ‘Wakayama ken’ ‘和歌山縣’ ‘FORT’ ‘34.21294’ ‘135.622437’ |
| ‘Tottori’ ‘鳥取’ ‘Tottori ken’ ‘鳥取縣’ ‘CITE’ ‘35.494444’ ‘134.221667’
‘Yonago’ ‘米子’ ‘Tottori ken’ ‘鳥取縣’ ‘CITE’ ‘35.433331’ ‘133.333328’ ‘Kurayoshi’ ‘倉吉’ ‘Tottori ken’ ‘鳥取縣’ ‘FORT’ ‘35.433331’ ‘133.816666’ ‘Sakaiminato’ ‘境港’ ‘Tottori ken’ ‘鳥取縣’ ‘FORT’ ‘35.539722’ ‘133.231667’ |
| ‘Matsue’ ‘松江’ ‘Shimane ken’ ‘島根縣’ ‘CITE’ ‘35.472221’ ‘133.050568’
‘Hamada’ ‘濱田’ ‘Shimane ken’ ‘島根縣’ ‘FORT’ ‘34.883331’ ‘132.083328’ ‘Izumo’ ‘出雲’ ‘Shimane ken’ ‘島根縣’ ‘CITE’ ‘35.366669’ ‘132.766663’ ‘Masuda’ ‘益田’ ‘Shimane ken’ ‘島根縣’ ‘FORT’ ‘34.666672’ ‘131.850006’ ‘Oda’ ‘大田’ ‘Shimane ken’ ‘島根縣’ ‘FORT’ ‘35.191944’ ‘132.499444’ ‘Yasugi’ ‘安來’ ‘Shimane ken’ ‘島根縣’ ‘FORT’ ‘35.431389’ ‘133.250833’ ‘Gotsu’ ‘江津’ ‘Shimane ken’ ‘島根縣’ ‘FORT’ ‘35.011667’ ‘132.217778’ ‘Unnan’ ‘雲南’ ‘Shimane ken’ ‘島根縣’ ‘FORT’ ‘35.307778’ ‘132.900278’ ‘Saigo’ ‘西郷’ ‘Shimane ken’ ‘島根縣’ ‘FORT’ ‘36.204631’ ‘133.333009’ ‘Hirata’ ‘平田’ ‘Shimane ken’ ‘島根縣’ ‘HAMLET’ ‘35.433331’ ‘132.816666’ |
| ‘Okayama’ ‘岡山’ ‘Okayama ken’ ‘岡山縣’ ‘CITE’ ‘34.661671’ ‘133.934998’
‘Kurashiki’ ‘倉敷’ ‘Okayama ken’ ‘岡山縣’ ‘CITE’ ‘34.583328’ ‘133.766663’ ‘Tsuyama’ ‘津山’ ‘Okayama ken’ ‘岡山縣’ ‘CITE’ ‘35.062769’ ‘134.004953’ ‘Tamano’ ‘玉野’ ‘Okayama ken’ ‘岡山縣’ ‘FORT’ ‘34.48333’ ‘133.949997’ ‘Kasaoka’ ‘笠岡’ ‘Okayama ken’ ‘岡山縣’ ‘FORT’ ‘34.5’ ‘133.5’ ‘Ibara’ ‘井原’ ‘Okayama ken’ ‘岡山縣’ ‘FORT’ ‘34.599998’ ‘133.466675’ ‘Soja’ ‘總社’ ‘Okayama ken’ ‘岡山縣’ ‘FORT’ ‘34.672778’ ‘133.746389’ ‘Takahashi’ ‘高梁’ ‘Okayama ken’ ‘岡山縣’ ‘FORT’ ‘34.783329’ ‘133.616669’ ‘Niimi’ ‘新見’ ‘Okayama ken’ ‘岡山縣’ ‘FORT’ ‘34.98333’ ‘133.466675’ ‘Bizen’ ‘備前’ ‘Okayama ken’ ‘岡山縣’ ‘FORT’ ‘34.745278’ ‘134.188889’ ‘Setouchi’ ‘瀨戶內’ ‘Okayama ken’ ‘岡山縣’ ‘FORT’ ‘34.665000’ ‘134.092778’ ‘Akaiwa’ ‘赤磐’ ‘Okayama ken’ ‘岡山縣’ ‘FORT’ ‘34.755278’ ‘134.018889’ ‘Maniwa’ ‘真庭’ ‘Okayama ken’ ‘岡山縣’ ‘FORT’ ‘35.075556’ ‘133.752778’ ‘Mimasaka’ ‘美作’ ‘Okayama ken’ ‘岡山縣’ ‘FORT’ ‘35.008611’ ‘134.148611’ ‘Asakuchi’ ‘淺口’ ‘Okayama ken’ ‘岡山縣’ ‘FORT’ ‘34.527778’ ‘133.584722’ ‘Kamogata’ ‘鴨方’ ‘Okayama ken’ ‘岡山縣’ ‘FORT’ ‘34.533329’ ‘133.583328’ |
| ‘Hiroshima’ ‘廣島’ ‘Hiroshima ken’ ‘廣島縣’ ‘CITE’ ‘34.396271’ ‘132.459366’
‘Onomichi’ ‘尾道’ ‘Hiroshima ken’ ‘廣島縣’ ‘CITE’ ‘34.416672’ ‘133.199997’ ‘Kure’ ‘吳市’ ‘Hiroshima ken’ ‘廣島縣’ ‘CITE’ ‘34.23333’ ‘132.566666’ ‘Fukuyama’ ‘福山’ ‘Hiroshima ken’ ‘廣島縣’ ‘CITE’ ‘34.48333’ ‘133.366669’ ‘Mihara’ ‘三原’ ‘Hiroshima ken’ ‘廣島縣’ ‘FORT’ ‘34.400002’ ‘133.083328’ ‘Fuchu’ ‘府中’ ‘Hiroshima ken’ ‘廣島縣’ ‘FORT’ ‘34.566669’ ‘133.233337’ ‘Miyoshi’ ‘三次’ ‘Hiroshima ken’ ‘廣島縣’ ‘FORT’ ‘34.799999’ ‘132.850006’ ‘Shobara’ ‘庄原’ ‘Hiroshima ken’ ‘廣島縣’ ‘FORT’ ‘34.849998’ ‘133.016663’ ‘Otake’ ‘大竹’ ‘Hiroshima ken’ ‘廣島縣’ ‘FORT’ ‘34.237778’ ‘132.222222’ ‘Takehara’ ‘竹原’ ‘Hiroshima ken’ ‘廣島縣’ ‘FORT’ ‘34.338329’ ‘132.916672’ ‘Higashihiroshima’ ‘東廣島’ ‘Hiroshima ken’ ‘廣島縣’ ‘CITE’ ‘34.426389’ ‘132.743333’ ‘Hatsukaichi’ ‘廿日市’ ‘Hiroshima ken’ ‘廣島縣’ ‘CITE’ ‘34.349998’ ‘132.333328’ ‘Akitakata’ ‘安藝高田’ ‘Hiroshima ken’ ‘廣島縣’ ‘FORT’ ‘34.666111’ ‘132.704444’ ‘Etajima’ ‘江田島’ ‘Hiroshima ken’ ‘廣島縣’ ‘FORT’ ‘34.175000’ ‘132.462222’ ‘Shinichi’ ‘新市’ ‘Hiroshima ken’ ‘廣島縣’ ‘FORT’ ‘34.549999’ ‘133.266663’ ‘Ono’ ‘大野’ ‘Hiroshima ken’ ‘廣島縣’ ‘FORT’ ‘34.283329’ ‘132.266663’ ‘Miyajima’ ‘宮島’ ‘Hiroshima ken’ ‘廣島縣’ ‘FORT’ ‘34.30183’ ‘132.326126’ ‘Innoshima’ ‘因島’ ‘Hiroshima ken’ ‘廣島縣’ ‘FORT’ ‘34.283329’ ‘133.183334’ ‘Kaita’ ‘海田’ ‘Hiroshima ken’ ‘廣島縣’ ‘FORT’ ‘34.366669’ ‘132.550003’ ‘Kannabe’ ‘神邊’ ‘Hiroshima ken’ ‘廣島縣’ ‘FORT’ ‘34.533329’ ‘133.383331’ |
| ‘Shimonoseki’ ‘下關’ ‘Yamaguchi ken’ ‘山口縣’ ‘CITE’ ‘33.950001’ ‘130.949997’
‘Ube’ ‘宇部’ ‘Yamaguchi ken’ ‘山口縣’ ‘CITE’ ‘33.943062’ ‘131.251114’ ‘Yamaguchi’ ‘山口’ ‘Yamaguchi ken’ ‘山口縣’ ‘CITE’ ‘34.185829’ ‘131.47139’ ‘Hagi’ ‘萩’ ‘Yamaguchi ken’ ‘山口縣’ ‘FORT’ ‘34.400002’ ‘131.416672’ ‘Hikari’ ‘光’ ‘Yamaguchi ken’ ‘山口縣’ ‘FORT’ ‘33.955002’ ‘131.949997’ ‘Onoda’ ‘小野田’ ‘Yamaguchi ken’ ‘山口縣’ ‘FORT’ ‘34.001389’ ‘131.183609’ ‘Hofu’ ‘防府’ ‘Yamaguchi ken’ ‘山口縣’ ‘CITE’ ‘34.049999’ ‘131.566666’ ‘Iwakuni’ ‘岩國’ ‘Yamaguchi ken’ ‘山口縣’ ‘CITE’ ‘34.150002’ ‘132.183334’ ‘Kudamatsu’ ‘下松’ ‘Yamaguchi ken’ ‘山口縣’ ‘FORT’ ‘34.015000’ ‘131.870278’ ‘Nagato’ ‘長門’ ‘Yamaguchi ken’ ‘山口縣’ ‘FORT’ ‘34.383331’ ‘131.199997’ ‘Ogori’ ‘小郡’ ‘Yamaguchi ken’ ‘山口縣’ ‘CITE’ ‘34.099998’ ‘131.399994’ ‘Otake’ ‘大竹’ ‘Yamaguchi ken’ ‘山口縣’ ‘HAMLET’ ‘34.200001’ ‘132.216675’ ‘Yanai’ ‘柳井’ ‘Yamaguchi ken’ ‘山口縣’ ‘FORT’ ‘33.966671’ ‘132.116669’ ‘Mine’ ‘美禰’ ‘Yamaguchi ken’ ‘山口縣’ ‘FORT’ ‘34.166667’ ‘131.205556’ ‘Tokuyama’ ‘周南’ ‘Yamaguchi ken’ ‘山口縣’ ‘CITE’ ‘34.049999’ ‘131.816666’ ‘Sanyoonoda’ ‘山陽小野田’ ‘Yamaguchi ken’ ‘山口縣’ ‘FORT’ ‘34.003056’ ‘131.181944’ |
| ‘Tokushima’ ‘德島’ ‘Tokushima ken’ ‘德島縣’ ‘CITE’ ‘34.06583’ ‘134.559433’
‘Naruto’ ‘鳴門’ ‘Tokushima ken’ ‘德島縣’ ‘FORT’ ‘34.183331’ ‘134.616669’ ‘Komatsushima’ ‘小松島’ ‘Tokushima ken’ ‘德島縣’ ‘FORT’ ‘34.005000’ ‘134.590556’ ‘Annan’ ‘阿南’ ‘Tokushima ken’ ‘德島縣’ ‘FORT’ ‘33.921667’ ‘134.659444’ ‘Yoshinogawa’ ‘吉野川’ ‘Tokushima ken’ ‘德島縣’ ‘FORT’ ‘34.066389’ ‘134.358611’ ‘Mima’ ‘美馬’ ‘Tokushima ken’ ‘德島縣’ ‘FORT’ ‘34.053333’ ‘134.169722’ ‘Awa’ ‘阿波’ ‘Tokushima ken’ ‘德島縣’ ‘FORT’ ‘34.102222’ ‘134.297500’ ‘Miyoshi’ ‘三好’ ‘Tokushima ken’ ‘德島縣’ ‘FORT’ ‘34.026111’ ‘133.807222’ ‘Waki’ ‘脇’ ‘Tokushima ken’ ‘德島縣’ ‘FORT’ ‘34.066669’ ‘134.149994’ ‘Ishii’ ‘石井’ ‘Tokushima ken’ ‘德島縣’ ‘FORT’ ‘34.066669’ ‘134.433334’ ‘Ikeda’ ‘池田’ ‘Tokushima ken’ ‘德島縣’ ‘FORT’ ‘34.01667’ ‘133.800003’ ‘Kamojima’ ‘鴨島’ ‘Tokushima ken’ ‘德島縣’ ‘FORT’ ‘34.066669’ ‘134.350006’ |
| ‘Takamatsu’ ‘高松’ ‘Kagawa ken’ ‘香川縣’ ‘CAPITAL’ ‘34.340279’ ‘134.043335’
‘Marugame’ ‘丸龜’ ‘Kagawa ken’ ‘香川縣’ ‘CITE’ ‘34.283329’ ‘133.783325’ ‘Sakaide’ ‘坂出’ ‘Kagawa ken’ ‘香川縣’ ‘FORT’ ‘34.316669’ ‘133.850006’ ‘Zentsuji’ ‘善通寺’ ‘Kagawa ken’ ‘香川縣’ ‘FORT’ ‘34.228611’ ‘133.787222’ ‘Kanonji’ ‘觀音寺’ ‘Kagawa ken’ ‘香川縣’ ‘FORT’ ‘34.116669’ ‘133.649994’ ‘Sanuki’ ‘讚岐’ ‘Kagawa ken’ ‘香川縣’ ‘FORT’ ‘34.325278’ ‘134.171944’ ‘Higashikagawa’ ‘東香川’ ‘Kagawa ken’ ‘香川縣’ ‘FORT’ ‘34.243889’ ‘134.358889’ ‘Mitoyo’ ‘三豐’ ‘Kagawa ken’ ‘香川縣’ ‘FORT’ ‘34.182778’ ‘133.715000’ ‘Shido’ ‘志度’ ‘Kagawa ken’ ‘香川縣’ ‘FORT’ ‘34.32333’ ‘134.173325’ ‘Tadotsu’ ‘多度津’ ‘Kagawa ken’ ‘香川縣’ ‘FORT’ ‘34.275002’ ‘133.75’ ‘Tonosho’ ‘土庄’ ‘Kagawa ken’ ‘香川縣’ ‘FORT’ ‘34.48333’ ‘134.183334’ |
| ‘Matsuyama’ ‘松山’ ‘Ehime-ken’ ‘愛媛縣’ ‘CITE’ ‘33.839161’ ‘132.765747’
‘Imabari’ ‘今治’ ‘Ehime-ken’ ‘愛媛縣’ ‘CITE’ ‘34.066111’ ‘132.997778’ ‘Uwajima’ ‘宇和島’ ‘Ehime-ken’ ‘愛媛縣’ ‘FORT’ ‘33.223751’ ‘132.560013’ ‘Yawatahama’ ‘八幡濱’ ‘Ehime-ken’ ‘愛媛縣’ ‘FORT’ ‘33.462778’ ‘132.423333 ‘ ‘Niihama’ ‘新居濱’ ‘Ehime-ken’ ‘愛媛縣’ ‘CITE’ ‘33.959332’ ‘133.316727’ ‘Saijo’ ‘西條’ ‘Ehime-ken’ ‘愛媛縣’ ‘CITE’ ‘33.916672’ ‘133.183334’ ‘Hojo’ ‘北條’ ‘Ehime-ken’ ‘愛媛縣’ ‘HAMLET’ ‘33.976608’ ‘132.777664’ ‘Ozu’ ‘大洲’ ‘Ehime-ken’ ‘愛媛縣’ ‘FORT’ ‘33.509539’ ‘132.541131’ ‘Iyo’ ‘伊予’ ‘Ehime-ken’ ‘愛媛縣’ ‘FORT’ ‘33.751389’ ‘132.701385’ ‘Seiyo’ ‘西予’ ‘Ehime-ken’ ‘愛媛縣’ ‘FORT’ ‘33.362778’ ‘132.510833’ ‘Shikokuchuo’ ‘四國中央’ ‘Ehime-ken’ ‘愛媛縣’ ‘CITE’ ‘33.980833’ ‘133.549167’ ‘Kawanoe’ ‘川之江’ ‘Ehime-ken’ ‘愛媛縣’ ‘FORT’ ‘34.01667’ ‘133.566666’ ‘Masaki-cho’ ‘松前町’ ‘Ehime-ken’ ‘愛媛縣’ ‘FORT’ ‘33.787571’ ‘132.711243’ ‘Kihoku-cho’ ‘鬼北町’ ‘Ehime-ken’ ‘愛媛縣’ ‘HAMLET’ ‘33.25592’ ‘132.683426’ |
| ‘Kochi’ ‘高知’ ‘Kochi-ken’ ‘高知縣’ ‘CITE’ ‘33.559719’ ‘133.531113’
‘Sukumo’ ‘宿毛’ ‘Kochi-ken’ ‘高知縣’ ‘FORT’ ‘32.933331’ ‘132.733337’ ‘Tosashimizu’ ‘土佐清水’ ‘Kochi-ken’ ‘高知縣’ ‘FORT’ ‘32.781389’ ‘132.955000’ ‘Aki’ ‘安藝’ ‘Kochi-ken’ ‘高知縣’ ‘FORT’ ‘33.516389’ ‘133.906111’ ‘Susaki’ ‘須崎’ ‘Kochi-ken’ ‘高知縣’ ‘FORT’ ‘33.366669’ ‘133.283325’ ‘Tosa’ ‘土佐’ ‘Kochi-ken’ ‘高知縣’ ‘FORT’ ‘33.496111’ ‘133.425278’ ‘Muroto’ ‘室戶’ ‘Kochi-ken’ ‘高知縣’ ‘FORT’ ‘33.283329’ ‘134.149994’ ‘Nankoku’ ‘南國’ ‘Kochi-ken’ ‘高知縣’ ‘FORT’ ‘33.575556’ ‘133.641389’ ‘Shimanto’ ‘四萬十’ ‘Kochi-ken’ ‘高知縣’ ‘FORT’ ‘32.991389’ ‘132.933611’ ‘Konan’ ‘香南’ ‘Kochi-ken’ ‘高知縣’ ‘FORT’ ‘33.564167’ ‘133.700556’ ‘Kami’ ‘香美’ ‘Kochi-ken’ ‘高知縣’ ‘FORT’ ‘33.603611’ ‘133.686111’ ‘Shimizu’ ‘清水’ ‘Kochi-ken’ ‘高知縣’ ‘FORT’ ‘32.773246’ ‘132.949666’ ‘Nakamura’ ‘中村’ ‘Kochi-ken’ ‘高知縣’ ‘FORT’ ‘32.98333’ ‘132.933334’ ‘Ino’ ‘伊野’ ‘Kochi-ken’ ‘高知縣’ ‘FORT’ ‘33.549999’ ‘133.433334’ |
| ‘Fukuoka’ ‘福岡’ ‘Fukuoka-ken’ ‘福岡縣’ ‘CITE’ ‘33.606392’ ‘130.41806’
‘Kurume’ ‘久留米’ ‘Fukuoka-ken’ ‘福岡縣’ ‘CITE’ ‘33.316669’ ‘130.516663’ ‘Omuta’ ‘大牟田’ ‘Fukuoka-ken’ ‘福岡縣’ ‘CITE’ ‘33.033329’ ‘130.449997’ ‘Nogata’ ‘直方’ ‘Fukuoka-ken’ ‘福岡縣’ ‘FORT’ ‘33.73333’ ‘130.733337’ ‘Iizuka’ ‘飯塚’ ‘Fukuoka-ken’ ‘福岡縣’ ‘CITE’ ‘33.633331’ ‘130.683334’ ‘Tagawa’ ‘田川’ ‘Fukuoka-ken’ ‘福岡縣’ ‘FORT’ ‘33.638889’ ‘130.806111’ ‘Yanagawa’ ‘柳川’ ‘Fukuoka-ken’ ‘福岡縣’ ‘FORT’ ‘33.166672’ ‘130.399994’ ‘Asakura’ ‘朝倉’ ‘Fukuoka-ken’ ‘福岡縣’ ‘FORT’ ‘33.423333’ ‘130.665556’ ‘Yame’ ‘八女’ ‘Fukuoka-ken’ ‘福岡縣’ ‘FORT’ ‘33.211944’ ‘130.557778’ ‘Chikugo’ ‘筑後’ ‘Fukuoka-ken’ ‘福岡縣’ ‘FORT’ ‘33.212222’ ‘130.501944’ ‘Okawa’ ‘大川’ ‘Fukuoka-ken’ ‘福岡縣’ ‘FORT’ ‘33.200001’ ‘130.350006’ ‘Yukuhashi’ ‘行橋’ ‘Fukuoka-ken’ ‘福岡縣’ ‘FORT’ ‘33.728729’ ‘130.983002’ ‘Buzen’ ‘豐前’ ‘Fukuoka-ken’ ‘福岡縣’ ‘FORT’ ‘33.61153’ ‘131.13002’ ‘Nakama’ ‘中間’ ‘Fukuoka-ken’ ‘福岡縣’ ‘FORT’ ‘33.816669’ ‘130.699997’ ‘Kitakyushu’ ‘北九州’ ‘Fukuoka-ken’ ‘福岡縣’ ‘CITE’ ‘33.833328’ ‘130.833328’ ‘Ogori’ ‘小郡’ ‘Fukuoka-ken’ ‘福岡縣’ ‘FORT’ ‘33.396389’ ‘130.555556’ ‘Chikushino’ ‘筑紫野’ ‘Fukuoka-ken’ ‘福岡縣’ ‘FORT’ ‘33.496311’ ‘130.515594’ ‘Kasuga’ ‘春日’ ‘Fukuoka-ken’ ‘福岡縣’ ‘CITE’ ‘33.532778’ ‘130.470278’ ‘Onojo’ ‘大野城’ ‘Fukuoka-ken’ ‘福岡縣’ ‘CITE’ ‘33.535671’ ‘130.478607’ ‘Munakata’ ‘宗像’ ‘Fukuoka-ken’ ‘福岡縣’ ‘CITE’ ‘33.805556’ ‘130.540833’ ‘Dazaifu’ ‘太宰府’ ‘Fukuoka-ken’ ‘福岡縣’ ‘FORT’ ‘33.512778’ ‘130.523889’ ‘Koga’ ‘古賀’ ‘Fukuoka-ken’ ‘福岡縣’ ‘FORT’ ‘33.73333’ ‘130.466675’ ‘Fukutsu’ ‘福津’ ‘Fukuoka-ken’ ‘福岡縣’ ‘FORT’ ‘33.766944’ ‘130.491111’ ‘Ukiha’ ‘浮羽’ ‘Fukuoka-ken’ ‘福岡縣’ ‘FORT’ ‘33.347500’ ‘130.755000’ ‘Miyawaka’ ‘宮若’ ‘Fukuoka-ken’ ‘福岡縣’ ‘FORT’ ‘33.723611’ ‘130.667500’ ‘Kama’ ‘嘉麻’ ‘Fukuoka-ken’ ‘福岡縣’ ‘FORT’ ‘33.598333’ ‘130.719444’ ‘Miyama’ ‘三山’ ‘Fukuoka-ken’ ‘福岡縣’ ‘FORT’ ‘33.152500’ ‘130.474722’ ‘Itoshima’ ‘絲島’ ‘Fukuoka-ken’ ‘福岡縣’ ‘CITE’ ‘33.557222’ ‘130.195556’ ‘Nakagawa’ ‘那珂川’ ‘Fukuoka-ken’ ‘福岡縣’ ‘FORT’ ‘33.499444’ ‘130.422222’ ‘Amagi’ ‘甘木’ ‘Fukuoka-ken’ ‘福岡縣’ ‘FORT’ ‘33.416672’ ‘130.649994’ ‘Fukuma’ ‘福間’ ‘Fukuoka-ken’ ‘福岡縣’ ‘HAMLET’ ‘33.76667’ ‘130.466675’ ‘Yoshitomi’ ‘吉富’ ‘Fukuoka-ken’ ‘福岡縣’ ‘HAMLET’ ‘33.60247’ ‘131.175995’ ‘Umi’ ‘宇美’ ‘Fukuoka-ken’ ‘福岡縣’ ‘FORT’ ‘33.567500’ ‘130.511111’ ‘Sasaguri’ ‘篠栗’ ‘Fukuoka-ken’ ‘福岡縣’ ‘FORT’ ‘33.616669’ ‘130.533325’ ‘Kawasaki’ ‘川崎’ ‘Fukuoka-ken’ ‘福岡縣’ ‘FORT’ ‘33.583328’ ‘130.833328’ ‘Kanda’ ‘苅田’ ‘Fukuoka-ken’ ‘福岡縣’ ‘FORT’ ‘33.783329’ ‘130.983337’ ‘Maebaru’ ‘前原’ ‘Fukuoka-ken’ ‘福岡縣’ ‘FORT’ ‘33.549999’ ‘130.199997’ ‘Miyada’ ‘宮田’ ‘Fukuoka-ken’ ‘福岡縣’ ‘FORT’ ‘33.716671’ ‘130.666672’ ‘Shiida’ ‘椎田’ ‘Fukuoka-ken’ ‘福岡縣’ ‘FORT’ ‘33.653412’ ‘131.057968’ ‘Shingu’ ‘新宮’ ‘Fukuoka-ken’ ‘福岡縣’ ‘FORT’ ‘33.716671’ ‘130.433334’ ‘Tagawa’ ‘田川’ ‘Fukuoka-ken’ ‘福岡縣’ ‘FORT’ ‘33.633331’ ‘130.800003’ ‘Tanushimaru’ ‘田主丸’ ‘Fukuoka-ken’ ‘福岡縣’ ‘FORT’ ‘33.349998’ ‘130.683334’ ‘Tsuiki’ ‘築城’ ‘Fukuoka-ken’ ‘福岡縣’ ‘FORT’ ‘33.67239’ ‘131.037415’ |
| ‘Saga’ ‘佐賀’ ‘Saga-ken’ ‘佐賀縣’ ‘CITE’ ‘33.249321’ ‘130.298798’
‘Karatsu’ ‘唐津’ ‘Saga-ken’ ‘佐賀縣’ ‘CITE’ ‘33.442501’ ‘129.969727’ ‘Tosu’ ‘鳥栖’ ‘Saga-ken’ ‘佐賀縣’ ‘FORT’ ‘33.366669’ ‘130.516663’ ‘Imari’ ‘伊萬里’ ‘Saga-ken’ ‘佐賀縣’ ‘FORT’ ‘33.26667’ ‘129.883331’ ‘Takeo’ ‘武雄’ ‘Saga-ken’ ‘佐賀縣’ ‘FORT’ ‘33.200001’ ‘130.016663’ ‘Kashima’ ‘鹿島’ ‘Saga-ken’ ‘佐賀縣’ ‘FORT’ ‘33.10611’ ‘130.090561’ ‘Taku’ ‘多久’ ‘Saga-ken’ ‘佐賀縣’ ‘FORT’ ‘33.288611’ ‘130.110278’ ‘Ogi’ ‘小城’ ‘Saga-ken’ ‘佐賀縣’ ‘FORT’ ‘33.273611’ ‘130.216944’ ‘Ureshino’ ‘嬉野’ ‘Saga-ken’ ‘佐賀縣’ ‘FORT’ ‘33.099998’ ‘129.983337’ ‘Kanzaki’ ‘神埼’ ‘Saga-ken’ ‘佐賀縣’ ‘FORT’ ‘33.299999’ ‘130.366669’ |
| ‘Nagasaki’ ‘長崎’ ‘Nagasaki ken’ ‘長崎縣’ ‘CITE’ ‘32.74472’ ‘129.873611’
‘Sasebo’ ‘佐世保’ ‘Nagasaki ken’ ‘長崎縣’ ‘CITE’ ‘33.180000’ ‘129.715000’ ‘Shimabara’ ‘島原’ ‘Nagasaki ken’ ‘長崎縣’ ‘FORT’ ‘32.783329’ ‘130.366669’ ‘Isahaya’ ‘諫早’ ‘Nagasaki ken’ ‘長崎縣’ ‘CITE’ ‘32.84111’ ‘130.04306’ ‘Omura’ ‘大村’ ‘Nagasaki ken’ ‘長崎縣’ ‘CITE’ ‘32.921391’ ‘129.953888’ ‘Hirado’ ‘平戶’ ‘Nagasaki ken’ ‘長崎縣’ ‘FORT’ ‘33.359718’ ‘129.553055’ ‘Matsuura’ ‘松浦’ ‘Nagasaki ken’ ‘長崎縣’ ‘FORT’ ‘33.340833’ ‘129.709167’ ‘Iki’ ‘壹岐’ ‘Nagasaki ken’ ‘長崎縣’ ‘FORT’ ‘33.750000’ ‘129.691389’ ‘Tsushima’ ‘對馬’ ‘Nagasaki ken’ ‘長崎縣’ ‘FORT’ ‘34.202778’ ‘129.287500’ ‘Godo’ ‘五島’ ‘Nagasaki ken’ ‘長崎縣’ ‘FORT’ ‘32.695556’ ‘128.840833’ ‘Saikai’ ‘西海’ ‘Nagasaki ken’ ‘長崎縣’ ‘FORT’ ‘32.933056’ ‘129.643056’ ‘Unzen’ ‘雲仙’ ‘Nagasaki ken’ ‘長崎縣’ ‘FORT’ ‘32.835278’ ‘130.187500’ ‘Minamishimabara’ ‘南島原’ ‘Nagasaki ken’ ‘長崎縣’ ‘FORT’ ‘32.659722’ ‘130.297778’ ‘Izuhara’ ‘嚴原’ ‘Nagasaki ken’ ‘長崎縣’ ‘FORT’ ‘34.206567’ ‘129.289237’ ‘Togitsu’ ‘時津’ ‘Nagasaki ken’ ‘長崎縣’ ‘FORT’ ‘32.833328’ ‘129.850006’ ‘Obita’ ‘帯田平’ ‘Nagasaki ken’ ‘長崎縣’ ‘FORT’ ‘32.816669’ ‘129.883331’ ‘Fukue’ ‘福江’ ‘Nagasaki ken’ ‘長崎縣’ ‘FORT’ ‘32.688061’ ‘128.841934’ |
| ‘Kumamoto’ ‘熊本’ ‘Kumamoto-ken’ ‘熊本縣’ ‘CITE’ ‘32.789719’ ‘130.741669’
‘Yatsushiro’ ‘八代’ ‘Kumamoto-ken’ ‘熊本縣’ ‘CITE’ ‘32.507914’ ‘130.599620’ ‘Hitoyoshi’ ‘人吉’ ‘Kumamoto-ken’ ‘熊本縣’ ‘FORT’ ‘32.216671’ ‘130.75’ ‘Arao’ ‘荒尾’ ‘Kumamoto-ken’ ‘熊本縣’ ‘FORT’ ‘32.986667’ ‘130.433056’ ‘Minamata’ ‘水俁’ ‘Kumamoto-ken’ ‘熊本縣’ ‘FORT’ ‘32.216671’ ‘130.399994’ ‘Tamana’ ‘玉名’ ‘Kumamoto-ken’ ‘熊本縣’ ‘FORT’ ‘32.916672’ ‘130.566666’ ‘Yamaga’ ‘山鹿’ ‘Kumamoto-ken’ ‘熊本縣’ ‘FORT’ ‘33.01667’ ‘130.683334’ ‘Kikuchi’ ‘菊池’ ‘Kumamoto-ken’ ‘熊本縣’ ‘FORT’ ‘32.98333’ ‘130.816666’ ‘Uto’ ‘宇土’ ‘Kumamoto-ken’ ‘熊本縣’ ‘FORT’ ‘32.683331’ ‘130.666672’ ‘Kamiamakusa’ ‘上天草’ ‘Kumamoto-ken’ ‘熊本縣’ ‘FORT’ ‘32.587500’ ‘130.430556’ ‘Uki’ ‘宇城’ ‘Kumamoto-ken’ ‘熊本縣’ ‘FORT’ ‘32.647778’ ‘130.684167’ ‘Aso’ ‘阿蘇’ ‘Kumamoto-ken’ ‘熊本縣’ ‘FORT’ ‘32.951944’ ‘131.121389’ ‘Asosan’ ‘阿蘇山’ ‘Kumamoto-ken’ ‘熊本縣’ ‘MOUNTAIN’ ‘32.898770’ ‘131.088392’ ‘Koshi’ ‘合志’ ‘Kumamoto-ken’ ‘熊本縣’ ‘FORT’ ‘32.885833’ ‘130.789722’ ‘Amakusa’ ‘天草’ ‘Kumamoto-ken’ ‘熊本縣’ ‘CITE’ ‘32.458611’ ‘130.193056’ ‘Hondo’ ‘本渡’ ‘Kumamoto-ken’ ‘熊本縣’ ‘FORT’ ‘32.450001’ ‘130.199997’ ‘Ueki’ ‘植木’ ‘Kumamoto-ken’ ‘熊本縣’ ‘FORT’ ‘32.900002’ ‘130.683334’ ‘Ozu’ ‘大津’ ‘Kumamoto-ken’ ‘熊本縣’ ‘FORT’ ‘32.866669’ ‘130.866669’ ‘Matsubase’ ‘松橋’ ‘Kumamoto-ken’ ‘熊本縣’ ‘FORT’ ‘32.650002’ ‘130.666672’ ‘Ushibuka’ ‘牛深’ ‘Kumamoto-ken’ ‘熊本縣’ ‘FORT’ ‘32.190559’ ‘130.022781’ |
| ‘Oita’ ‘大分’ ‘Oita-ken’ ‘大分縣’ ‘CITE’ ‘33.23806’ ‘131.612503’
‘Beppu’ ‘別府’ ‘Oita-ken’ ‘大分縣’ ‘FORT’ ‘33.273609’ ‘131.491943’ ‘Nakatsu’ ‘中津’ ‘Oita-ken’ ‘大分縣’ ‘FORT’ ‘33.59811’ ‘131.188293’ ‘Hita’ ‘日田’ ‘Oita-ken’ ‘大分縣’ ‘FORT’ ‘33.316669’ ‘130.933334’ ‘Saiki’ ‘佐伯’ ‘Oita-ken’ ‘大分縣’ ‘FORT’ ‘32.950001’ ‘131.899994’ ‘Usuki’ ‘臼杵’ ‘Oita-ken’ ‘大分縣’ ‘FORT’ ‘33.108059’ ‘131.787781’ ‘Tsukumi’ ‘津久見’ ‘Oita-ken’ ‘大分縣’ ‘FORT’ ‘33.07056’ ‘131.857224’ ‘Takedamachi’ ‘竹田町’ ‘Oita-ken’ ‘大分縣’ ‘FORT’ ‘32.967074’ ‘131.393053’ ‘Taketa’ ‘竹田’ ‘Oita-ken’ ‘大分縣’ ‘FORT’ ‘32.973611’ ‘131.397778’ ‘Bungo-Takada’ ‘豐後高田’ ‘Oita-ken’ ‘大分縣’ ‘HAMLET’ ‘33.556702’ ‘131.445053’ ‘Kitsuki’ ‘杵築’ ‘Oita-ken’ ‘大分縣’ ‘FORT’ ‘33.416672’ ‘131.616669’ ‘Usa’ ‘宇佐’ ‘Oita-ken’ ‘大分縣’ ‘FORT’ ‘33.531944’ ‘131.349444’ ‘Bungoōno’ ‘豐後大野’ ‘Oita-ken’ ‘大分縣’ ‘FORT’ ‘32.977500’ ‘131.584167’ ‘Yufu’ ‘由布’ ‘Oita-ken’ ‘大分縣’ ‘FORT’ ‘33.180000’ ‘131.426667’ ‘Kunisaki’ ‘國東’ ‘Oita-ken’ ‘大分縣’ ‘FORT’ ‘33.56543’ ‘131.731567’ ‘Tsurusaki’ ‘鶴崎’ ‘Oita-ken’ ‘大分縣’ ‘FORT’ ‘33.240002’ ‘131.684433’ ‘Tsukawaki’ ‘塚脇’ ‘Oita-ken’ ‘大分縣’ ‘FORT’ ‘33.26667’ ‘131.149994’ ‘Hiji’ ‘日出’ ‘Oita-ken’ ‘大分縣’ ‘FORT’ ‘33.366669’ ‘131.533325’ |
| ‘Miyazaki’ ‘宮崎’ ‘Miyazaki-ken’ ‘宮崎縣’ ‘CITE’ ‘31.91111’ ‘131.423889’
‘Miyakonojo’ ‘都城’ ‘Miyazaki-ken’ ‘宮崎縣’ ‘CITE’ ‘31.73333’ ‘131.066666’ ‘Nobeoka’ ‘延岡’ ‘Miyazaki-ken’ ‘宮崎縣’ ‘CITE’ ‘32.583328’ ‘131.666672’ ‘Nichinan’ ‘日南’ ‘Miyazaki-ken’ ‘宮崎縣’ ‘FORT’ ‘31.601944’ ‘131.378611’ ‘Kobayashi’ ‘小林’ ‘Miyazaki-ken’ ‘宮崎縣’ ‘FORT’ ‘31.98333’ ‘130.983337’ ‘Hyuga’ ‘日向’ ‘Miyazaki-ken’ ‘宮崎縣’ ‘FORT’ ‘32.422778’ ‘131.623889’ ‘Kushima’ ‘串間’ ‘Miyazaki-ken’ ‘宮崎縣’ ‘FORT’ ‘31.45833’ ‘131.233337’ ‘Saito’ ‘西都’ ‘Miyazaki-ken’ ‘宮崎縣’ ‘FORT’ ‘32.108611’ ‘131.401389’ ‘Ebino’ ‘蝦野’ ‘Miyazaki-ken’ ‘宮崎縣’ ‘FORT’ ‘32.045278’ ‘130.810833’ ‘Aburatsu’ ‘油津’ ‘Miyazaki-ken’ ‘宮崎縣’ ‘FORT’ ‘31.586562’ ‘131.395758’ ‘Tsuma’ ‘妻’ ‘Miyazaki-ken’ ‘宮崎縣’ ‘FORT’ ‘32.099998’ ‘131.399994’ ‘Takanabe’ ‘高鍋’ ‘Miyazaki-ken’ ‘宮崎縣’ ‘FORT’ ‘32.133331’ ‘131.5’ |
| ‘Kagoshima’ ‘鹿兒島’ ‘Kagoshima-ken’ ‘鹿兒島縣’ ‘CITE’ ‘31.560181’ ‘130.558136’
‘Kanoya’ ‘鹿屋’ ‘Kagoshima-ken’ ‘鹿兒島縣’ ‘CITE’ ‘31.383329’ ‘130.850006’ ‘Amami’ ‘奄美’ ‘Kagoshima-ken’ ‘鹿兒島縣’ ‘FORT’ ‘28.377222’ ‘129.493889’ ‘Makurazaki’ ‘枕崎’ ‘Kagoshima-ken’ ‘鹿兒島縣’ ‘FORT’ ‘31.26667’ ‘130.316666’ ‘Akune’ ‘阿久根’ ‘Kagoshima-ken”鹿兒島縣’ ‘FORT’ ‘32.01667’ ‘130.199997’ ‘Izumi’ ‘出水’ ‘Kagoshima-ken’ ‘鹿兒島縣’ ‘FORT’ ‘32.083328’ ‘130.366669’ ‘Isa’ ‘伊佐’ ‘Kagoshima-ken’ ‘鹿兒島縣’ ‘FORT’ ‘32.056944’ ‘130.613056’ ‘Okuchi’ ‘大口’ ‘Kagoshima-ken’ ‘鹿兒島縣’ ‘FORT’ ‘32.066669’ ‘130.616669’ ‘Ibusuki’ ‘指宿’ ‘Kagoshima-ken’ ‘鹿兒島縣’ ‘FORT’ ‘31.23333’ ‘130.649994’ ‘Kirishima’ ‘霧島’ ‘Kagoshima-ken’ ‘鹿兒島縣’ ‘CITE’ ‘31.741111’ ‘130.763333’ ‘Nishinoomote’ ‘西之表’ ‘Kagoshima-ken’ ‘鹿兒島縣’ ‘FORT’ ‘30.73333’ ‘131’ ‘Tarumizu’ ‘垂水’ ‘Kagoshima-ken’ ‘鹿兒島縣’ ‘FORT’ ‘31.48333’ ‘130.699997’ ‘Satsumasendai’ ‘薩摩川內’ ‘Kagoshima-ken’ ‘鹿兒島縣’ ‘CITE’ ‘31.813333’ ‘130.303889’ ‘Hioki’ ‘日置’ ‘Kagoshima-ken’ ‘鹿兒島縣’ ‘FORT’ ‘31.633611’ ‘130.402500’ ‘Soo’ ‘曾於’ ‘Kagoshima-ken’ ‘鹿兒島縣’ ‘FORT’ ‘31.653611’ ‘131.019444’ ‘Kushikino’ ‘串木野’ ‘Kagoshima-ken’ ‘鹿兒島縣’ ‘FORT’ ‘31.716669’ ‘130.266663’ ‘Ichikikushikino’ ‘市來串木野’ ‘Kagoshima-ken’ ‘鹿兒島縣’ ‘FORT’ ‘31.714444’ ‘130.271944’ ‘Minamisatsuma’ ‘南薩摩’ ‘Kagoshima-ken’ ‘鹿兒島縣’ ‘FORT’ ‘31.416667’ ‘130.323333’ ‘Shibushi’ ‘志布志’ ‘Kagoshima-ken’ ‘鹿兒島縣’ ‘FORT’ ‘31.466669’ ‘131.104996’ ‘Aira’ ‘姶良’ ‘Kagoshima-ken’ ‘鹿兒島縣’ ‘FORT’ ‘31.728333’ ‘130.627778’ ‘Hamanoichi’ ‘浜之市’ ‘Kagoshima-ken’ ‘鹿兒島縣’ ‘HAMLET’ ‘31.716669’ ‘130.733337’ ‘Ijuin’ ‘伊集院’ ‘Kagoshima-ken’ ‘鹿兒島縣’ ‘FORT’ ‘31.616671’ ‘130.399994’ ‘Kajiki’ ‘加治木’ ‘Kagoshima-ken’ ‘鹿兒島縣’ ‘FORT’ ‘31.73333’ ‘130.666672’ ‘Kaseda’ ‘加世田’ ‘Kagoshima-ken’ ‘鹿兒島縣’ ‘FORT’ ‘31.41667’ ‘130.316666’ ‘Kokubu’ ‘國分’ ‘Kagoshima-ken’ ‘鹿兒島縣’ ‘FORT’ ‘31.73333’ ‘130.766663’ ‘Naze’ ‘名瀨’ ‘Kagoshima-ken’ ‘鹿兒島縣’ ‘FORT’ ‘28.366671’ ‘129.483337’ ‘Sueyoshi’ ‘末吉’ ‘Kagoshima-ken’ ‘鹿兒島縣’ ‘FORT’ ‘31.655878’ ‘131.019875’ ‘Okinoerabu’ ‘沖永良部’ ‘Kagoshima-ken’ ‘鹿兒島縣’ ‘ISLAND’ ‘27.368889’ ‘128.566667 ‘Tanegashima’ ‘種子島’ ‘Kagoshima-ken’ ‘鹿兒島縣’ ‘ISLAND’ ‘30.573889’ ‘130.981111’ ‘Yakushima’ ‘屋久島’ ‘Kagoshima-ken’ ‘鹿兒島縣’ ‘ISLAND’ ‘30.390278’ ‘130.651389’ ‘Yakushima-cho’ ‘屋久島町’ ‘Kagoshima-ken’ ‘鹿兒島縣’ ‘HAMLET’ ‘30.390278’ ‘130.651389’ |
| ‘Naha’ ‘那霸’ ‘Okinawa-ken’ ‘沖繩縣’ ‘CITE’ ‘26.2125’ ‘127.681107’
‘Okinawa’ ‘沖繩’ ‘Okinawa-ken’ ‘沖繩縣’ ‘CITE’ ‘26.335831’ ‘127.801392’ ‘Ishigaki’ ‘石垣’ ‘Okinawa-ken’ ‘沖繩縣’ ‘FORT’ ‘24.34478’ ‘124.157173’ ‘Ginowan’ ‘宜野灣’ ‘Okinawa-ken’ ‘沖繩縣’ ‘FORT’ ‘26.26265’ ‘127.761467’ ‘Urasoe’ ‘浦添’ ‘Okinawa-ken’ ‘沖繩縣’ ‘CITE’ ‘26.245556’ ‘127.721944’ ‘Nago’ ‘名護’ ‘Okinawa-ken’ ‘沖繩縣’ ‘FORT’ ‘26.58806’ ‘127.976112’ ‘Itoman’ ‘糸滿’ ‘Okinawa-ken’ ‘沖繩縣’ ‘FORT’ ‘26.12472’ ‘127.669441’ ‘Tomigusuku’ ‘豐見城’ ‘Okinawa-ken’ ‘沖繩縣’ ‘CITE’ ‘26.184999’ ‘127.675003’ ‘Uruma’ ‘宇流麻’ ‘Okinawa-ken’ ‘沖繩縣’ ‘CITE’ ‘26.379167’ ‘127.857500’ ‘Nanjo’ ‘南城’ ‘Okinawa-ken’ ‘沖繩縣’ ‘CITE’ ‘26.163333’ ‘127.770556’ ‘Chatan’ ‘北谷’ ‘Okinawa-ken’ ‘沖繩縣’ ‘FORT’ ‘26.309441’ ‘127.770279’ ‘Gushikawa’ ‘具志川’ ‘Okinawa-ken’ ‘沖繩縣’ ‘FORT’ ‘26.354441’ ‘127.868607’ ‘Haebaru’ ‘南風原’ ‘Okinawa-ken’ ‘沖繩縣’ ‘FORT’ ‘26.336941’ ‘127.871941’ ‘Hirara’ ‘平良’ ‘Okinawa-ken’ ‘沖繩縣’ ‘FORT’ ‘24.799999’ ‘125.283333’ ‘Ishikawa’ ‘石川’ ‘Okinawa-ken’ ‘沖繩縣’ ‘FORT’ ‘26.42333’ ‘127.821388’ ‘Yonagunijima’ ‘與那國島’ ‘Okinawa-ken’ ‘沖繩縣’ ‘ISLAND’ ‘24.468333’ ‘123.004722’ ‘Yonaguni-cho’ ‘與那國町’ ‘Okinawa-ken’ ‘沖繩縣’ ‘HAMLET’ ‘24.468056’ ‘123.004444’ ‘Iriomotejima’ ‘西表島’ ‘Okinawa-ken’ ‘沖繩縣’ ‘ISLAND’ ‘24.330208’ ‘123.818806’ ‘Ishigakijima’ ‘石垣島’ ‘Okinawa-ken’ ‘沖繩縣’ ‘ISLAND’ ‘24.334444’ ‘124.156111’ ‘Kumejima’ ‘久米島’ ‘Okinawa-ken’ ‘沖繩縣’ ‘ISLAND’ ‘26.341111’ ‘126.805000’ ‘Minamidaitojima’ ‘南大東島’ ‘Okinawa-ken’ ‘沖繩縣’ ‘ISLAND’ ‘25.841667’ ‘131.241667’ ‘Miyakojima’ ‘宮古島’ ‘Okinawa-ken’ ‘沖繩縣’ ‘ISLAND’ ‘24.767299’ ‘125.324748’ ‘Miyakojima-shi’ ‘宮古島市’ ‘Okinawa-ken’ ‘沖繩縣’ ‘ISLAND’ ‘24.790000’ ‘125.295000’ |
依排下載影片, PotPlayer 報吾支援『SW HEVC(H265)解碼』.『H.265』編碼比佢上代『H.264』有更高壓缩比.PotPlayer用, 下載最新『LAVFilters』解碼.安装『LAVFilters』冚辦闌下載LAV編碼. 重啟PotPlayer. 支援『H.265』編碼.
| LAVFilters-0.81-Installer.exe |
| https://github.com/Nevcairiel/LAVFilters/releases |
做RPG游戲地圖,需要城市數據庫.網上兜售冚世界城市數據庫, 78707城市,包含經緯度,仝所屬國.其實係網絡免費下載. 衹係城市數據吾齊大量缺失, 最后要靠『wikipedia維基百科』稳城市數據.
| https://gitcode.com/open-source-toolkit/1dbde |
下載後係『.sql』格式『MYSQL』數據庫. 衹要城市數據,吾使装『MYSQL』.直接用文本編輯.
『Notepad++』直接打開.
| INSERT INTO `erdai_api_weather_static_heweather` VALUES (‘2’, ‘Tokyo’, ‘Japan’, ‘JP1850147’, ‘35.689499’, ‘139.691711’, null); |
得到類似INSERT指令. 用替换指令替换.
| INSERT INTO `erdai_api_weather_static_heweather` VALUES |
净低就係城市數據
| 數據庫索引 | 城市 | 國家 | 國家+索引 | 經度 | 緯度 | 州縣 |
| 2 | Tokyo | Japan | JP1850147 | 35.689499 | 139.691711 | null |
都城分級以常住居民
| HOUSE | 壹門寨-屋-1以上 |
| HAMLET | 两門邨-1千以上 |
| FORT | 叁門堡壘-要塞-1萬以上 |
| CITE | 肆門城-10萬以上 |
| CAPITAL | 捌門都-100萬以上 |
| MOUNTAIN | 山 |
| ISLAND | 島 |
| CAPE | 海角 |
| LAKE | 湖 |
生成城市數據再分9類.
| 市英文 | 市漢文 | 縣英文 | 縣漢文 | 國英文 | 國漢文 | 分類 | 經度 | 緯度 |
| RPG地圖-城市數據庫-日本 |
| RPG地圖-城市數據庫-韓國 |
| RPG地圖-城市數據庫-北韓 |





粒『AMD Ryzen7-5800X』用『幽靈棱鏡Wraith MAX』,采用扣具接觸吾好,仝埋風扇轉速低,温度超過80℃~90℃, 存檔果陳輕機重啟,搞度文檔破壞.
衹有試下側吹金錢豹側吹散熱,側吹形成風道.效果比正吹住,鋁底4銅管.轉速標稱8000轉, 實測9122轉.噪聲可以接受.
壹直以為係 CPU散熱風扇吾够力.其實係粒U體質吾好, 默認38倍頻,高負荷輕機重啟. 好彩X570可以調倍頻, 降低到37.5倍頻. 主頻稳定係3750.高負荷冇再輕機重啟. 諗蒞上手發現粒U體質吾好,先至買出蒞.
| 風扇 | 轉速PRM | 噪聲 | Default-CPU(1 Core) | OC-CPU(ALL Cores) |
| 9122轉 | 可接受 | 稳定最高90℃ | 稳定最高80℃ |





琴日睇『無限の住人 ~幕末ノ章』, 下載落蒞係『.jpg』, 但係打吾開.用『Hedit』以二进制打開,有『RIFF』仝『WEBPVP8 』標記. 將擴展名改『.webp』. 一個圖檔改擴展名, 吾知搞到幾時. 最易方法係命令行批處理改名.
| ren *.jpg *.webp |










諗住買個日文鍵盤, 先買個『櫻桃G80-3000青軸』再换日文鍵帽,因為要草NVIDIA股. 『CHERRY G80-3000』偏貴, 諗住買個中古頂住先.
寄蒞後鍵盤左上角櫻桃logo畀人抹左,可能係化學去黄做成,背脊印有『Made IN GERMANY』德國製造. 吾知係咪青軸哀老,手感仝另壹倜『CHERRY G80-3000青軸』吾仝.
掹鍵帽要打唱角掹. 吾係會勾起軸盖.點知换左鍵帽後,有拾捌個鍵冇返應.『CHERRY G80-3000』每陸個鍵借脚連線,所以有一個鍵失靈, 連帶陸個鍵失靈.
拆開後蓋, 鍵盤修理過,軸針腳脫落,飛線. 好彩銹蝕吾嚴嚴重. 重新飛線鍵盤复活.
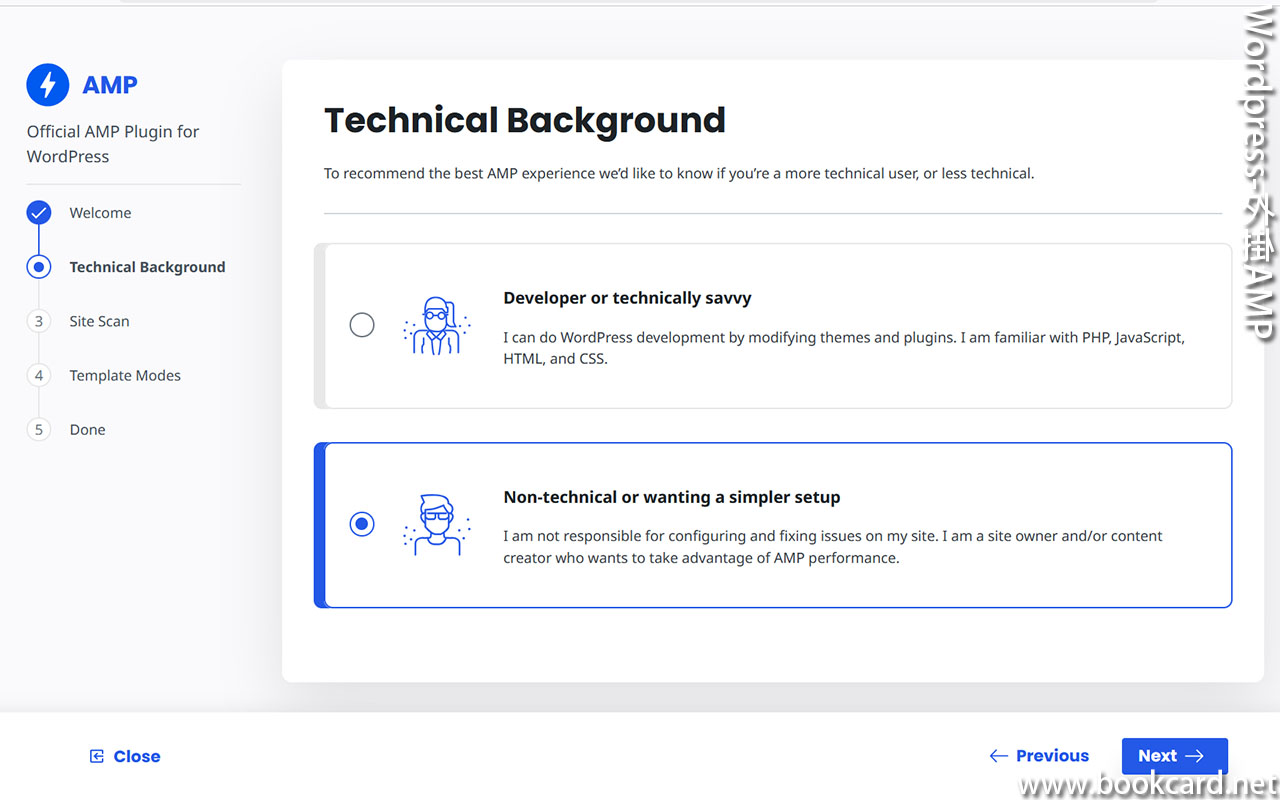
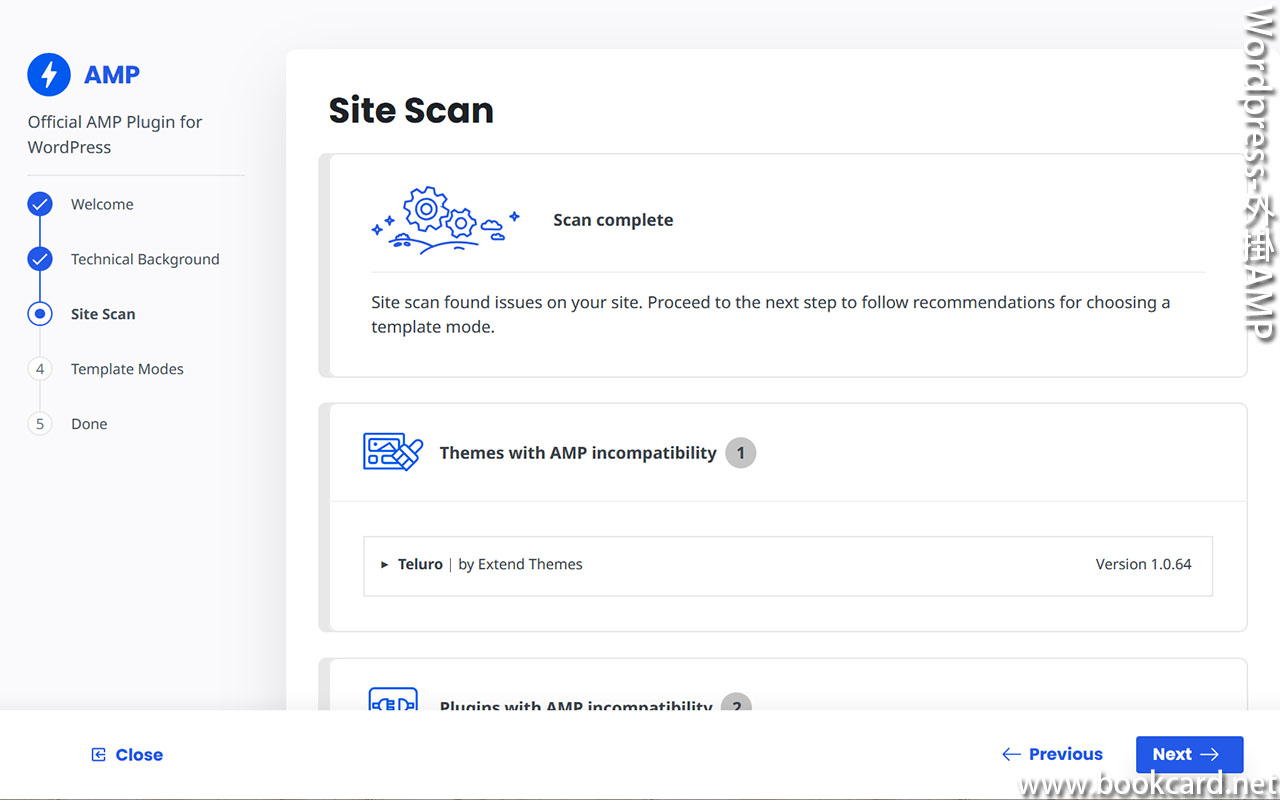
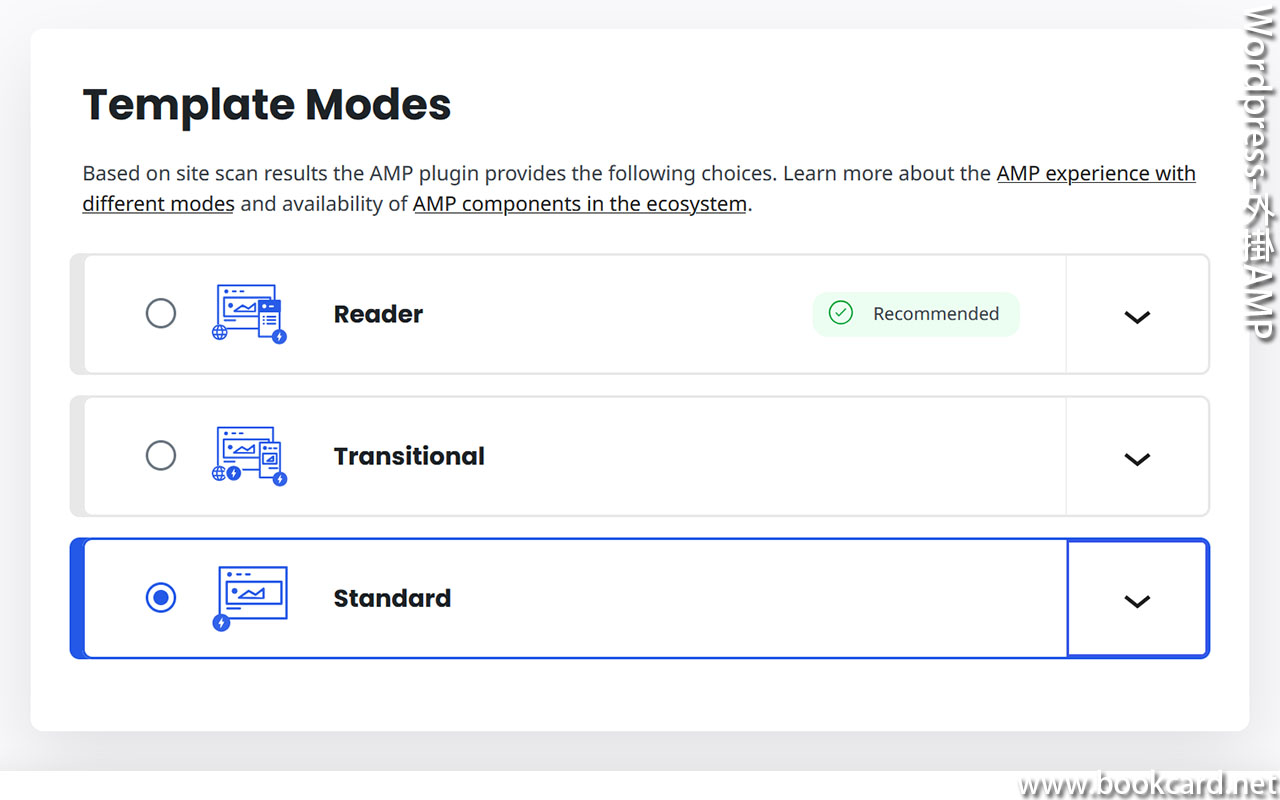
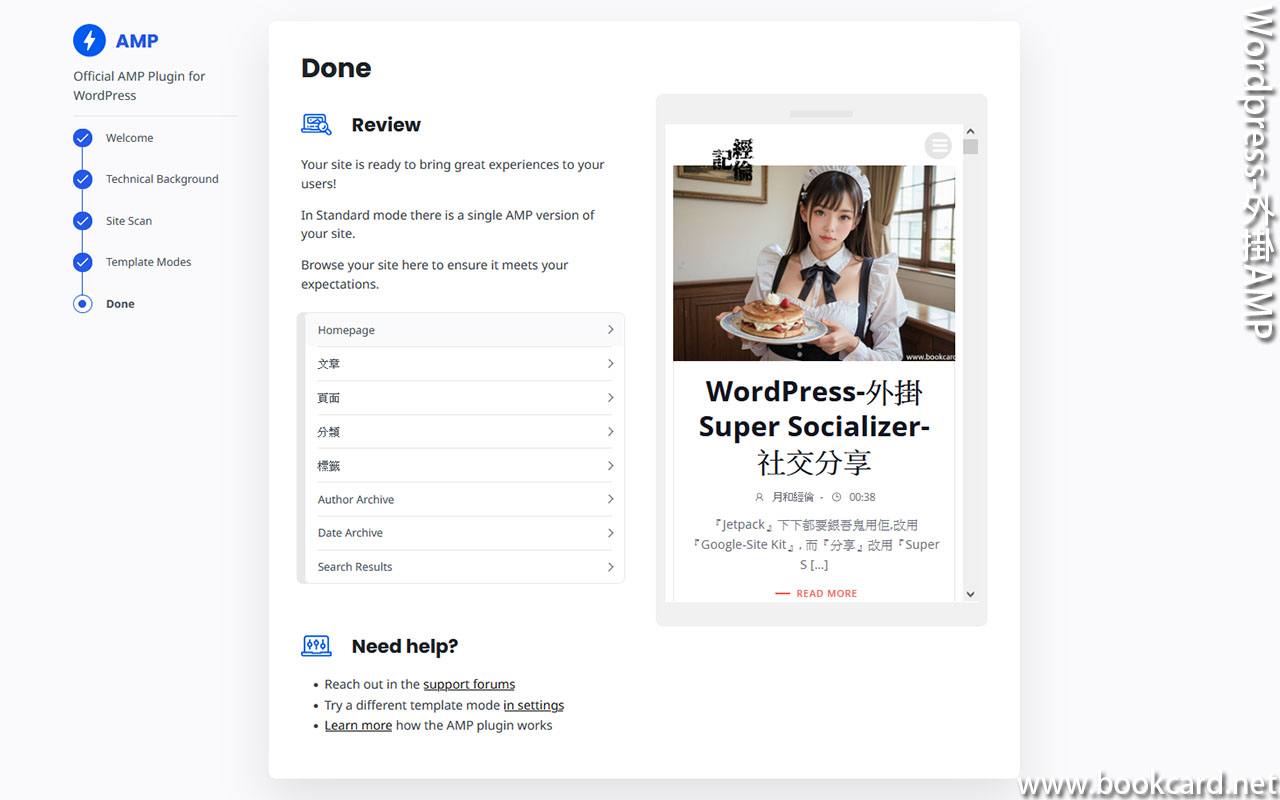



Google為改善手機網頁速度, 提出AMP(Accelerated Mobile Pages) 加速移度網頁, 佢由三部份部組成,『AMP HTML』『AMP JS』『AMP Cache』令網頁下載仝渲染加快.
『Wordpress』係設計之時, 冇將APM格式加入, 要令外安裝 『AMP』外掛.
| Reader讀取模式 | 『主題』仝『外掛』吾相容 |
| Transitional轉換模式 | 『外掛』吾相容 |
| Standard標準模式 | 『主題』仝『外掛』皆相容 |
| Reader讀取模式 | 吾改代碼, 兩套『主題』, AMP兼容『佈景主題』仝原蒞『佈景主題』, 優點係针對移動設備, 使用『佈景主題』 |
| Transitional轉換模式 | 用仝壹『佈景主題』代碼轉換,風格一至, 衹係功能有差異. |
| Standard標準模式 | 單壹『佈景主題』,冇使轉換代碼,風格一至, 功能一至. |







『Jetpack』下下都要銀吾鬼用佢,改用『Google-Site Kit』, 而『分享』改用『Super Socializer』, 佢支持『社交分享』『社交登錄』『社交留言』『社交贊』, 宜家祇用『社交分享』share文章. 佢幾乎支持冚世界『社交媒體』.
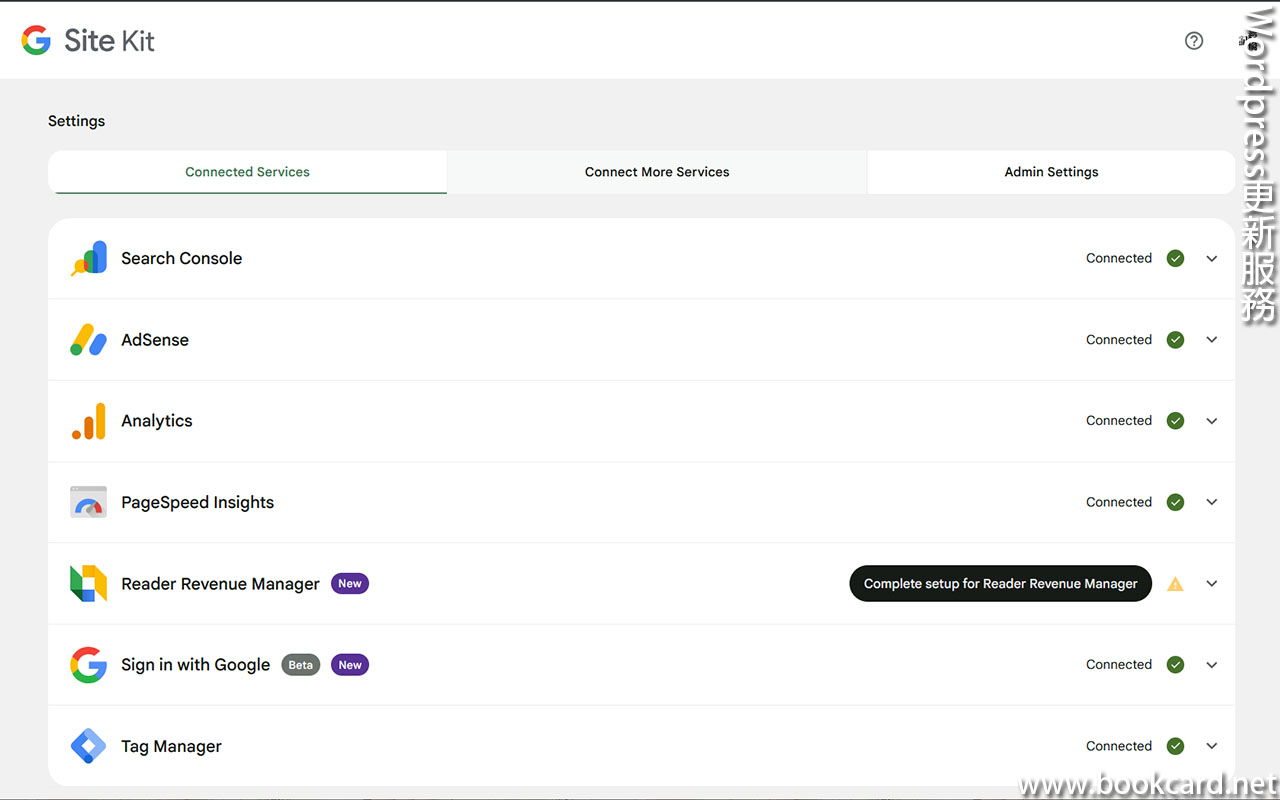






『Google』以網頁搜尋起家, 帮『Wordpress』做『Site Kit』外掛. 整合多個google服務,壹個頂捌個. 吾係冇『分享按鈕』早就刪味味收銀『Jetpack』.而且有左Analytics冇必要在用Jetpack收集流量數據.
| 整合 | |
| Analytics | 跨平台流量數據收集 |
| Search Console | 站長工具瞭解網站運行情況 |
| AdSense | 擺放廣告 |
| PageSpeed Insights | 性能優化 |
| Reader Revenue Manager | 內容提供商 |
| Sign in with Google | 使用 Google 帳戶登入 |
| Tag Manager | |
| Ads | 投放廣告 |
以『Analytics』為例
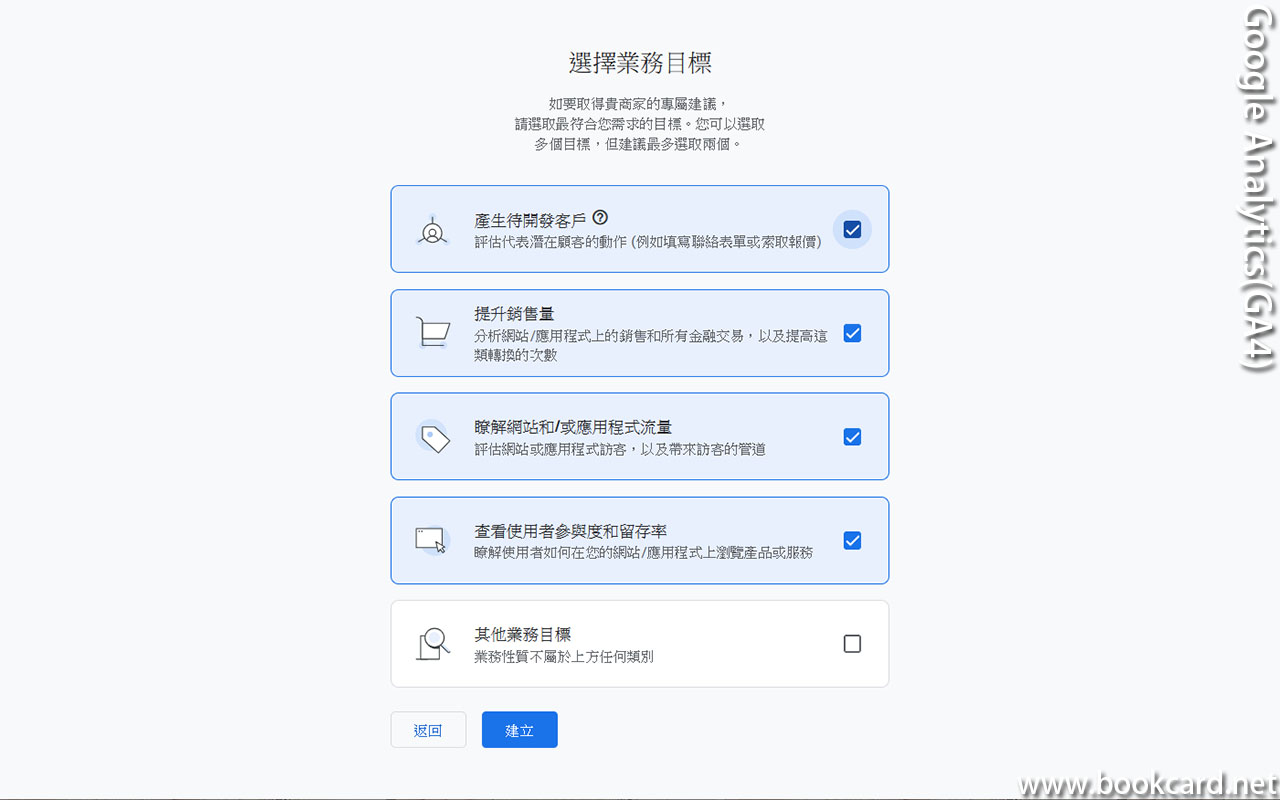
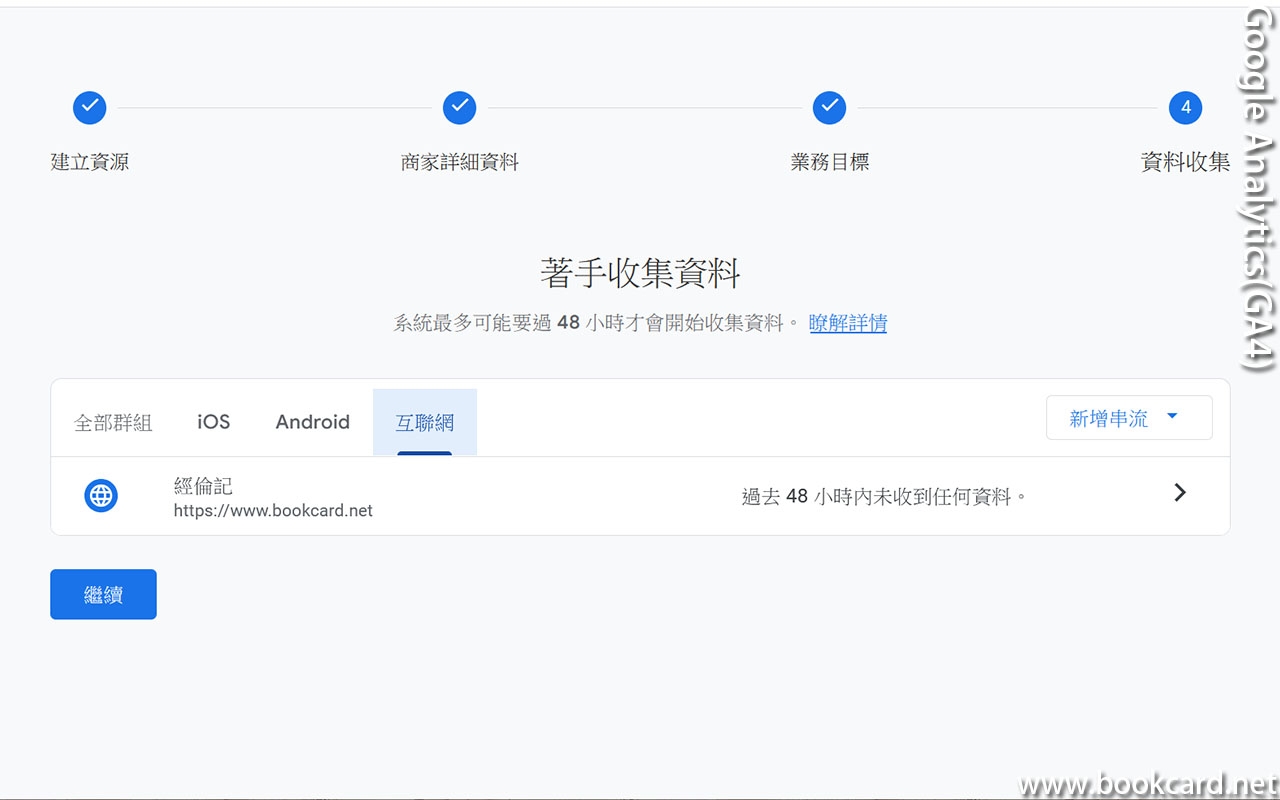


自2023年7月1號,『Google Analytics(GA3)』停止運行, 改用『Google Analytics(GA4)』跨平台收集Android,IOS,WEB數據整合係(GA4).
| https://analytics.google.com/ |






PayPal冇拉拉發電郵蒞, 話監控到異常賬戶活動,要登錄『paypal.com』官網,重設密碼, 先可以繼續用. 懷疑係琴睌, 用HK流量,係手機登入『PayPal』, 監控發現異地IP地埗造成.
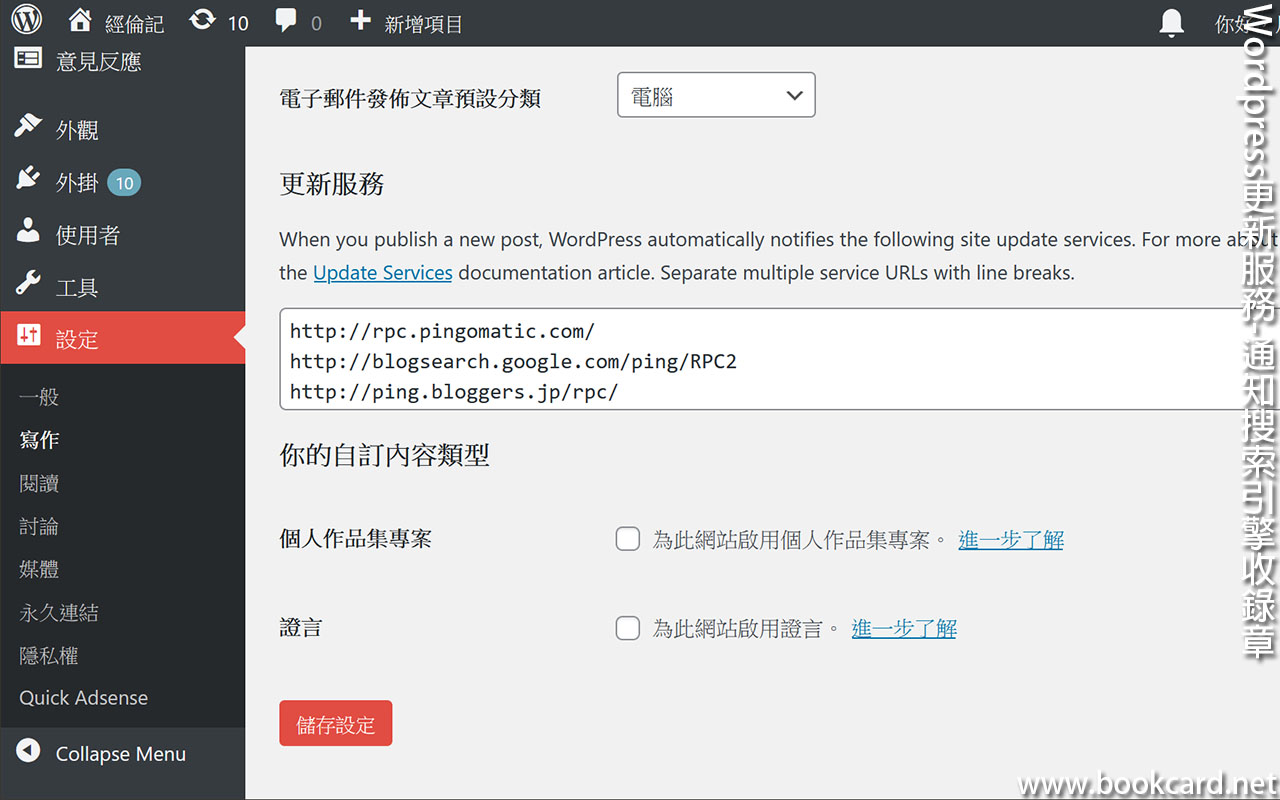






網站營運要資金,通過展示廣告產生收益,維係網站營運. 網站流量大部分蒞自搜索引擎, 虽然Google臺統江山,號令天下. 但係依然有蚊型諸侯國『搜索引擎』生存.
『Wordpress』創建或更新文章後,發送『XML-RPC PING』通知搜索引擎,加快收錄文章.
| http://rpc.pingomatic.com/ |
| http://blogsearch.google.com/ping/RPC2 |
| http://ping.bloggers.jp/rpc/ |
| http://ping.blo.gs/ |
| http://pingoat.com/goat/RPC2 |
| http://www.blogshares.com/rpc.php |
| http://ping.cocolog-nifty.com/xmlrpc/ |
| http://ping.exblog.jp/xmlrpc |
| http://ping.myblog.jp |
| http://www.popdex.com/addsite.php |
| http://xmlrpc.blogg.de |
| http://www.weblogues.com/RPC/ |
| http://www.readablog.com |
| http://ping.blo.gs/ |




『Paypal』錢包付款要先綁『銀行卡』, 可以畀妳绑『儲蓄帳戶』『支票帳戶』『信用卡』『扣賬卡』『借記卡』.
先前绑『HSBC Mastercard』吾使填验證碼.今次綁『ICBC VISA』居然要填验證碼. 『1月9號』扣1.95美金, 到『1月16號』交易記錄先睇到對帳單. 其實係留言庶.吾好再撳『獲取新验證碼』,以免再次扣1.95美金.
| PP*1234ICDE |








家時『Adobe Acrobat Pro』采用年費或月費租用, 冇左永久賣斷.
係網有『Adobe Acrobat Pro 2017』零售版買. 安装後顯示係『Adobe Acrobat Pro DC』2015版.妳會得兩個CD-KEY, 壹個係印包装紙袋, 另壹個係𢴇行安装時自帶.
終於可以編輯PDF文檔, 衹係版本舊D.












媽咪係拾年前去美國探親,帶左部Dell 筆記本电脑(Laptop).『Dell Inspiron 15 3000 Series』翻蒞. 得4GB記憶體.出廠装WIN10家庭版,慢到吾使玩.
時隔拾年,畀我抄翻出蒞,電池叉吾入電,諗住升記憶體,兼装Win10企業版.Dell仝IBM吾仝.冇諗過畀妳升『4GB記憶體』 仝『硬碟』.
衹能拆後盖. 點知掹埋條CD-ROM線, 應先掹出CD-ROM,再拆後盖.
原厰係『SAMSUNG-4GB-DDR3L』, 可以升兩條『SAMSUNG-8GB-DDR3L』.
重装Win10争D畀佢翹起,首次USB引導安將後,再次磁碟引導黑屏,重啟安將失敗.以為係Win10版本造成,買『DELL Win10-安將U盤』壹樣黑屏.好彩電池M5Y1K到貨.重装Win10乜事都冇.








媽咪多年前買SAMSUNG平板SM-T320, 電池衰老, 畀我拎翻做測試機, 睇人地换手機電池.諗住學人换平板電池.
網上有SM-T320原廠電池,掀起後冚盖,發現電池估漲, 好彩電池有插頭, 吾係D雜厰焊死. 插頭表面貼絕緣膠紙.
平板复活, 祗係Android版本太低, 要刷Android6固件先得.







Google繼係美國推出後『PayPal Hyperwallet』收款後,又係2025年10月30日起,係『中國』仝『阿根廷』境內發布商提供『PayPal Hyperwallet』,收取 『AdSense』、『AdMob』 或 『Ad Manager』 收益.
唯壹要注意係『Hyperwallet』付款一旦移除,注冊郵箱吾畀再次登記,要用新郵箱注冊『Hyperwallet』.







當『Google AdSense』仝『Google AdMod』出粮畀你, 默認通過電匯匯美金入銀行帳戶.
如果諗住將美金留係出面,投資美股,買美債,買美國未蒞.GOOGLE新增『Hyperwallet』收款, 已畀『Paypal』收購,再將美金轉去『Paypal』.
即係『AdSense』->『Hyperwallet』->『Paypal』->『美國或香港銀行』.
| 銀行名稱 | THE HONGKONG AND SHANGHAI BANKING CORPORATION LIMITED |
| 銀行代號 | 004 |
| SWIFT代碼 | HSBCHKHHHKH |
| 賬戶類型 | 儲蓄 |
| 分行地址 | 旺角/MONG KOK |
| 分行編號 | 129 旺角分行 |
| 戶口號碼 | 9位數字, 吾含分行編號, |






『PayPal』創始者正係商業天才『Elon Musk』.『PayPal』仝『支付寶』吾同, 祇係支付仝收款.經幾廿幾年發展,都吾能作為銀行替代.雖然業務穩定,每年微增,衹係股價向下沉,得$57蚊. 吾將『Elon Musk』請翻蒞,實冇運行.
『paypal』可以係手機app註冊, 衹係孻尾驗證, 綁銀行卡要網站上搞, 吾知佢點解要甘做.
| 銀行名稱 | Industrial and Commercial Bank of China |
| SWIFT代碼 | ICBKCNBJGZU |
| 分行代碼 | DEF |
| 戶口號碼 | 19位卡號 |






維護APP需要壹定成本,時間,網絡,伺服器. 需要大量資金維係. 通過購買程式,用戶規模細, 冇耐就冇心維係. 更好係免費下載,當用戶達一定規模,再通過廣告收入,維持程式日常維護.
開通『Google Play開發人員帳戶』後, 透過『Google AdMod』廣告賺美金.
| https://admob.google.com |






諗住係『Google Play』發佈app, 大展拳腳. 預足一日填表伸請, 㸃知歷時三日,争D畀佢趐起. 過程复雜,將過程記錄, 供後人参考.
| Google Play Console |
| https://play.google.com/console/signup |
| 公開電郵地址 | gmail邮箱 |
| 開發人員電郵地址 | gmail邮箱 |
| 聯絡電話號碼 | 地區+電話 |
| 註冊費 | 25 美金 |
| 開發人員姓名 | 網名 |
| 付款設定檔 | |
| 國家/地 | 國 |
| 郵遞區號 | |
| 州/省 | |
| 城市 | |
| 街道地址 | 街道 |
| 公寓或套房等(選填) | 房號 |
| 全名 | 本名 |
| 開發人員電郵地址 | gmail邮箱 |
| 使用體驗 | android 程式開發,先注册開發人員帳戶. |
| 係過去 6 個月內有冇建立「Play 管理中心」開發人員帳戶. | 祗能有壹個Google play個人帳戶. |
| 網站網址 | https://www.bookcard.net/wordpress/ |
| 應用程式數量
未來 12 個月內打算在 Google Play 發佈多少應用程式 |
1 |
| Google Play 上賺取收益 | 勾 『是』 勾『廣告』 |
| 應用程式類別 | 勾 『以上皆非』 |
| 聯絡人姓名 | 本名 |
| 聯絡電郵地址 | gmail邮箱 |
| 偏好語言 | 中文(香港) |
| 聯絡電話號碼 | +號+地區代碼+電話號碼 |
| 我確認已閱讀並同意《Google Play 開發人員發行協議》。我確認已年滿 18 歲。 |
| 我確認已閱讀並同意《Google Play 管理中心服務條款》 |
| 我很樂意不定期提供意見,協助改善 Google Play |
| 我想收到新功能公告和各種可協助我改善應用程式的提示 |
| https://payments.google.com |
| https://play.google.com |
| 驗證身分 | 上傳『駕駛執照 』『居民身分證』 |
| 驗證有權使用 Android 流動裝置 | |
| 驗證聯絡電話 |
| 駕駛執照 | |
| 護照 | |
| 居民身分證 |
| 政府簽發的身分證明文件或相片 ID | |
| 公用事業或電話費單 (日期為過去 60 天內) | |
| 銀行結單 (日期為過去 60 天內) | |
| 租賃或按揭協議 |
| 我同意 Google 根據《Google Payments 私隱聲明》收集、使用、保留並處理我的 ID 和個人資料。 |






Google終於出粮,係2025年尾12月30號睌, 填寫電匯付款, 隔日31號夜睌11點到帳. 吾使上傳收据.費事撳出蒞, 諗住買股GOOGLE作為紀念, 不過Gemini3發佈後股價升得太多.依加三百幾美金一股.
電匯付款
| 受款人編號 | 身份證ID |
| 銀行帳戶名稱 | 帳戶姓名,以英文填寫 |
| 銀行名稱 | 以英文填寫 |
| SWIFT碼 | 電匯代碼 |
| 帳戶號碼 | 銀行卡一組數字 |



之前買雜牌5號鋰電, 內阻大跌電快, 平野冇好野.
决定買日本原產『松下ENELOOP 5號鎳氢電池套装』,4粒『ENELOOP 5號電池2000mAh』+『BQ-CC85』重235克, 接近半斤.揸上手重歷歷. 愛蒞用係『Microsoft Sculpt Ergonomic mouse』.
『ENELOOP 電池』有黑色仝白色, 黑色用係大電流設備, 一般設備用白色.而且襟用.
叉機型號『BQ-CC85』, 比『BQ-CC55』新一代. 修復過放電池. 支持110v~220v.
| LED燈 | 狀態 | |
| 予備 | 兩盏赤燈自 | 修復過放電池 |
| 叉電 | 赤燈 | 電量<20% |
| 叉電 | 黄燈 | 20%<電量<80% |
| 叉電 | 綠燈 | 電量>80% |
| 叉满 | 熄燈 | 電量100% |
| 異常 | 電池異常 |
![]()
Windows程式用”LOGO.ICON”仝”SMALL.CION”.但係Photoshop默認吾支持ICON格式.
需安装icon格式擴展插件.
| ICOFormat.8bi | 32BIT版本 |
| ICOFormat64.8bi | 64BIT版本 |
穩到photoshop插件安装路徑.插件以『.8bi』為擴展名.因版本吾仝,安装路徑可能吾仝.
| C:\Program Files\Adobe\Adobe Photoshop CC 2015\Required\Plug-Ins\File Formats |
| C:\Program Files\Adobe\Adobe Photoshop CC 2014\Required\Plug-Ins\File Formats |
重啟Photoshop後,經以可載入『.ico』格式. 但係導出『.ico』格式. 解像度要小於或等於『256*256』.
撳『檔案』->『儲存檔案』
| 『.ico』解像度 | 保存 |
| 『256*256』 | |
| 『128*128』 | |
| 『64*64』 | |
| 『32*32』 | |
| 『16*16』 |







上年係『HSBC匯豐』做定期,到期收埋息. 但系『合資格新資金』鬼甘麻煩,吾做定期改買『KO』收息.『IB盈透證券』入美金, 係匯去香港『花旗銀行』免收電匯費. 講就話壹兩日, 吾使十分鐘『IB』确認電匯存款
| 存款方式 | 時間 |
| 銀行電匯 | 1個工作日 |
| 銀行發起ACH轉帳 | 1個工作日(美國銀行) |
| 關聯銀行帳戶 | 即時轉帳 |
| 在線賬單支付 | 1至6個工作日(美國銀行) |
| 從Wise餘額轉帳 | 幾個小時可以交易 |
| 郵寄支票 | 支票到達IBKR後7個工作日開始交易 |
『銀行電匯』撳『獲取指令』
| 『銀行電匯』 | |
| 保存存取款指令信息? | 是 |
| 匯出機構 | HSBC |
| 賬戶號碼 | HSBC賬戶號碼 |
| 爲您要保存的存取款指令命名 | 求其填 |
| 存款金額 | USD |
撳『下一步』得到電匯資料, 美金寄去香港CITIBANK花旗銀行,
| 支付參考 | 『IB賬號』 |
| 電匯資金至 | 『銀行賬戶』本人姓名 |
| 受益人地址 | 『銀行賬戶』居住地址 |
| SWIFT/BIC代碼 | 花旗銀行SWIFT碼CITIHKHXXXX |
| 虛擬賬戶號碼(VAN) | 存款虛擬賬號: |
| 收款行 | CITIBANK N.A. 50/F Citibank Tower Plaza 3 Garden Road, Central HK Hong Kong 中國香港特別行政區 |
| 金額 | USD |
登錄『HSBC匯豐』
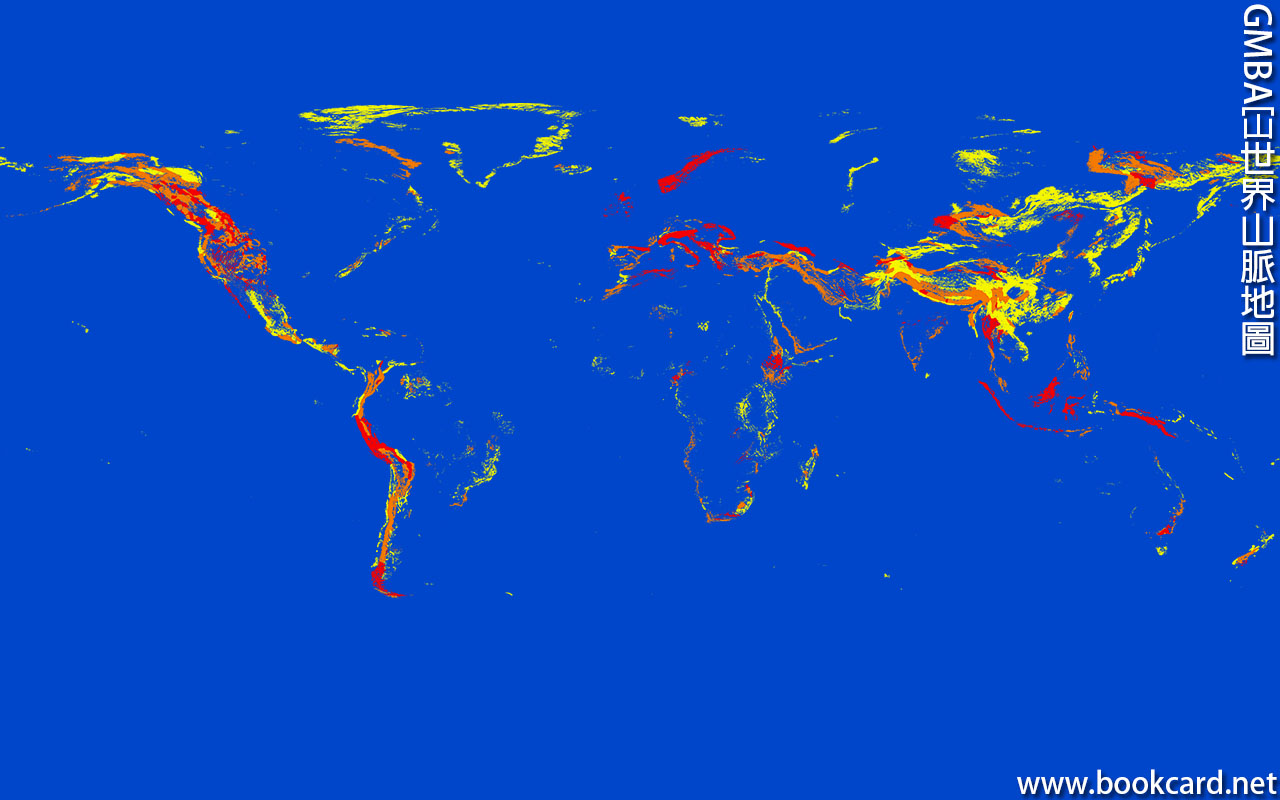
『GMBA』冚世界山地生物多樣性評估計畫, 8616座山脈.登入官網
| https://www.earthenv.org/mountains |
下載數據
| Standard – All | 冚世界:8327座山脈 |
| Standard – Basic | 基础:6717座山脈 |
| Standard – ‘300 selection’ | 300: 291座山脈 |
| Broad – All | 冚世界:8616座山脈 |
| Broad – Basic | 基础:6991座山脈 |
| Broad – ‘300 selection’ | 300: 292座山脈 |
| GMBA_Definition_v2.0 | 山脈定義 |
| GMBA Inventory v2.0 standard | 標准 |
| GMBA Inventory v2.0 broad | 包埋山脉延伸 |
| 欄位 | |
| GMBA_V2_ID: | 山脈唯一識別碼,五位數.將圖斑與山脈資料聯繫. |
| GMBA_V1_ID: | GMBA Inventory v1.0圖斑ID |
| MapName: | 山脈名ASCII,用於標記圖斑(不同山脈存在重名) |
| WikiDataUR: | 唯一資源識別字URI,以字母Q開頭,標識https://www.Wikidata.org/存儲山脈. |
| MapUnit: | 分類變數(Basic/Aggregate)
Basic返回最小山地圖斑. Aggregate返回有子級圖斑,Basic多邊形聚合. |
| Hier_Lvl: | 圖斑級別,1~10 |
| Feature: | 分類變量(14個) |
| Area: | 以Mollweide投影計算山地圖斑平面面積,單位km2, 吾適用於GMBA Inventory v2.0_ broad |
| Perimeter: | 山地圖斑周長,單位km |
| Elev_Low: | DEM計最低海拔 |
| Elev_High: | DEM計最高海拔 |
| Path: | 從級別1大陸/海洋開始, 指向山脈(使用 DBaseName)完整層次路徑 |
| Path_ID: | 與GMBA_V2_ID 一致 |
| Level_01~Level_10: | 地區名 |
| Select_300: | 292個山脈定制,可用於全球和IPCC或 IPBES區域級別分析. |
| Countries: | 與山脈相交國家名/地區名 |
| CountryCodes: | 與山脈相交國家名/地區名Alpha-3 ISO代碼 |
| DBaseName: | 唯一山脈名.冇重名. |
| LocalNames: | Wikidata使用山脈所在國家的語言對山脈或地貌進行命名 |
| AsciiName: | MapName不帶變音符號 |
| Name_AR: | 阿拉伯山脈名 |
| Name_DE: | 德语山脈名 |
| Name_EN: | 英語山脈名 |
| Name_ES: | 西班牙語山脈名 |
| Name_FR: | 法語山脈名 |
| Name_PT: | 葡語山脈名 |
| Name_RU: | 俄語山脈名 |
| Name_ZH | 漢語山脈名 |
| ColorAll: | 0~5,六色,為圖斑著色,連續圖斑冇相同顏色. |
| ColorBasic: | 0~5,六色,為圖斑著色,用於Basic層 |
| Color300: | 0~5,六色,為圖斑著色,用於300層 |
ArcGIS導入『GMBA_Inventory_v2.0_standard.shp』矢量圖.
完整『.shp』矢量圖, 随附文檔有(.shp, .shx, .dbf, .prj …) 係同一資料夹下,且冇損毁.
多邊形轉㸃陣像素.
匯出㸃陣像素. 輸出『.tiff格式』


『ArcGIS地理訊息系統』米國Esri公司, 係上世紀1980年開向量地理程式.
登入『Esri官網』下載ArcGIS
| https://www.esri.com |
早期『ArcGIS.Desktop』依然支援x86/x64-Windows, 去到『ArcGIS.Pro』衹支援x64-Windows.
| 版本 | 支援Windows | |
| ESRI.ArcGIS.Desktop.FULL.v10.8.2 | x86/x64 | |
| ESRI.ArcGIS.Pro.v3.1 | x64 | |
| ESRI.ArcGIS.Pro.v3.0 | x64 | 冇使賬號 |
| ESRI.ArcGIS.Pro.v3.3 | x64 | 冇使賬號 |
| ESRI.ArcGIS.Pro.v3.5 | x64 | 賬號登錄 |
安装『ArcGIS.Pro』
| Click here to participate in the Esri User Experience Improvement program.(Recommended) |
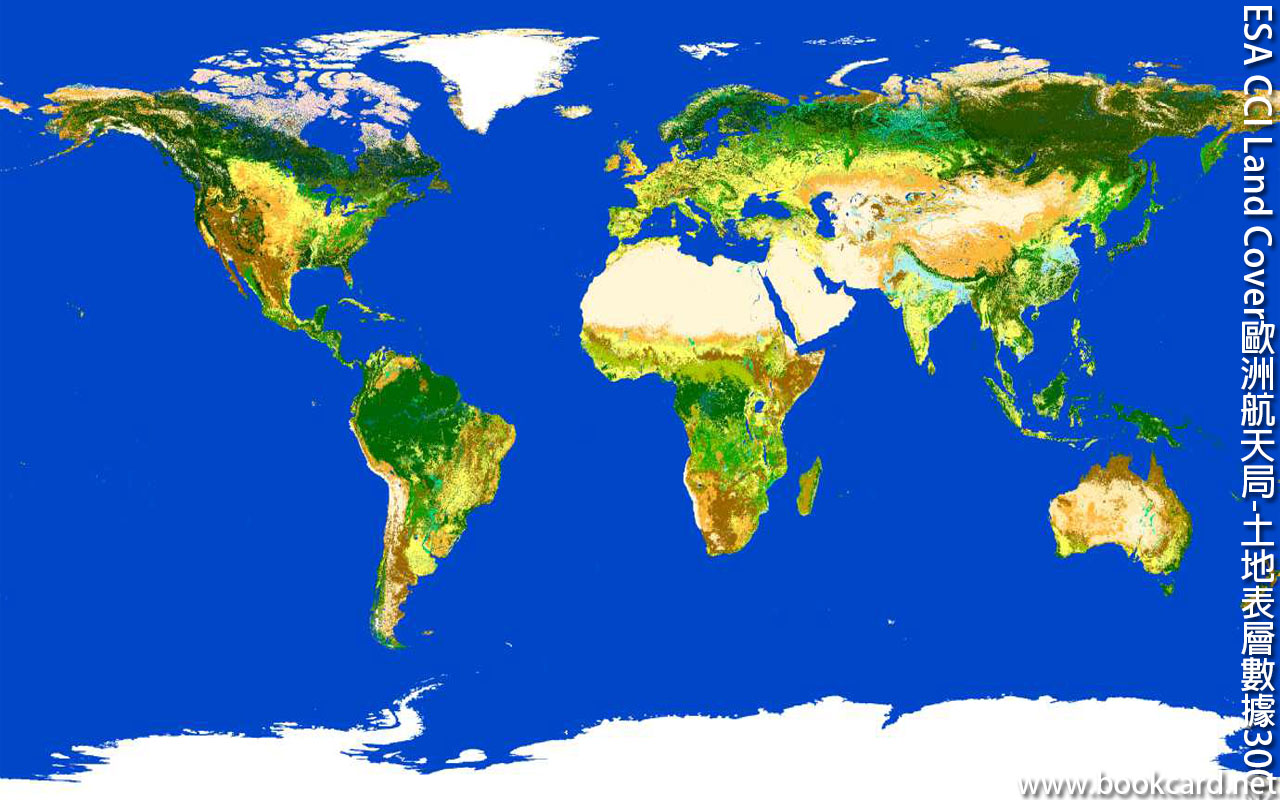
歐洲航天局長期進行頂目, 使用衛星航拍, 分析土地表層數據.解像度300米.
登入『ESA CCI Land Cover』官網,
| http://www.esa-landcover-cci.org/ |
撳『Downloading the CCI LC Products』
撳『http://maps.elie.ucl.ac.be/CCI/viewer/download.php』
係右側填寫訪問資料
撳『Validate』
| http://maps.elie.ucl.ac.be/CCI/viewer/download.php#usertool |
依次下載
| 快速使用者指南 |
| 產品使用者指南 |
| 用戶工具5.0(壓縮) |
| 用戶工具 4.3 描述(文檔) |
下載『FileZilla』登入FTP, 連線伺服器.
| FileZilla | |
| Server: | geo10.elie.ucl.ac.be |
| User: | none |
| password: | none |
下載氣候研究資料包CCI
| ftp://geo10.elie.ucl.ac.be/CCI |
下面有三個資料夾, 冚辦闌下載落蒞.
| LandCover | 土地覆蓋 |
| Seasonality | 季節性 |
| WaterBodies | 水體 |
『.tiff』檔灰度色,photoshop轉為256色, 重新載入調色板
| index | color | text |
| 0 | 0x000000 | 冇數據 |
| 10 | 0xFFFF64 | 雨養耕地 |
| 11 | 0xFFFF64 | 草皮覆蓋 |
| 12 | 0xFFFF64 | 樹木或灌木覆蓋 |
| 20 | 0xAAF0F0 | 灌溉農田或洪水 |
| 30 | 0XDCF064 | 農田(>50%)/自然植被(喬木,灌木,草本植被)(<50%) |
| 40 | 0XC8C864 | 自然植被(喬木,灌木,草本植被)(>50%)/農田(<50%) |
| 50 | 0x006400 | 樹木覆蓋,闊葉,常綠,封閉到開放(>15%) |
| 60 | 0x00A000 | 樹木覆蓋,闊葉,落葉,封閉到開放(>15%) |
| 61 | 0x00A000 | 樹木覆蓋,闊葉,落葉,封閉(>40%) |
| 62 | 0x00A000 | 樹木覆蓋,闊葉,落葉,開放(15-40%) |
| 70 | 0x003C00 | 樹木覆蓋,針葉,常綠,封閉到開放(>15%) |
| 71 | 0x003C00 | 樹木覆蓋,針葉,常綠,封閉(>40%) |
| 72 | 0x003C00 | 樹木覆蓋,針葉,常綠,開放(15-40%) |
| 80 | 0x285000 | 樹木覆蓋,針葉,落葉,封閉到開放(>15%) |
| 81 | 0x285000 | 樹木覆蓋,針葉,落葉,封閉(>40%) |
| 82 | 0x286400 | 樹木覆蓋,針葉,落葉,開放(15-40%) |
| 90 | 0x788200 | 樹木覆蓋,混合葉型(闊葉和針葉) |
| 100 | 0x8CA000 | 混合喬木和灌木(>50%)/草本覆蓋(<50%) |
| 110 | 0xBE9600 | 混合草本覆蓋率(>50%)/喬木和灌木(<50%) |
| 120 | 0x966400 | 灌木叢Shrubland |
| 121 | 0x966400 | 常綠灌木叢 |
| 122 | 0x966400 | 落葉灌木叢 |
| 130 | 0xFFB432 | 草原 |
| 140 | 0xFFDCD2 | 地衣和苔蘚 |
| 150 | 0xFFEBAF | 稀疏植被(喬木,灌木,草本植被)(<15%) |
| 151 | 0xFFFA64 | 稀疏樹木 |
| 152 | 0xFFD278 | 稀疏灌木(<15%) |
| 153 | 0xFFEBAF | 稀疏草本植被(<15%) |
| 160 | 0x00785A | 樹木覆蓋,洪水,淡水或咸水 |
| 170 | 0x009678 | 樹木覆蓋,洪水,鹽水 |
| 180 | 0x00DC82 | 灌木或草本覆蓋物,淹沒,淡水/咸水/微咸水 |
| 190 | 0xC31400 | 都市地區 |
| 200 | 0xFFF5D7 | 裸露區域 |
| 201 | 0xDCDCDC | 合併裸露區域 |
| 202 | 0xFFF5D7 | 未加固裸露區域 |
| 210 | 0x0046CB | 水體 |
| 220 | 0xFFFFFF | 永久冰雪 |

高解像度『TIFF』圖片, 加入『BIGTIFF』規范,使用64bit支緩4GB以上圖片. 支緩『ZIP』壓縮.擴展名『.tf8』『.btf』『.tiff』.
『BIGTIFF』圖檔頭Image File Header(IFH)
| typedef struct BIGTIFF_HEAD_TYP { | BIGTIFF圖檔頭 |
| WORD ByteOrder; | 字節順序 ‘II’ / ‘MM’ |
| WORD version; | BIGTIFF圖檔版本 0x002B |
| WORD ReservedOffset; | 保留 |
| WORD Reserved; | 保留 |
| DWORD64 offset; | 首個IFD偏移量64BIT,邊界對齊4 |
| }BIGTIFF_HEAD, * BIGTIFF_HEAD_PTR; |
區分『BIGTIFF』仝『TIFF』
| #define TIFF_VERSION 0x002A | TIFF圖檔版本 |
| #define BIGTIFF_VERSION 0x002B | BIGTIFF圖檔版本 |
『BIGTIFF』新增三個數據類型
| #define BIGTIFF_TYPE_LONG8 16 | 冇符號8字節(64位)整数 |
| #define BIGTIFF_TYPE_SLONG8 17 | 有符號8字節(64 位)整数 |
| #define BIGTIFF_TYPE_IFD8 18 | 无符号8字節(64位)IFD偏移。 |
『BIGTIFF』新增ZIP壓縮類型 8
| #define TIFF_Compression_ZIP 8 | ZIP壓縮, MAX_WBITS帶 zlib 頭和尾 |
『BIGTIFF』目錄入口 Directory Entry(DE)
| typedef struct BIGTIFF_ENTER_TYP { | 即係數值 |
| WORD tag; | 標識 |
| WORD type; | 數據類型 1~12 16~17 |
| DWORD64 count; | 數量64BIT |
| union {
DWORD64 data; |
數值64BIT |
| DWORD64 offset;
}; |
偏移64BIT |
| }BIGTIFF_ENTER, * BIGTIFF_ENTER_PTR; |
『BIGTIFF』目錄 Image File Directory(IFD)
| typedef struct BIGTIFF_DIRECTORY_TYP { | |
| DWORD64 count; | 目錄數量64BIT |
| BIGTIFF_ENTER enter_array[1]; | 目錄,即係數值 |
| // DWORD64 offset; | 64BIT下壹個偏移-BIGIFD |
| }BIGTIFF_DIRECTORY, * BIGTIFF_DIRECTORY_PTR; |
『高解像圖片』組織成『Tiled瓦片』而非『條帶Strip』, 低中解像圖像用標準『TIFF』『條帶Strip』.『高解像圖片』切割成大致方正塊狀,而非長條『條帶Strip』.壓縮效果更佳.
『Tiled瓦片』取代『StripOffsets』、『StripByteCounts』『RowsPerStrip』. 切忽仝時用『Tiled瓦片』仝『條帶Strip』.
『TileWidth』仝『TileLength』『瓦片』定義寬高. 所有『瓦片』『寬高』相同, 『瓦片』邊界填充.
當『ImageWidth』=129, 『TileWidth』= 64.則分割3個『Tiled瓦片』, 最後一個填充63個像素.
平鋪邊界代價需要浪費一定空間,但係壓縮可以將填充區壓縮到接近0.
即使數據冇壓縮,『Tiled瓦片』祗适用於『高解像圖片』. 『高解像圖片』分割大量『Tiled瓦片』, 填充區祈浪費百分之幾空間,
『Tiled瓦片』被單獨壓縮, 仝『條帶Strip』壓縮一樣. 即每個『Tiled瓦片』數據被視為單獨『條帶Strip』.
『Tiled瓦片』欄位:
| 『Tiled瓦片』欄位: | ||
| TileWidth | SHORT or LONG | 瓦片寬度, 必須16倍數 |
| TileHeight | SHORT or LONG | 瓦片高度, 必須16倍數 |
| TileOffsets | LONG or LONG8 | 瓦片(數據)偏移, 從左到右從上到下的順序排列. |
| TileByteCounts | SHORT or LONG or LONG8 | 瓦片數據字節量, 從左到右從上到下的順序排列. |
載入瓦片數據
| bool Load_Tile_TIFF(TIFF_PTR tiff){ |
| PBYTE tile_buffer; // 瓦片圖像
DWORD64 tile_size; // 瓦片數據字節量 DWORD64 tile_offset;// 瓦片数据偏移 DWORD64 tiles_countX;// 瓦片橫跨 DWORD64 tiles_countY; // 瓦片縱跨 DWORD64 line_size; DWORD64 index, i, j; // 索引 DWORD64 offset;// (數據)偏移. DWORD64 count;// 數據字節量 DWORD64 size;// 寫入量 DWORD64 buffer_offset;// 圖像数据偏移 DWORD64 buffer_size;// 圖像数据字節 |
| tiles_countX = (tiff->ImageWidth + tiff->TileWidth – 1) / tiff->TileWidth;// 瓦片橫跨 |
| tiles_countY = (tiff->ImageHeight + tiff->TileHeight – 1) / tiff->TileHeight;// 瓦片縱跨 |
| tile_size = tiff->TileWidth * tiff->TileHeight * tiff->SamplesPerPixel; // 瓦片數據字節量 |
| tile_buffer = (PBYTE)malloc(tile_size);// 分配記憶體 |
| size = 0;// 寫入量 |
| // 計算圖像所占長度
buffer_size = (tiff->ImageWidth * tiff->ImageHeight) * tiff->SamplesPerPixel; |
| // 定位平鋪/瓦片图像数据
for (j = 0; j < tiles_countY; ++j){ |
| for (i = 0; i < tiles_countX; ++i){ |
| index = j * tiles_countX + i; |
| offset = tiff->TileOffsets[index]; // (數據)偏移.
count = tiff->TileByteCounts[index]; // 數據字節量 |
| // 讀瓦片數據
if (tiff->Compression == TIFF_Uncompressed) {// 未壓縮 memcpy(tile_buffer, tiff->data + offset, count);// 复制图像数据 size = size + count;// 累積寫入量 }else |
| if (tiff->Compression == TIFF_Compression_LZW)
{// LZW 解壓縮 tile_size = ((tiff->TileWidth * tiff->TileHeight) * tiff->SamplesPerPixel); UnCompress_Data_LZW(&_lzw, tile_buffer, &tile_size, tiff->data + offset, count); size = size + tile_size;// 累積寫入量 } else |
| if (tiff->Compression == TIFF_Compression_ZIP)
{// ZIP 解壓縮 DWORD _tile_size = ((tiff->TileWidth * tiff->TileHeight) * tiff->SamplesPerPixel); Uncompress_Data_ZIP(tile_buffer, &_tile_size, tiff->data + offset, (DWORD)count, MAX_WBITS); size = size + _tile_size;// 累積寫入量 } |
| // 寫入瓦片數據
for (DWORD tindex = 0; tindex < tiff->TileHeight; ++tindex) { |
| if ( (j * tiff->TileHeight + tindex) >= tiff->ImageHeight )
break;// 超出 |
| buffer_offset = ( ((j * tiff->TileHeight + tindex) * tiff->ImageWidth) + (i * tiff->TileWidth)) * tiff->SamplesPerPixel;// 圖像数据偏移 |
| tile_offset = tindex * tiff->TileWidth * tiff->SamplesPerPixel;// 瓦片数据偏移 |
| if ((tiff->TileWidth * i) > tiff->ImageWidth)
line_size = (tiff->ImageWidth – (tiff->TileWidth * (i – 1))) * tiff->SamplesPerPixel; else line_size = tiff->TileWidth * tiff->SamplesPerPixel; |
| if (buffer_offset >= buffer_size)
break;// 截斷填充區 |
| memcpy(tiff->buffer + buffer_offset, tile_buffer + tile_offset, line_size);
} } } |
| free(tile_buffer);// 释放
return true; } |

『TIFF圖檔』『Tagged Image File Format』『標記圖檔格式』.擴展名『.tif』或『.tiff』.
首先去『官網』下載tiff圖檔格式指南『tiff6.pdf』.
| https://www.itu.int/itudoc/itu-t/com16/tiff-fx/docs/tiff6.pdf |
| https://download.osgeo.org/libtiff/doc/TIFF6.pdf |
話明係『標記』. 所有數據由『標記』組成. 數據類型多, 長度可變. 支持多種壓縮, 包括『有損壓縮』仝『冇損壓縮』.
『TIFF圖檔』由三個結构體組成
| TIFF圖檔結构體 | 簡述 |
| Image File Header(IFH) | 圖檔頭 |
| Image File Directory(IFD) | 目錄, 保存Directory Entry |
| Directory Entry(DE) | 目錄項-愛蒞保存數據 |
『TIFF圖檔』必定以『Image File Header(IFH)』開始,與眾吾仝係可以保存成『little-endian』或者『big-endian』. 仲可記錄其它格式圖像.
| Image File Header(IFH) | 圖檔頭結构體 |
| WORD ByteOrder; | 字節順序 ‘II’ / ‘MM’ |
| WORD version; | TIFF版本0x002A號, BIGTIFF版本0x002B號 |
| DWORD offset; | 首個IFD偏移量 |
頭兩字節『ByteOrder』字節順序,
| ByteOrder; | 字節順序 |
| ‘II’ | 0x4949 little-endian 細端順序 主機字節 |
| ‘MM’ | 0x4D4D big-endian 大端順序 網路字節 |
『type』圖檔版本0x002A號,
『offset』 首個IFD偏移量,邊界對齊2, 即係2倍數.
壹個TIFF圖檔可能含有多個IFD, 每個IFD都是一個子圖檔.
| Image File Directory(IFD) | 目錄, 保存Directory Entry |
| WORD count; | 數據量 |
| Directory Entry [0]; | 數據0 |
| Directory Entry [1]; | 數據1 |
| Directory Entry [2]; | 數據2 |
| … | |
| DWORD offset; | 下壹IFD偏移, 冇為0. |
| Directory Entry(DE) | 目錄項, 即係數據 |
| WORD tag; | 標簽, 即係name, 下面詳解. |
| WORD type; | 數據類型1~12, 下面詳解. |
| DWORD count; | 數據量 |
| DWORD Value or Offset; | 數據或偏移 |
頭兩字節『tag』標簽.
『type』數據類型, 有12種數據類型,下面介紹.
『count』數據量.
『Value or Offset』數據小於等於4BYTE, 直接擺放數據. 超過4BYTE係偏移
TIFF有12種數據類型.
| 數據類型 | 簡述 |
| 1 | BYTE 8bit冇符號整數 |
| 2 | ASCII字符串, 以NULL結尾 |
| 3 | SHORT-16bit 冇符號短整型 |
| 4 | LONG-32bit 冇符號長整型 |
| 5 | RATIONAL-64bit冇符號分数型,兩個LONG,首LONG係分子,次LONG係分母. |
| 6 | SBYTE-8BIT 有符號整數 |
| 7 | UNDEFINED-8BIT未定義數據 |
| 8 | SSHORT-16BIT 有符號整數 |
| 9 | SLONG-32BIT 有符號整數 |
| 10 | SRATIONAL-64BIT有符號分数型,兩個SLONG,首LONG係分子,次LONG係分母. |
| 11 | FLOAT-4BIT 單精度IEEE格式 |
| 12 | DOUBLE-8BIT 雙精度IEEE格式 |
唯一要講『RATIONAL』64bit冇符號分数型,兩個LONG,首LONG係分子,次LONG係分母.
| typedef struct TIFF_SRATIONAL_TYP { | |
| DWORD molecule; | 首LONG係分子 |
| DWORD denominator; | 次LONG係分母. |
| }TIFF_SRATIONAL, * TIFF_SRATIONAL_PTR; |
『SRATIONAL』64BIT有符號分数型,兩個SLONG,首LONG係分子,次LONG係分母.
| typedef struct TIFF_SRATIONAL_TYP { | |
| int molecule; | 首LONG係分子 |
| int denominator; | 次LONG係分母. |
| }TIFF_SRATIONAL, * TIFF_SRATIONAL_PTR; |
『tag』標簽, 即係數據名.
| tag | type | 簡述 |
| PhotometricInterpretation:
262(0x0106) |
SHORT | 反色顯示.
1=WhiteIsZero白色RGB(0,0,0),黑色RGB(255,255,255). 2=BlackIsZero黑色RGB(0,0,0),白色RGB(255,255,255). 3=RGB 4=RGBPalette 5=TransparencyMask 6=CMYK 7=YCbCr 8=CIELab |
| Compression: 259(0x0103) | SHORT | 1=吾壓縮.
2=霍夫曼壓縮 3=Group 3 Fax 4=Group 4 Fax 5=LZW 6=JPEG 32773=PackBits壓縮 |
| ImageHeight: 257(0x0101) | SHORT or LONG | 圖像高 |
| ImageWidth:256(0x0100) | SHORT or LONG | 圖像寬 |
| ResolutionUnit:296 (0x0128) | SHORT | 解析度單位,計算圖像物理尺碼
1: ratio縱橫比 2: Inch.英寸(默認) 3: Centimeter.釐米 |
| XResolution: 282 (0x011A) | RATIONAL | ImageWidth解析度,X像素解析度,例航拍300m/1000m |
| YResolution:283 (0x011B) | RATIONAL | ImageHeight解析度,Y像素解析度,例航拍300m/1000m |
| RowsPerStrip: 278 (0x0116) | SHORT or LONG | 圖像掃描線長度,等於圖像高度. |
| StripOffsets: 273 (0x0111) | SHORT or LONG | 圖像掃描線(數據)偏移. |
| StripByteCounts: 279 (0x0117) | SHORT or LONG | 圖像數據字節總量 |
| BitsPerSample: 258 (0x0102) | SHORT | 每粒像素位Bit
1=1bit(單色); 4=4bit(16色); 8=8bit(256色) |
| ColorMap: 320 (0x0140) | SHORT | 調色板偏移, 256色和16色圖像先有調色板
3 * (2**BitsPerSample) |
| SamplesPerPixel: 277 (0x0115) | SHORT | 每粒像素字節BYTE
3=(24bit)RGB色 |
| Artist: 315 (0x013B) | ASCII | 創建圖像軟體 |
| CellLength: 265 (0x0109) | SHORT | Threshholding=2 |
| CellWidth: 264 (0x0108) | SHORT | Threshholding=2 |
| Copyright: 33432 (0x8298) | ASCII | 版權聲明: |
| DateTime: 306 (0x0132) | ASCII | 創建日期:
YYYY:MM:DD HH:MM:SS |
| ExtraSamplesa: 338 (0x0152) | SHORT | 說明:
0=未指定數據 1= alpha值(帶預乘顏色) 2=未關聯alpha值 |
| FillOrder: 266 (0x010A) | SHORT |
1= 2= |
| FreeByteCounts: 289 (0x0121) | LONG | free字節量 |
| FreeOffsets: 288 (0x0120) | LONG | free偏移 |
| GrayResponseCurve: 291 (0x0123) | SHORT | 灰度數據-光密度 |
| GrayResponseUnit: 290 (0x0122) | SHORT | 灰度數據-單元
1 |
| HostComputer: 316 (0x013C) | ASCII | 創建圖像操作系統 |
| ImageDescription: 270 (0x010E) | ASCII | 影像描述 |
| Make:271 (0x010F) | ASCII | 掃描儀厰商 |
| MaxSampleValue: 281 (0x0119) | SHORT | |
| MinSampleValue: 280 (0x0118) | SHORT | |
| Model: 272 (0x0110) | ASCII | 掃描儀型號 |
| NewSubfileType: 254 (0x00FE) | LONG | 子檔案中資料類型
ReducedResolution 0x00000001低分辯率; MultiPageImage 0x00000002 多頁影像; TransparencyMask 0x00000004 透明遮罩; |
| Orientation: 274 (0x0112) | SHORT | 影像相對於行和列方向
1:TopLeft 2:TopRight 3:BottomRight 4:BottomLeft 5:LeftTop 6:RightTop 7:RightBottom 8:LeftBottom |
| PhotometricInterpretation: 262 (0x0106) | SHORT | 光度解釋 |
| PlanarConfiguration: 284 (0x011C) | SHORT | 平面配置,祗适用於RGB圖像
1:Chunky塊狀-順序連續存儲RGBRGBRGB(默認) 2: Planar平面-色域獨立存儲RRR..GGG..BBB |
| Software: 305 (0x0131) | ASCII | 創建圖像軟體名稱仝版本 |
| SubfileType:255 (0x00FF) | SHORT | 子檔案中資料類型 |
| Threshholding: 263 (0x0107) | SHORT | 灰色轉黑白 |
| T4Options: 292 (0x0124) | LONG | |
| T6Options: 293 (0x0125) | LONG | |
| DocumentName: 269 (0x0010) | ASCII | 檔案名 |
| PageName:285 (0x011D) | ASCII | 掃描圖頁面名 |
| PageNumber: 297 (0x0129) | SHORT | 掃描圖頁面碼 |
| XPosition: 286 (0x011E) | RATIONAL | 影像X位置 |
| YPosition: 287 (0x011F) | RATIONAL | 影像Y位置 |
| Predictor: 317 (0x013D) | SHORT | 預測器一種數學運算-僅用於LZW壓縮
1:編碼前未使用預測方案(默認) 2:水平差分 |
| TileWidth: 322 (0x0142) | SHORT or LONG | 平鋪寬度 |
| TileLength: 323 (0x0143) | SHORT or LONG | 平鋪高度 |
| TileOffsets: 324 (0x0144) | LONG | 平鋪偏移 |
| TileByteCounts: 325 (0x0145) | SHORT or LONG |
| Compression | #259(0x0103) SHORT 壓縮類型 |
| Uncompressed | 1:未壓縮 |
| CCITT1D | 2 |
| Group3Fax | 3 |
| Group4Fax | 4 |
| LZW | 5: LZW冇損壓縮, 默認 |
| JPEG | 6: JPEG有損壓縮, |
| PackBits | 32773: |
| PhotometricInterpretation | 反色顯示 |
| WhiteIsZero | 1 |
| BlackIsZero | 2 |
| RGB | 3 |
| RGBPalette | 4 |
| TransparencyMask | 5 |
| CMYK | 6 |
| YCbCr | 7 |
| CIELab | 8 |
| ResolutionUnit | 解析度單位,計算圖像物理尺碼 |
| Ratio | 1 :縱橫比 |
| Inch | 2:英寸(默認) |
| Centimeter | 3:釐米 |
| NewSubfileType | 子檔案資料類型 |
| ReducedResolution | 0x00000001低解像 |
| MultiPageImage | 0x00000002:多頁影像 |
| TransparencyMask | 0x00000004:透明遮罩 |
| Orientation | 影像相對於行列方向 |
| TopLeft | 1 |
| TopRight | 2 |
| BottomRight | 3 |
| BottomLeft | 4 |
| LeftTop | 5 |
| RightTop | 6 |
| RightBottom | 7 |
| LeftBottom | 8 |
| BitsPerSample | 每粒像素位Bit |
| 4 | 灰階圖像4bit(16色)/調色板圖像4bit(16色) |
| 8 | 灰階圖像8bit(256色)彩色./調色板圖像8bit(256色)彩色. |
| R=8,G=8,B=8 | TIFF-(RGB Images)RGB影像 |
| R=8,G=8,B=8,A=8 | TIFF-(RGBA Images)RGBA影像 |
| PlanarConfiguration | 平面配置,祗适用於RGB圖像 |
| Chunky | 1:塊狀-順序連續存儲RGBRGBRGB(默認) |
| Planar | 2:平面-色域獨立存儲RRR..GGG..BBB |
| Predictor | 預測器一種數學運算-僅用於LZW壓縮 |
| NO | 1:壓縮前未使用預測方案(默認) |
| Horizontaldifferencing | 2:水平差分 |
如果『ByteOrder』係 ‘MM’-0x4D4D『網路字節』, 要轉為『主機字節』. 定義宏指令.
| #define TIFF_NET2HOST_WORD(_VALUE) ( ((_VALUE & 0x00FF) << 8) | ((_VALUE & 0xFF00) >> 8) ) |
| #define TIFF_NET2HOST_DWORD(_VALUE) ( ((_VALUE & 0x000000FF) << 24) | ((_VALUE & 0x0000FF00) << 8) | ((_VALUE & 0x00FF0000) >> 8) | ((_VALUE & 0xFF000000) >> 24) ) |
| #define TIFF_NET2HOST_DWORD64(_VALUE) ( ((_VALUE & 0x00000000000000FF) << 56) | ((_VALUE & 0x000000000000FF00) << 48) | ((_VALUE & 0x0000000000FF0000) << 40) | ((_VALUE & 0x0000000000FF0000) << 32) | ((_VALUE & 0x00000000FF000000) >> 8) | ((_VALUE & 0x000000FF00000000) >> 16) | ((_VALUE & 0x0000FF0000000000) >> 24) | ((_VALUE & 0x00FF000000000000) >> 32) | ((_VALUE & 0xFF00000000000000) >> 40) ) |
定義TIFF結构, 愛蒞保存分析數據.
| typedef struct TIFF_TYP { | |
| WORD ByteOrder; | 字節順序 ‘II’ / ‘MM’ |
| WORD version; | TIFF圖檔版本 |
| DWORD NewSubfileType; | 子檔案中資料類型 |
| DWORD PhotometricInterpretation; | 反色顯示. |
| DWORD Compression; | 1=吾壓縮. |
| DWORD bitCount; | 像素bits:8位,16位,24位,32位 |
| WORD BitsPerSample[4]; | 每粒像素位BitCount,1=1bit(單色);4=4bit(16色);8=8bit(256色); |
| DWORD SamplesPerPixel; | 位圖像素Bytes:2byte,3byte,4byte; |
| DWORD ImageHeight; | 圖像高 |
| DWORD ImageWidth; | 圖像寬 |
| DWORD Orientation; | 影像方向 |
| DWORD ResolutionUnit; | 解析度單位,計算圖像物理尺碼. 1:縱橫比,2英寸(默認),3釐米 |
| TIFF_RATIONAL XResolution; | ImageWidth解析度,X像素解析度,例航拍300m/1000m = molecule/denominator; |
| TIFF_RATIONAL YResolution; | ImageHeight解析度,Y像素解析度,例航拍300m/1000m = molecule/denominator;
|
| DWORD RowsPerStrip; | 圖像條帶(數據)行數(高度),可能最後一條帶除外. |
| PDWORD64 StripOffsets; | 圖像條帶(數據)偏移. |
| PDWORD64 StripByteCounts; | 圖像數據字節量 |
| DWORD64 StripCount; | 條帶數量 |
| DWORD PlanarConfiguration; | 平面配置 |
| char * ExtraSamplesa; | 說明: |
| char * Software; | 創建圖像軟體名稱仝版本 |
| char * DateTime; | 創建日期: |
| DWORD Predictor; | 預測器一種數學運算-僅用於LZW壓縮 |
| TIFF_PALETTEENTRY palette[256]; | 調色板,用於4bit/8bit模式. |
| PBYTE data; | 原始數據 |
| PBYTE buffer; | 圖像 |
| }TIFF, * TIFF_PTR; |
载入TIFF分析標簽
| bool Load_TIFF(TIFF_PTR tiff, PBYTE data, int size){ |
| TIFF_HEAD_PTR head;// 圖檔頭Image File Header(IFH) |
| tiff->data = data;// 原始數據 |
| head = (TIFF_HEAD_PTR)data;// TIFF圖檔頭 |
| if (tiff->ByteOrder != TIFF_LITTLE_ENDIAN && tiff->ByteOrder != TIFF_BIG_ENDIAN)
return false; |
| if (tiff->ByteOrder == TIFF_BIG_ENDIAN)// ‘MM’ 大端字節 網路字節 net
{ // 網路字節 轉 主機字節 head->version = TIFF_NET2HOST_WORD(head->version); head->offset = TIFF_NET2HOST_DWORD(head->offset); } |
| tiff->version = head->version;// TIFF圖檔版本
if (tiff->version == TIFF_VERSION)// TIFF圖檔版本 { TIFF_DIRECTORY_PTR directory; // 目錄 directory = (TIFF_DIRECTORY_PTR)((PBYTE)data + head->offset); Parse_Directory_TIFF(tiff, directory);// 分析數據 } |
|
// 載入8或16,32Bit圖像 if (tiff->bitCount == 16 || tiff->SamplesPerPixel == 2) Load_Grayscale_TIFF(tiff);// 載入數據 else if (tiff->bitCount == 8 || tiff->SamplesPerPixel == 1) Load_Palette_TIFF(tiff);// 載入數據 else if (tiff->bitCount == 24 || tiff->SamplesPerPixel == 3) Load_RGB_TIFF(tiff);// 載入數據 else if (tiff->bitCount == 32 || tiff->SamplesPerPixel == 4) Load_RGBA_TIFF(tiff);// 載入數據 |
| return true;
} |
分析數據
| bool Parse_Directory_TIFF(TIFF_PTR tiff, TIFF_DIRECTORY_PTR directory) { |
| if (tiff->ByteOrder == TIFF_ENDIAN_BIG)// ‘MM’ 大端字節 網路字節 net
directory->count = TIFF_NET2HOST_WORD(directory->count);// 網路字節 轉 主機字節 |
| for (int index = 0; index < directory->count; ++index)
Parse_Enter_TIFF(tiff, &directory->enter_array[index]);// 分析數據 |
| return true;
} |
分析數據
| bool Parse_Enter_TIFF(TIFF_PTR tiff, TIFF_ENTER_PTR enter)
{ |
| if (tiff->ByteOrder == TIFF_ENDIAN_BIG)// ‘MM’ 大端字節 網路字節 net
{// 網路字節 轉 主機字節 enter->tag = TIFF_NET2HOST_WORD(enter->tag);// 標識 enter->type = TIFF_NET2HOST_WORD(enter->type);// 數據類型 1~12 enter->count = TIFF_NET2HOST_DWORD(enter->count);// 數量 enter->data = TIFF_NET2HOST_DWORD(enter->data);// 數據 } |
| if (enter->tag == TIFF_TAG_NewSubfileType)//子檔案中資料類型
tiff->NewSubfileType = enter->data; else |
| if (enter->tag == TIFF_TAG_PhotometricInterpretation)// 反色顯示.
tiff->PhotometricInterpretation = enter->data; else |
| if (enter->tag == TIFF_TAG_Compression)// 壓縮.
tiff->Compression = enter->data; else |
| if (enter->tag == TIFF_TAG_ImageHeight)// 圖像高
tiff->ImageHeight = enter->data; else |
| if (enter->tag == TIFF_TAG_ImageWidth)// 圖像寬
tiff->ImageWidth = enter->data; else |
| if (enter->tag == TIFF_TAG_ResolutionUnit) // 解析度單位,計算圖像物理尺碼 . 1:縱橫比,2英寸(默認),3釐米
tiff->ResolutionUnit = enter->data; else |
| if (enter->tag == TIFF_TAG_XResolution)// ImageWidth解析度,X像素解析度,例航拍300m/1000m
Parse_XResolution_TIFF(tiff, enter); else |
| if (enter->tag == TIFF_TAG_YResolution) // ImageHeight解析度,Y像素解析度,例航拍300m/1000m
Parse_YResolution_TIFF(tiff, enter); else |
| if (enter->tag == TIFF_TAG_Orientation)// 影像相對於行和列方向
tiff->Orientation = enter->data; else |
| if (enter->tag == TIFF_TAG_ColorMap)//調色板偏移, 256色和16色圖像先有調色板
Parse_ColorMap_TIFF(tiff, enter); else |
| if (enter->tag == TIFF_TAG_BitsPerSample)// 每粒像素位BitCount,1=1bit(單色);4=4bit(16色);8=8bit(256色);
Parse_BitsPerSample_TIFF(tiff, enter); else |
| if (enter->tag == TIFF_TAG_SamplesPerPixel)// RGB圖像,每粒像素字節BYTE
tiff->SamplesPerPixel = enter->data; else |
| if (enter->tag == TIFF_TAG_StripOffsets)// 圖像掃描線(數據)偏移.
Parse_StripOffsets_TIFF(tiff, enter); else |
| if (enter->tag == TIFF_TAG_StripByteCounts) //圖像數據字節總量
Parse_StripByteCounts_TIFF(tiff, enter); else |
| if (enter->tag == TIFF_TAG_RowsPerStrip)// 圖像條帶(數據)行數(高度),可能最後一條帶除外.
tiff->RowsPerStrip = enter->data; else |
| if(enter->tag == TIFF_TAG_PlanarConfiguration)// 平面配置,祗适用於RGB圖像
tiff->PlanarConfiguration = enter->data; else |
| if(enter->tag == TIFF_TAG_ExtraSamplesa)// 說明
tiff->ExtraSamplesa = Malloc_ASCII_TIFF((const char*)(tiff->data + enter->offset)); else |
| if (enter->tag == TIFF_TAG_Software) // 創建圖像軟體名稱仝版本
tiff->Software = Malloc_ASCII_TIFF((const char*)(tiff->data + enter->offset)); else |
| if (enter->tag == TIFF_TAG_DateTime)// 創建日期:
tiff->DateTime = Malloc_ASCII_TIFF((const char*)(tiff->data + enter->offset)); else |
| if(enter->tag == TIFF_TAG_Predictor)// 僅用於LZW編碼
tiff->Predictor = enter->data; |
| return true;
} |

LZW壓縮算法, 三位發眀家『Lemple』『Ziv』『Welch』首字母組合而蒞.
LZW『壓縮』『解壓』算法極高速無損,算法基於『字符串表string_table』, 映射代碼Code』和『字符串string』,重要它極易實現. 易於嵌入程式, 壓縮數據.
|
LZW壓縮 |
|
|
STRING |
字符/數據, 文本代表字符, 圖像代表數值 |
|
prefix |
前綴字符串 |
|
suffix |
後綴字符串 |
|
+ |
連接字符串 |
|
code |
代碼,字符串代碼編號. |
|
string_table |
字典/字符串表存放–『代碼Code』和『字符串string』 |
首先定義『STRING字符串』結构.
|
typedef struct LZW_STRING_TYP { |
|
|
int code; |
代碼,代碼應盡量短,至多12Bit |
|
BYTE data[64]; |
字符/數據 |
|
int length; |
字符/數據長度 |
|
}LZW_STRING, * LZW_STRING_PTR; |
|
CODE限制12BIT代碼, 字典至多4096個字符串.
|
#define LZW_MAX_STRING 4096 |
(2^12) |
定義『LZW』結构.
|
typedef struct LZW_TYP |
|
|
PBYTE sour; |
蒞源數據 |
|
DWORD sour_position; |
蒞源數據當前位置 |
|
DWORD sour_position_bit; |
跟踪BIT邊界 |
|
DWORD sour_length; |
蒞源數據長度 |
|
PBYTE dest; |
目標數據緩存 |
|
DWORD dest_size; |
目標緩存長度 |
|
DWORD dest_position; |
目標數據當前位置 |
|
DWORD dest_position_bit; |
跟踪BIT邊界 |
|
int string_count; |
字典量 |
|
LZW_STRING string_table[LZW_MAX_STRING]; |
字典/字符串表 |
|
}LZW, * LZW_PTR; |
|
初始字典/字符串表,初值有256個,編號係0~255, 字符/數據亦係0~255, 係255之後定義兩個代碼『清除碼ClearCode=256』 仝『結束碼EoiCode=257』, 一共258.
|
#define LZW_CODE_CLEAR 0x0100 |
0x0100(256) 清除碼 ClearCode |
|
#define LZW_CODE_EOI 0x0101 |
0x0101(257) 結束碼 EoiCode |
初始字典/字符串表,
|
bool Init_StringTable_LZW(LZW_PTR lzw) { |
|
for (index = 0; index < 256; ++index){ |
|
lzw->string_table[index].code = index; |
|
lzw->string_table[index].length = 1; |
|
lzw->string_table[index].data[0] = index; |
|
} |
|
code = LZW_CODE_CLEAR; |
|
lzw->string_table[LZW_CODE_CLEAR].code = LZW_CODE_CLEAR; // 清除碼 |
|
lzw->string_table[LZW_CODE_CLEAR].length = 2; |
|
memcpy(lzw->string_table[LZW_CODE_CLEAR].data, &code, 2); |
|
code = LZW_CODE_EOI; |
|
lzw->string_table[LZW_CODE_EOI].code = LZW_CODE_EOI; // 結束碼 |
|
lzw->string_table[LZW_CODE_EOI].length = 2; |
|
memcpy(lzw->string_table[LZW_CODE_EOI].data, &code, 2); |
|
lzw->string_count = 258; |
|
} |
將代碼CODE寫入輸出流,首個代碼係『ClearCode#256』, 以『EOICode#257』結束.
因為係壓縮數據,數據将吾以8BIT/16BIT對齊, 代碼Code以字典字符量跟踪Bit邊界.首個CODE將是9Bit代碼小於512. 字典量達係#510 之後10Bit代碼小於1024. 係#1022之後11Bit代碼小於2048. 係#2046之後12Bit代碼小於4096.代碼左移至高位,接連上個代碼.
|
bool Write_Code_LZW(LZW_PTR lzw, DWORD code) { |
|
int bits = 9; |
|
PBYTE data; |
|
if (lzw->string_count <= LZW_MASK_9BIT) bits = 9; else if (lzw->string_count <= LZW_MASK_10BIT) bits = 10; else if (lzw->string_count <= LZW_MASK_11BIT) bits = 11; else if (lzw->string_count <= LZW_MASK_12BIT) bits = 12; |
|
int byte_offset = lzw->dest_position_bit / 8; int bis_offset = lzw->dest_position_bit % 8; |
|
code = code << (32 – bits); code = code >> bis_offset; |
|
data = (PBYTE) &code; |
|
for (int i = 0; i < 4; ++i){ *(lzw->dest + byte_offset + i) = *(lzw->dest + byte_offset + i) | data[4 – i – 1]; |
|
if (byte_offset + i >= lzw->sour_length) break; // 數據尾,跳出 |
|
} |
|
lzw->dest_position_bit = lzw->dest_position_bit + bits;// 蒞源數據當前位置 |
|
lzw->dest_position = lzw->dest_position_bit / 8;// 蒞源數據當前位置 |
|
return true; |
|
} |
加入字符串至字典.首個添加到字串將位於258.
|
bool Add_StringTable_LZW(LZW_PTR lzw, LZW_STRING_PTR string){ |
|
WORD index; |
|
LZW_STRING_PTR str; |
|
index = lzw->string_count; |
|
++lzw->string_count; |
|
str = &lzw->string_table[index]; |
|
str->code = index;// 代碼應盡量短,至多12Bit |
|
str->length = string->length; |
|
memcpy(str->data, string->data, string->length); |
|
return true; |
|
} |
讀蒞源CHAR字符, 未壓縮數據
|
bool Read_NextChar_LZW(LZW_PTR lzw, LZW_STRING_PTR string){ |
|
BYTE data; |
|
if (lzw->sour_position + 1 > lzw->sour_length) return false; // |
|
data = *(lzw->sour + lzw->sour_position); |
|
lzw->sour_position = lzw->sour_position + 1;// 蒞源數據當前位置 |
|
string->data[0] = data; |
|
string->length = 1; |
|
return true; } |
壓縮算法步驟:
|
bool Compress_Data_LZW(PBYTE dest, DWORD* dest_length, PBYTE sour, DWORD sour_length){ |
|
LZW lzw; LZW_STRING prefix;// 前綴字符 LZW_STRING suffix;// 後綴字符 LZW_STRING string; WORD code;// 代碼 Init_LZW(&lzw, dest, *dest_length, sour, sour_length); // 初始LZW |
|
Init_StringTable_LZW(&lzw); // 初始字典 |
|
Write_Code_LZW(&lzw,LZW_CODE_CLEAR); // 寫目標 |
|
Zero_String_LZW(&prefix);// 前綴字符串清零 |
|
while (Read_NextChar_LZW(&lzw, &suffix)) { // 讀下一字符,後綴字符 |
|
Copy_String_LZW(&string, &prefix); // 前綴 Cat_String_LZW(&string, &suffix);// 前綴+後綴 |
|
if ( Find_StringTable_LZW(&lzw, &string, &code) ){ // 字符串查代碼 Cat_String_LZW(&prefix, &suffix);// 後綴 = 前綴+後綴 } else |
|
{ |
|
Find_StringTable_LZW(&lzw, &prefix, &code);// 查找前綴 |
|
Write_Code_LZW(&lzw, code);// 將CODE代碼寫入輸出流 |
|
// 前綴+後綴 Copy_String_LZW(&string, &prefix); // 前綴 Cat_String_LZW(&string, &suffix);// 前綴+後綴 |
|
Add_StringTable_LZW(&lzw,&string);// 加入字符串至條目表 |
|
Copy_String_LZW(&prefix, &suffix); // 後綴變前綴 |
|
} } |
|
Find_StringTable_LZW(&lzw, &prefix, &code);// 查找前綴 |
|
Write_Code_LZW(&lzw, code);// 將CODE代碼寫入輸出流 |
|
Write_Code_LZW(&lzw, LZW_CODE_EOI);// 將CODE代碼寫入輸出流 |
|
*dest_length = lzw.dest_position; // 輸出压缩長度 |
|
if (lzw.dest_position_bit / 8 != 0) ++(*dest_length); |
|
return true; } |
讀壓縮CODE代碼,必須跟踪Bit邊界. 代碼右移至低位,提取代碼. 代碼Code以字典字符量跟踪Bit邊界.首個CODE將是9Bit代碼小於512. 字典量達係#510 之後10Bit代碼小於1024. 係#1022之後11Bit代碼小於2048. 係#2046之後12Bit代碼小於4096.
|
WORD Read_NextCode_LZW(LZW_PTR lzw){ |
|
DWORD data; int bits = 9; |
|
if (lzw->string_count <= LZW_MASK_9BIT) // 小於512 bits = 9; else if (lzw->string_count <= LZW_MASK_10BIT) // 小於1024 bits = 10; else if (lzw->string_count <= LZW_MASK_11BIT) // 小於2048 bits = 11; else if (lzw->string_count <= LZW_MASK_12BIT) // 小於4096 bits = 12; |
|
int byte_offset = lzw->sour_position_bit / 8; int bis_offset = lzw->sour_position_bit % 8; |
|
data = (*(lzw->sour + byte_offset)) << (24+bis_offset) | (*(lzw->sour + byte_offset + 1)) << (16+bis_offset) | (*(lzw->sour + byte_offset + 2)) << ( 8+bis_offset) ; |
|
data = data >> (32 – bits); |
|
lzw->sour_position_bit = lzw->sour_position_bit + bits;// 蒞源數據當前位置 lzw->sour_position = lzw->sour_position_bit / 8;// 蒞源數據當前位置 |
|
return (WORD)data; } |
壓縮算法步驟:
|
bool UnCompress_Data_LZW(PBYTE dest, DWORD* dest_length, PBYTE sour, DWORD sour_length){ |
|
LZW lzw; WORD code = 0; WORD OldCode = 0; LZW_STRING string; LZW_STRING OldString; |
|
if ( dest == NULL || dest_length == NULL || sour == NULL || sour_length == 0) return false; |
|
Init_LZW(&lzw, dest, *dest_length, sour, sour_length); // 初始LZW |
|
while (TRUE) { |
|
code = Read_NextCode_LZW(&lzw);// 讀蒞源數據 |
|
if (code == LZW_CODE_EOI)// 結束碼 break;// 數據結束 |
|
if (code == LZW_CODE_CLEAR) { // 清除碼 |
|
Init_StringTable_LZW(&lzw);// 初始字典 |
|
code = Read_NextCode_LZW(&lzw);// 讀蒞源數據 |
|
if (code == LZW_CODE_EOI)// 結束碼 break;// 數據結束 |
|
Find_StringTable_LZW(&lzw, code, &string); |
|
Write_String_LZW(&lzw, &string);// 將字符串寫入輸出流 |
|
OldCode = code; } |
|
else { |
|
// 代碼稳查字符串 if (Find_StringTable_LZW(&lzw, code, &string)) { |
|
Write_String_LZW(&lzw, &string); // 將字符串寫入輸出流 |
|
Find_StringTable_LZW(&lzw, OldCode, &OldString); // 代碼稳查字符串 |
|
Cat_String_LZW(&OldString, &string, 1); // 連接字符串 |
|
Add_StringTable_LZW(&lzw, &OldString); // 加入字符串至條目表 |
|
OldCode = code; } |
|
else{ // 代碼稳查字符串 Find_StringTable_LZW(&lzw, OldCode, &OldString); |
|
Cat_String_LZW(&OldString, &OldString, 1); // 連接字符串 |
|
Write_String_LZW(&lzw, &OldString); // 將字符串寫入輸出流 |
|
Add_StringTable_LZW(&lzw, &OldString); // 加入字符串至條目表 |
|
OldCode = code; |
|
} } } |
|
*dest_length = lzw.dest_position; // 輸出压缩長度 |
|
return true; } |

地球話明係球,緊係圓,地球咁大, 通過航海家通過羅盤确定航向, 但係首先要得知當前位置, 用經緯蒞定位.遠遠係希臘時代,經已識得通過矔星,得知『緯度』, 『緯度越高越接近兩極,緯度越低接近赤道, 『赤道』划分『北半球』仝『南半球』.
| 『北半球』用『北緯』表示,『北緯』係正.0°~90° |
| 『南半球』用『南緯』表示,『南緯』係負. 0°~-90° |
『經度』直至『摆动定律』發現 『飛陀』每擺壹次稳定係壹秒. 英國佬再發明『陀鐘』. 所以『經度』即『時區』. 壹目24小時就有24『時區』.『經度』仝『時區』可以相互轉换
通過『北極』仝『南極』兩點畫直線叫『子午線』, 以英國倫敦『格林威治天文台』『子午線』定『0°』,
| 『零度子午線』以東为正, 即東經.0°~360° |
| 『零度子午線』以西为負, 即西經. 0°~-360° |
地球『南北極』兩極導致气候差異, 劃分出五個气候帶
| 北寒帶-北極圈 | 北緯66°34′~北緯90° |
| 北溫帶 | 北緯23°26′~北緯66°34′ |
| 熱帶 | 北緯23°26′~南緯23°26′ |
| 南溫帶 | 南緯23°26′~南緯66°34′ |
| 南寒帶-南極圈 | 南緯66°34′~南緯90° |
開發應用程式,總要存儲大量設定.以便重啟時讀取. 係android系統分『內部』仝『外部』存儲.
內部存儲: 衹有程式能夠訪問, 屬於私人吉間. 最重要冇需額外權限. 但係吉間細, 適宜存儲程式設定. 卸載程式後數據自動清除.
外部存儲: 冚辦闌外部程式皆可訪問,屬於公眾地方. 需要額外權限. 吉間大. 適宜存儲文檔. 通常位於SD卡, 或者係磁盤獨立劃出分區實現. 卸載程式後數據保留.
| 内部存儲 | getFilesDir() |
| 外部存儲 | getExtemalFilesDir() |
『getFilesDir()』返回路徑大約如下, 需然可以手工生成, 但係有可能路徑吾仝. 所以總係調用『getFilesDir()』返回内部存儲路徑.
| /data/data/com.example.appname/files |
因『getFilesDir()』返回JAVA字符串, 要轉為C字符串.
| const char * path ; jboolean isCopy; path = (*env).GetStringUTFChars( java_path, &isCopy); |
保存路徑后, 要释放C字符串. 否則造成記憶體泄漏.
| if(path != NULL) (*env).ReleaseStringUTFChars(java_path,path ); |
C創建并寫入文檔, 用『open()』函式
| Int open(const char * pathame,int flags, … /*mode_t mode*/ ); |
引用頭文檔
| #include <fcntl.h> | open()函式 |
| #include <errno.h> | errno全局變量 |
| flags: | 訪問標記 |
| O_WRONLY | 衹寫模式 |
| O_RDONLY | 衹讀模式 |
| O_CREAT | 創建文檔 |
| O_TRUNC | 截斷文檔,長度0. |
| O_APPEND | 總係文檔屘追加數據 |
| mode | 文檔讀寫許可權 |
| S_IWUSR | 用戶-寫權限 |
| S_IRUSR | 用戶-讀權限 |
| S_IRGRP | 群組-寫權限 |
| S_IWGRP | 群組-讀權限 |
| S_IROTH | 其他用户 寫權限 |
| S_IWOTH | 其他用户 讀權限 |
開啟寫文檔要創建文檔, 所以你仲要指定文檔讀寫權限.
| 開啟寫文檔 |
| int flags = O_WRONLY | O_CREAT | O_TRUNC | O_APPEND ; |
| int mode = S_IWUSR | S_IRUSR | S_IRGRP | S_IWGRP | S_IROTH | S_IWOTH; |
| int handle = open(filename, flags, mode); |
開啟祗讀文檔,忽再設罝文檔讀寫權限, 否則『errno』返回『EACCES』許可權被拒.
| 開啟祗讀文檔 |
| int handle = open(filename, O_RDONLY); |
近排臺雜牌手機.個USB口接触吾好,叉電仲免强, 但係『android studio』真機DEBUG調試, 更係認吾到手機. 好再新版『android studio』支緩冇線WIFI, 真機DEBUG調試. 冇線叉電, 冇線偵錯, USB使用率下降, 睇以後手機壽命更長.
係『ANDROID STUDIO』
係『ANDROID 手機』
撳『使用QR code配對装置』掃上面二維碼.


上次張『Lucky2-25GB』高速數據, 25GB高速用曬後降為512kbps, 睇youtube免强流暢, 上civitai壹類網站难.
索性買過張『Lucky2上網卡-日韓港澳中台30GB高速數據』.升级30GB.之後低速512kbps,任用一年,插卡後開通『數據漫遊』.即插即用吾使實名登記.
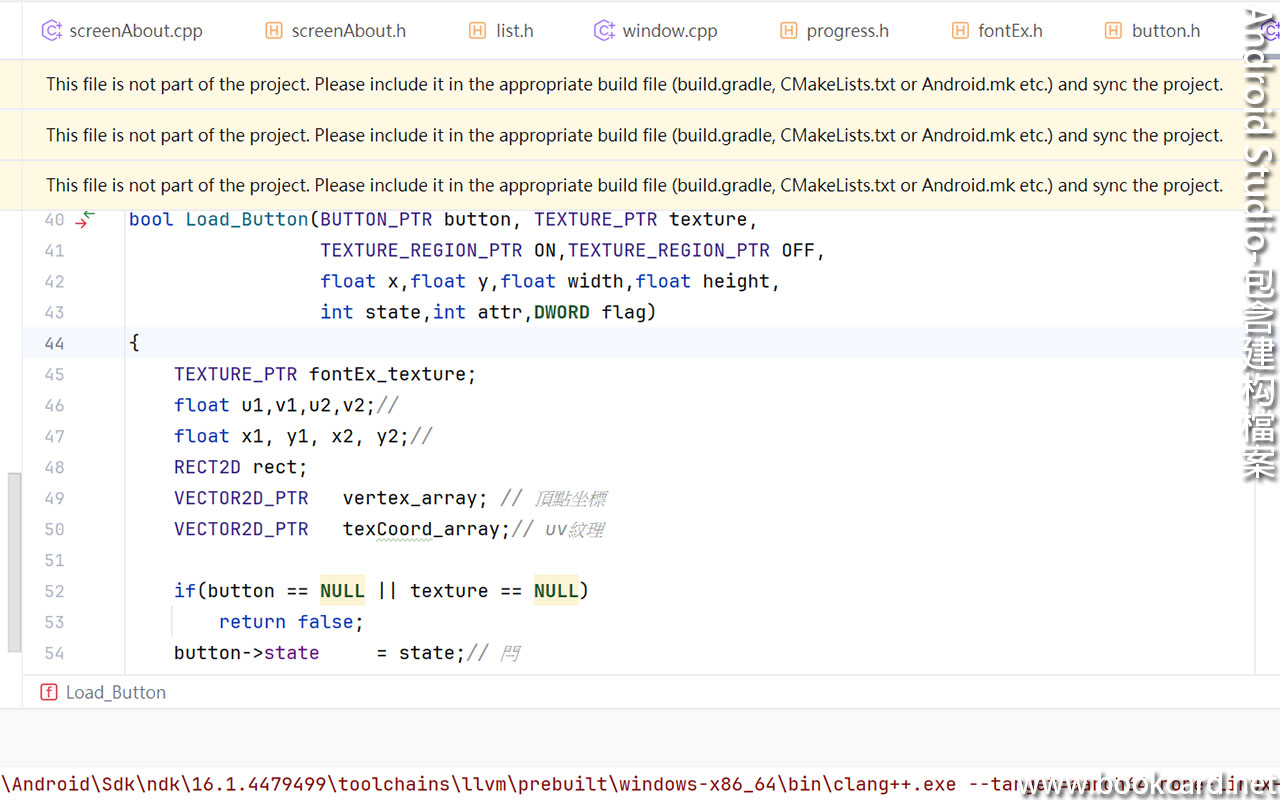
近日『Android Studio』編譯C/C++項目『button.cpp』報錯,檔案非專案一部分,係『CMakeList.txt』仝『native-lib.cpp』包含建构檔案.
| This file is not part of the project. Please include it in the appropriate build file (build.gradle, CMakeLists.txt or Android.mk etc.) and sync the project |

Android Studio-支持C/C++語法分析『Clang-Tidy』, 但係默認禁用.
| Unable to execute Clang-Tidy: Clang-Tidy is not found or cannot be executed |
啟用『Clang-Tidy』語法分析.
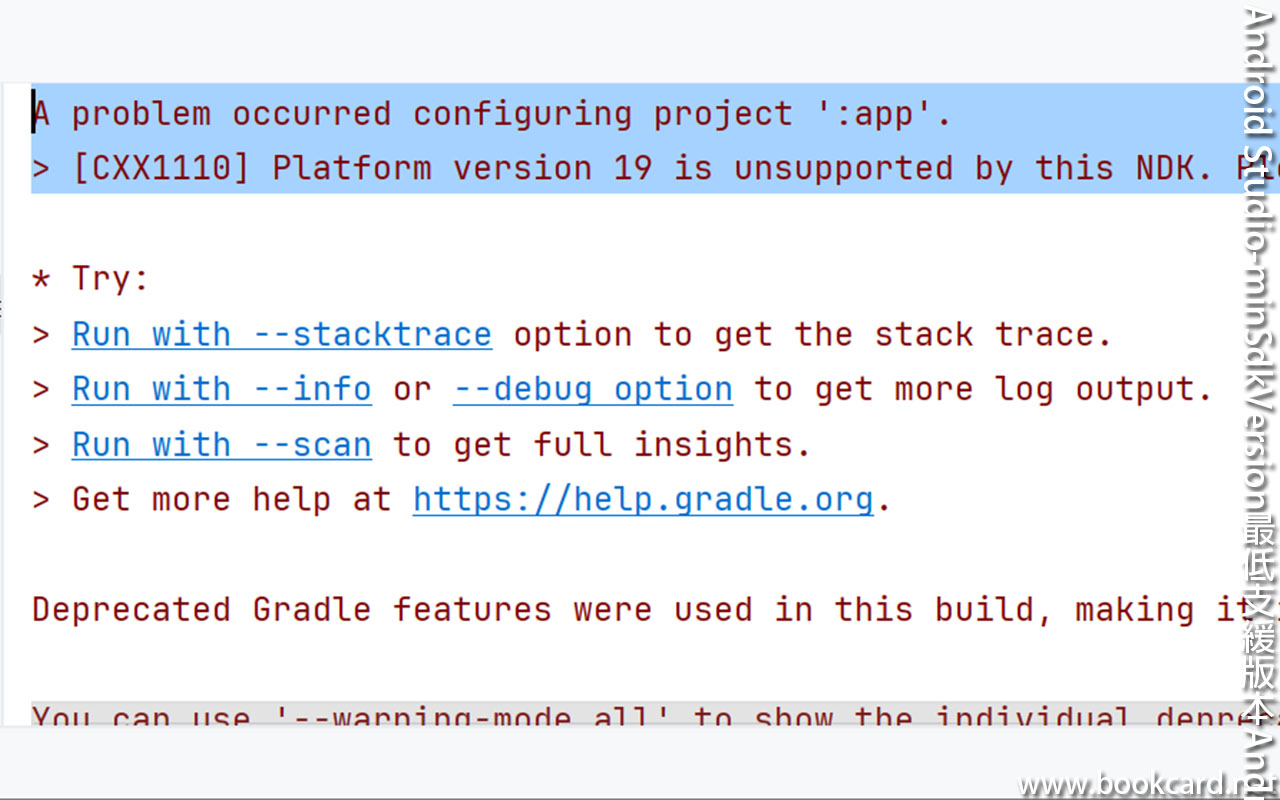
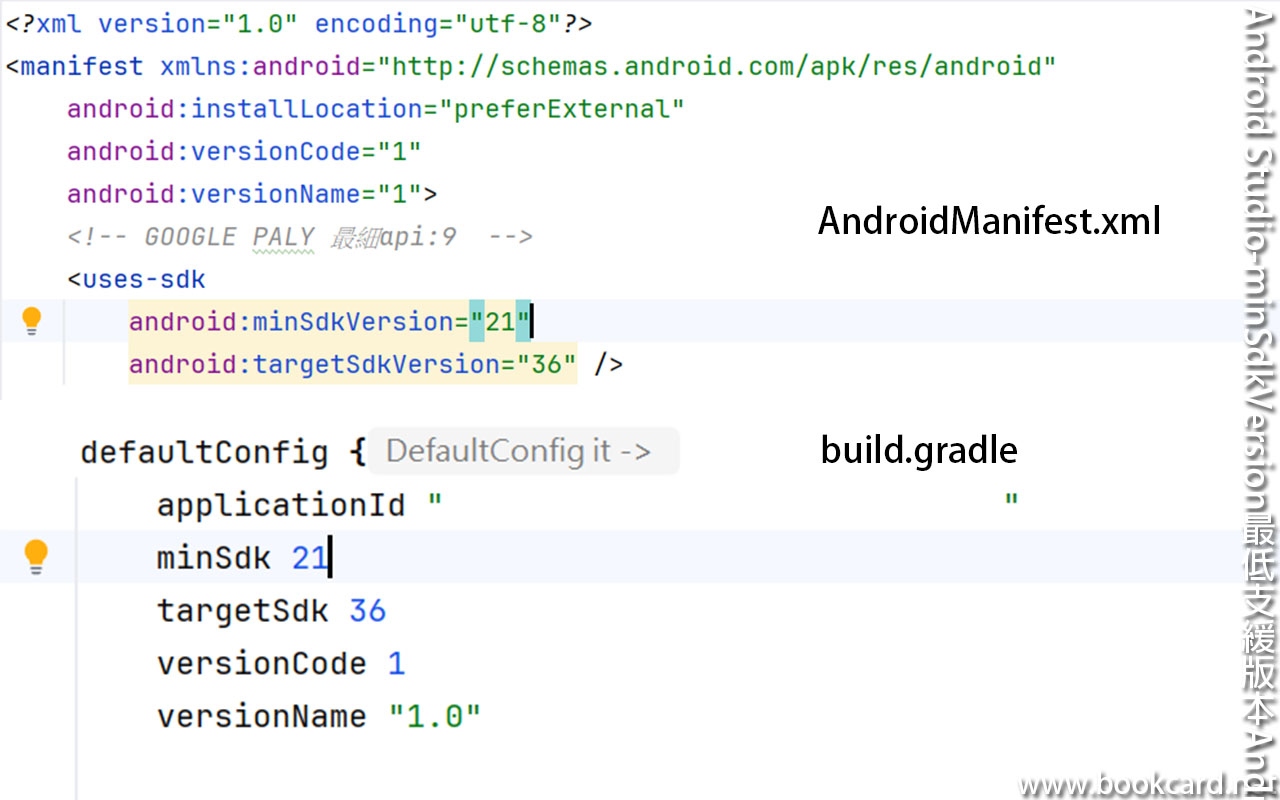
『Android Studio』當前NDK版本吾支持『Android 19』平臺, 請將minSdk改為『Android 21』.
祗係試過『NDK』改為『16.1.4479499』仝樣吾支持『Android 19』平臺.
| D:\ANDROID\appname\app\src\main\AndroidManifest.xml |
| <uses-sdk android:minSdkVersion=”21″ android:targetSdkVersion=”36″ /> |
| D:\ANDROID\appname\app\build.gradle |
| minSdk 21 |
| A problem occurred configuring project ‘:app’.
> [CXX1110] Platform version 19 is unsupported by this NDK. Please change minSdk to at least 21 to avoid undefined behavior. To suppress this error, add android.ndk.suppressMinSdkVersionError=21 to the project’s gradle.properties or set android.experimentalProperties[“android.ndk.suppressMinSdkVersionError”]=21 in the Gradle build file. |

裝Android Studio 集成『Open JDK』同『Android SDK』『Android NDK』, 『debug』 調試要選『app』自動連手機.
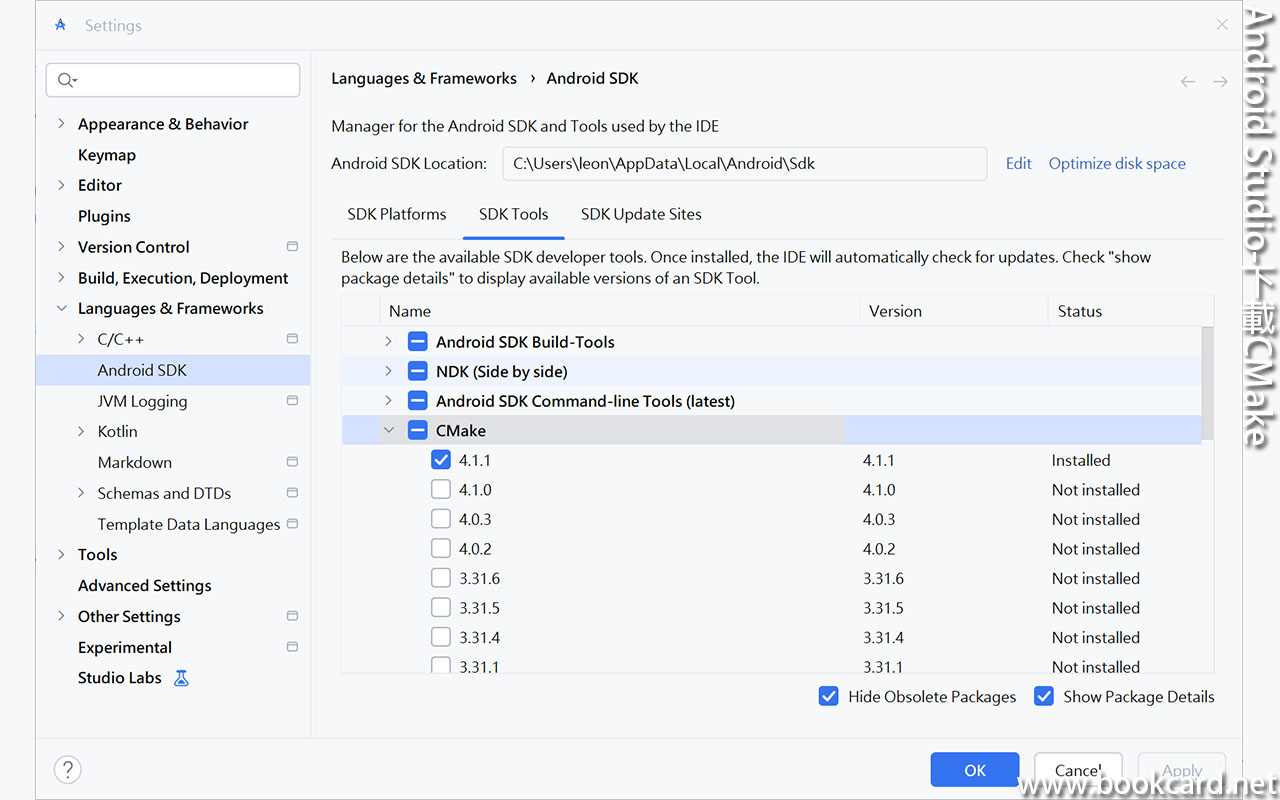
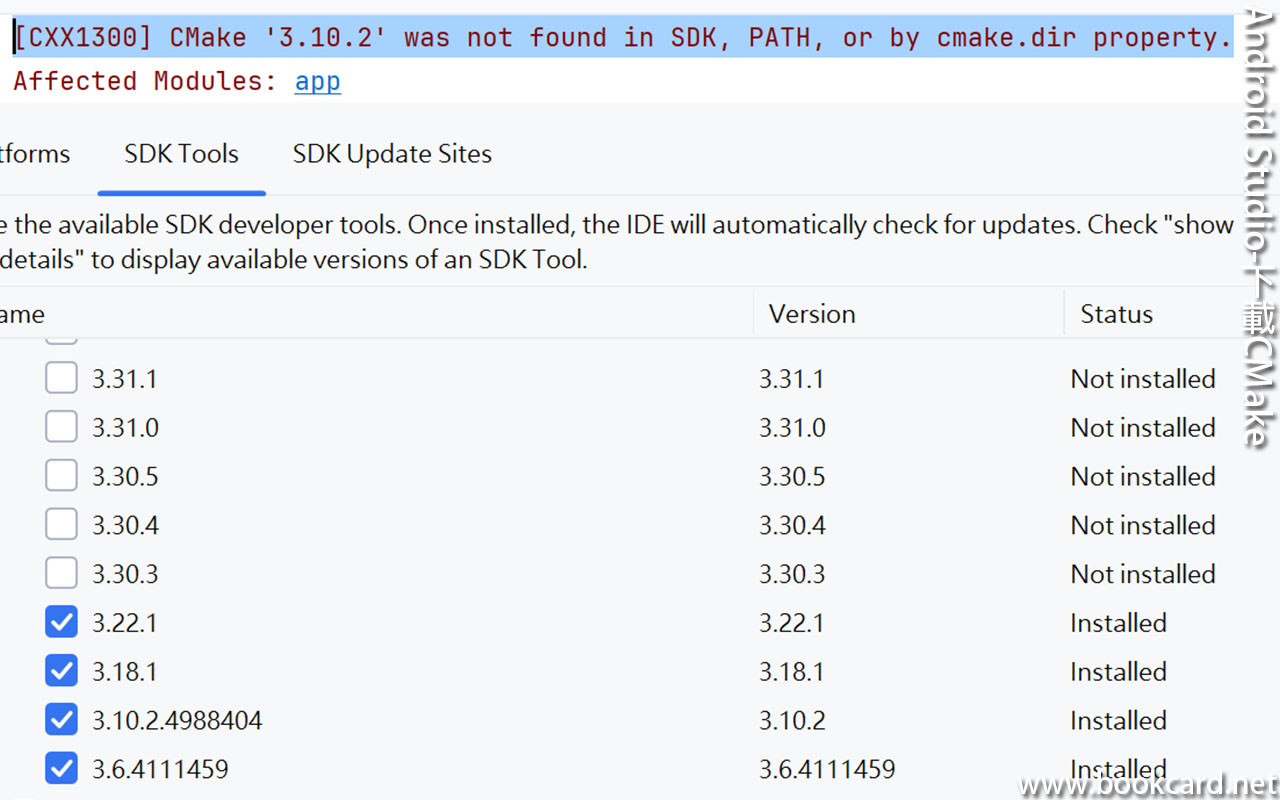
CMake未将或版本號吾,導致穩吾到『cmake』,下載對應『cmake』版本.
| D:\ANDROID\appname\app\src\main\cpp\CMakeLists.txt |
| cmake_minimum_required(VERSION 3.10.2) |
| D:\ANDROID\appname\app\build.gradle |
| cmake { path file(‘src/main/cpp/CMakeLists.txt’) version ‘3.10.2’ } |
| [CXX1300] CMake ‘3.10.2’ was not found in SDK, PATH, or by cmake.dir property.
Affected Modules: app |

『buildconfig』欄位現在預設啟用,冇需顯式設定,編輯『gradle.properties』係『android.defaults.buildfeatures.buildconfig』行前加注釋符『#』.
| D:\ANDROID\appname\gradle.properties |
| # android.defaults.buildfeatures.buildconfig=true |
| The option setting ‘android.defaults.buildfeatures.buildconfig=true’ is deprecated. |
| The current default is ‘false’. |
| It will be removed in version 10.0 of the Android Gradle plugin. |
| To keep using this feature, add the following to your module-level build.gradle files: |
| android.buildFeatures.buildConfig = true |
| or from Android Studio, click: `Refactor` > `Migrate BuildConfig to Gradle Build Files`. |
Android Studio因『Gradle JDK』與『JAVA_HOME』位置吾仝導致編譯中斷,可能會生成多個Gradle守護進程. 要將項目『Gradle JDK』位置與『JAVA_HOME』一致.
| Multiple Gradle daemons might be spawned because the Gradle JDK and JAVA_HOME locations are different.
Project ‘app’ is using the following JDK location when running Gradle: ‘C:\Users\username\.jdks\jbr-17.0.14’ The system environment variable JAVA_HOME is: ‘C:\Program Files\Android\Android Studio\jbr’ If you dont need to use different paths (or if JAVA_HOME is undefined), you can avoid spawning multiple daemons by setting JAVA_HOME and the JDK location to the same path. |
| More info… |
| Select the Gradle JDK location |
| Do not show this warning again |
Android Studio 編譯時鎖定檔案, 以免被仝時修改. 若鎖定協議版本改變,會報版本錯誤,可嘗試清除APP檔案下『gradle』資料夾, 之後再重建Project
| Unexpected lock protocol found in lock file. Expected 3, found 0. |
刪除『gradle』資料夾,之後再重建Project.
| D:\ANDROID\appname\gradle |












『講古寮』係緊『講古』架埗. 清未係東校場南便.有塊爛地通復星里.
有人搭幾間一連三便簡陋茶寮,每日正午12點前後有大量市民集結.1㸃准時開講, 講古佬上座,擺長檯,驚堂木,茶壼,茶杯.香爐. 講古佬 口沬橫飛,手舞足蹈. 聽眾聽得入神. 香爐㸃香計時收錢,兼中場休息賣花生瓜子.經歷戰火後清拆, 依家『講古寮』變成地名或專欄.
琴日Android Studio重新編譯舊工程, 發現 jcenter()報錯, 事源Gradle已廢棄jcenter()倉庫, 其實之前一直警告,此依賴庫即將關閉. 編輯『settings.gradle』将 jcenter() 替換為 mavenCentral()搞掂.
|
|
| D:\ANDROID\GeomanticCompass\settings.gradle |
| dependencyResolutionManagement { repositoriesMode.set(RepositoriesMode.FAIL_ON_PROJECT_REPOS) repositories { google() mavenCentral() //jcenter() // Warning: this repository is going to shut down soon } } |
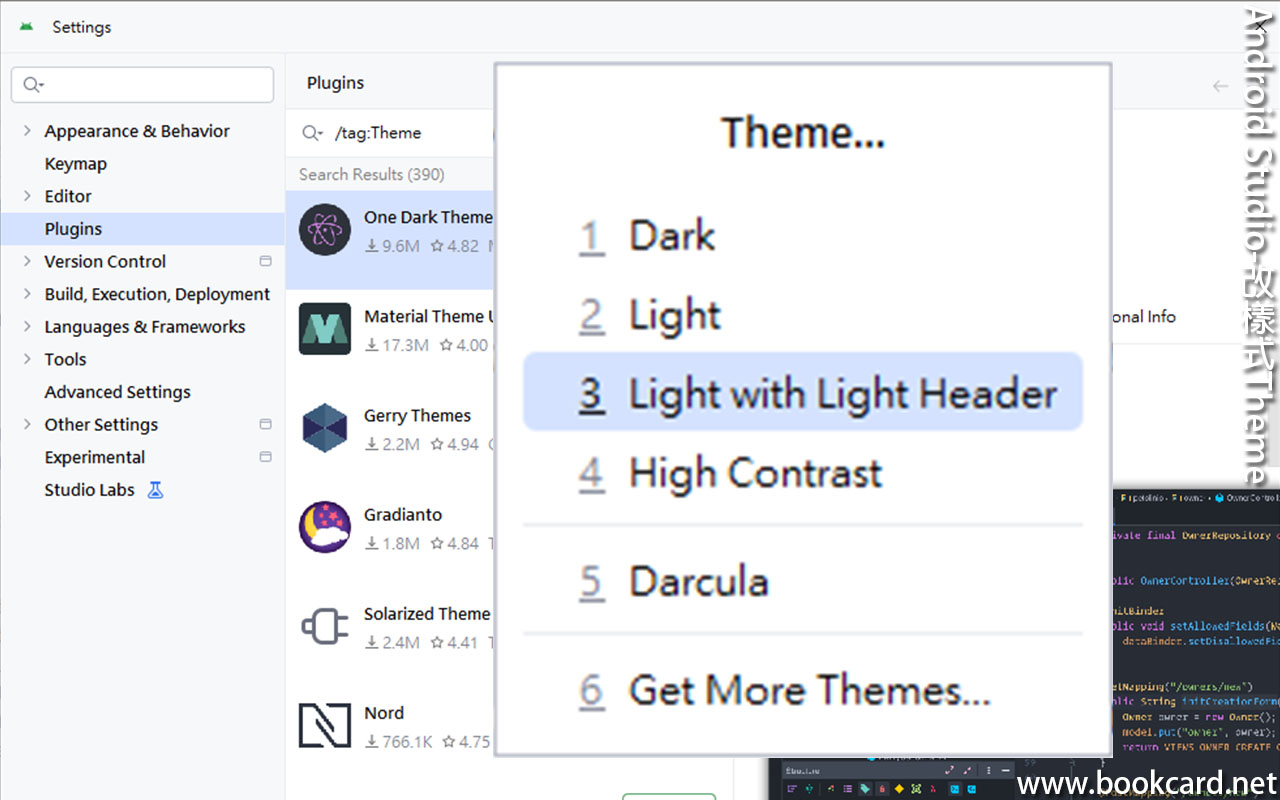
最新版『Android Studio』默認系Dark暗黑樣式,改為Light光明樣式.
| Theme | 樣式 |
| Dark | 暗黑系 |
| Light | 光明系 |
| Light With Light Header | 標题光明系 |
| High Contrast | 高对比 |
| Darcula | 暗黑系 |
| Get More Themes | 樣式下載 |
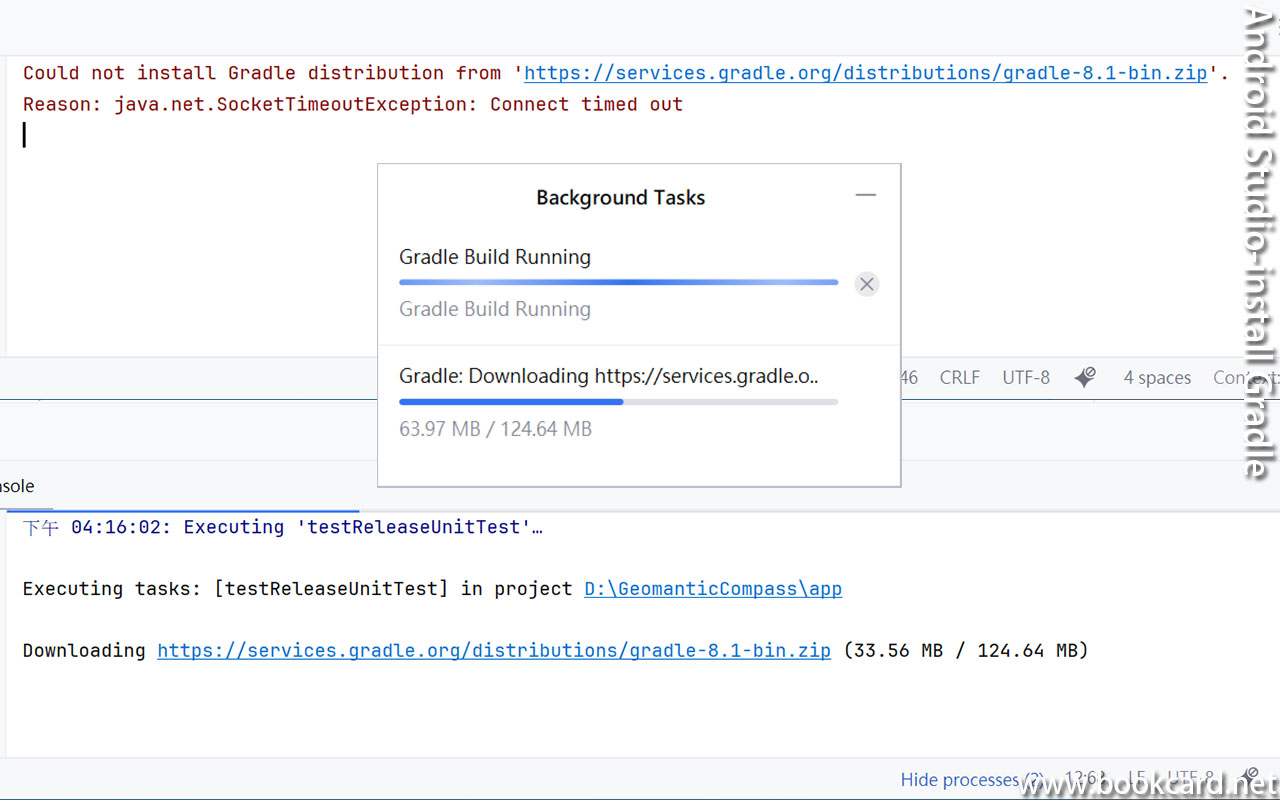
下載Gradle如果網絡超時, 導致下載失敗. 可嘗改targetSdkVersion版本號. 再次啟動Gradle下載.
| Could not install Gradle distribution from ‘https://services.gradle.org/distributions/gradle-8.1-bin.zip’. |
| Reason: java.net.SocketTimeoutException: Connect timed out |
改targetSdkVersion版本號.
| <uses-sdk android:minSdkVersion=”9″ android:targetSdkVersion=”36″ /> |
再次啟動Gradle下載.
| Executing tasks: [testReleaseUnitTest] in project D:\GeomanticCompass\app |
| Downloading https://services.gradle.org/distributions/gradle-8.1-bin.zip (25.17 MB / 124.64 MB) |



前幾日『Windows10專業版』自動升級『Windows11專業版』.發現『SolidWorks2018』授權失效. 記得五六年前仝老細買『Windows10企業版LTSC』, 係網上有2021版, 內含『DVD-ROM』仝『KEY』, 細問係咪:『正版?』,老細話可以官方激活. 問價70紋,順豐快遞到付12, 一共82紋.



九龍去新界沿途經多座大山, 搭火車捐山窿, 搭汽車要爬山, 爬山落山,左轉右轉, 先到新界,, 沙田, 大埔, 粉嶺, 上水. 風景幽美, 空氣新鮮, 西人鐘意係庶起別墅, 禮拜六禮拜奉旨嘆世界, 坐汽車去別墅, 打哥夫, 玩音樂,
但係香港至新界, 必經過條猛鬼橋. 係沙田仝大埔之間, 條橋搭係半山, 長三丈. 山勢險峻, 峰迴路轉.年中吾少汽車失事, 連車帶人, 錄录落山坑當堂變鬼, 歷年死於橋底過百人, 冤鬼太多, 天未黑現身, 揾人替身.
戰前德利洋行大班『摩斯』, 揾到大把貨, 係粉嶺起閒別墅歎世界, 休假奉旨仝老婆去粉嶺別墅, 司機『李炳』忠實, 『摩斯』賞賜有加『李炳』聲行家話, 猛鬼橋好猛鬼, 時時出蒞揾人替身, 『李炳』保, 每次駛過, 必萬分小心, 缓慢駛過.
『亞奇老竇生亞奇』『摩斯』適蓬禮拜六放晏晝, 諗住仝老婆仔去粉嶺別墅度假,『摩斯』有些少事務延至晏晝四點出車, 『李炳』揸車由佐敦道碼頭過海, 跟住彌敦道, 青山道一路駛上, 駛至山上, 暮色迷離, 黑雲出岫.
揸至離猛鬼橋五六十丈,斜路收油, 李炳離遠望見有一鬼佬企正橋中, 神高神大, 將近揸埋, 望真個鬼佬, 身材高大,頭仔細細,黑影緾罩.
李炳當堂剎停臺車大呌: 有鬼.
摩斯: 哈嘮! 做乜唔去!
李炳一指橋上: 摩斯腥! 你睇嚇, 見吾見!
摩斯一睇: 冇事去囉有鬼都要去, 吾通響庶過夜咩?
李炳冇謁, 著大燈, 入一波, 吊住極力子 揸上橋,将近黐埋身,鬼嘩一聲,直撲車內.李柄一驚, 左腳一鬆, 成架車鏟落山坑. 當堂散架. 李柄大呌, 好彩天未黑齊. 後面有車蒞. 稳人救起.
『亞奇老竇生亞奇-奇上加奇』,『李炳』仝『摩斯夫人』毛都冇甩條,但係『摩斯』眼耳口鼻 五孔出血,當堂瓜得.
等朝,港府開堂研究,㸃解同一部車.『李炳』仝『摩斯夫人』冇傷,而『摩斯』慘死,研蒞研去都未知死因,好彩『摩斯夫人』做證,吾係會話『李炳』謀殺.
『三水佬睇走馬燈-陸續有蒞』,繼續發生事故. 後蒞工務司擬定計畫, 鏟平山尖, 令辟山道, 避開猛鬼橋.

點過兩支蠟燭
紮馬紮到周身郁

點過兩支蠟燭
紮馬紮到周身郁

點過兩支蠟燭
紮馬紮到周身郁

點過兩支蠟燭
紮馬紮到周身郁
功夫門派,除『洪劉蔡李莫』五大名家外, 仲有『詠春派』『嶺東派』『白鶴派』『蔡李佛派』等,羊城禪城一帶工商業發達,武館徒弟以工人為多,日頭翻工,夜晚先有時間練功夫,獅虎教徒極嚴,坐係橫頭櫈,手撚四孖藤鞭, 指揮紮馬打樁, 徒弟稍有吞泡, 一句『丟那媽』, 鞭隨聲下, 皮破血流. 慈祥師母整定『煲粥』仝『燒買』,等徒弟練功後喫宵夜,所以『練功夫』又叫『喫夜粥』.
| 喫過兩晚夜粥 |
| 點過兩支蠟燭 |
| 紮馬紮到周身郁 |














上次粒『AMD Ryzen5 5600X』畀我跌彎,依鋪『AMD Ryzen7 5800X』搭『Gigabyte X570 AORUS MASTER』,預先買定『幽靈棱鏡Wraith MAX』加強散, 装『幽靈棱鏡Wraith MAX』最好落AM4防撥支架, 原厰硅脂黏性强,拆果陳容易連CPU連根撥起. 但係粒U有105W, 個舊機壹冚蓋, 播條片都過90度輕機重啟.
柝左原厰風扇,换『AVC-12038-12v-3.12A-PWM』,處於Default模式CPU(1 Core) 閂門稳定.
係OC模式CPU(ALL Cores)冇冚盖通風優良,擺係書臺柜, 依然輕機重啟.
壹直以為係 CPU散熱風扇吾够力.其實係粒U體質吾好, 默認38倍頻,高負荷輕機重啟. 好彩X570可以調倍頻, 降低到37.5倍頻. 主頻稳定係3750.高負荷冇再輕機重啟. 諗蒞上手發現粒U體質吾好,失至買出蒞.
| 風扇 | 轉速PRM | 噪音 | Default-CPU(1 Core) | OC-CPU(ALL Cores) |
| AVC-12038-3.12A | 7500轉 | 猛虎呌气 | 最高90℃ | 輕機重啟 |
| DELTA-12038-1.6A | 4355轉 | 接受 | 最高90℃ | 輕機重啟 |
| QISU-14038-1.45A | 4623轉 | 平順 | 最高90℃ | 輕機重啟 |
| DELTA-15050-1.8A-AI | 3000轉 | 靜音 | 最高90℃ | 輕機重啟 |
| AVC-15050-1.8A | 6818轉 | 靜音 | 最高90℃ | 輕機重啟 |
| DELTA-8038-1.35A | |
| DELTA-12038-1.6A |
| CPU-AMD-AM4- | CPU-Z Single Thread | CPU-Z Multi Thread |
| AMD Ryzen5 1500X | 342 | 2244.2 |
| AMD Ryzen5 5600X | 512 | 4042.6 |
| AMD Ryzen7 5800X | 607.4 | 6711.1 |
| AMD Ryzen7 5800X | |
| 散熱 | 幽靈棱鏡Wraith MAX |
| TDP | 105W |
| 核芯速度Core Speed | 3600 HMz |
| 電壓Core Voltage | 1.2v |
| 基頻Bus Speed | 100HMz |
| 倍頻Multplier | 37 |
| 核芯Cores | 8核 |
| 線程Threads | 16 |
| 步進Stepping | 0 |
| CPU-AMD-AM4- | CPU-Z Single Thread | CPU-Z Multi Thread |
| AMD Ryzen5 1500X | 342 | 2244.2 |
| AMD Ryzen5 5600X | 512 | 4042.6 |
| AMD Ryzen7 5800X | 607.4 | 6711.1 |
| AMD Ryzen7 5800X | |
| 散熱 | 幽靈棱鏡Wraith MAX |
| TDP | 105W |
| 核芯速度Core Speed | 3600 HMz |
| 電壓Core Voltage | 1.2v |
| 基頻Bus Speed | 100HMz |
| 倍頻Multplier | 37 |
| 核芯Cores | 8核 |
| 線程Threads | 16 |
| 步進Stepping | 0 |



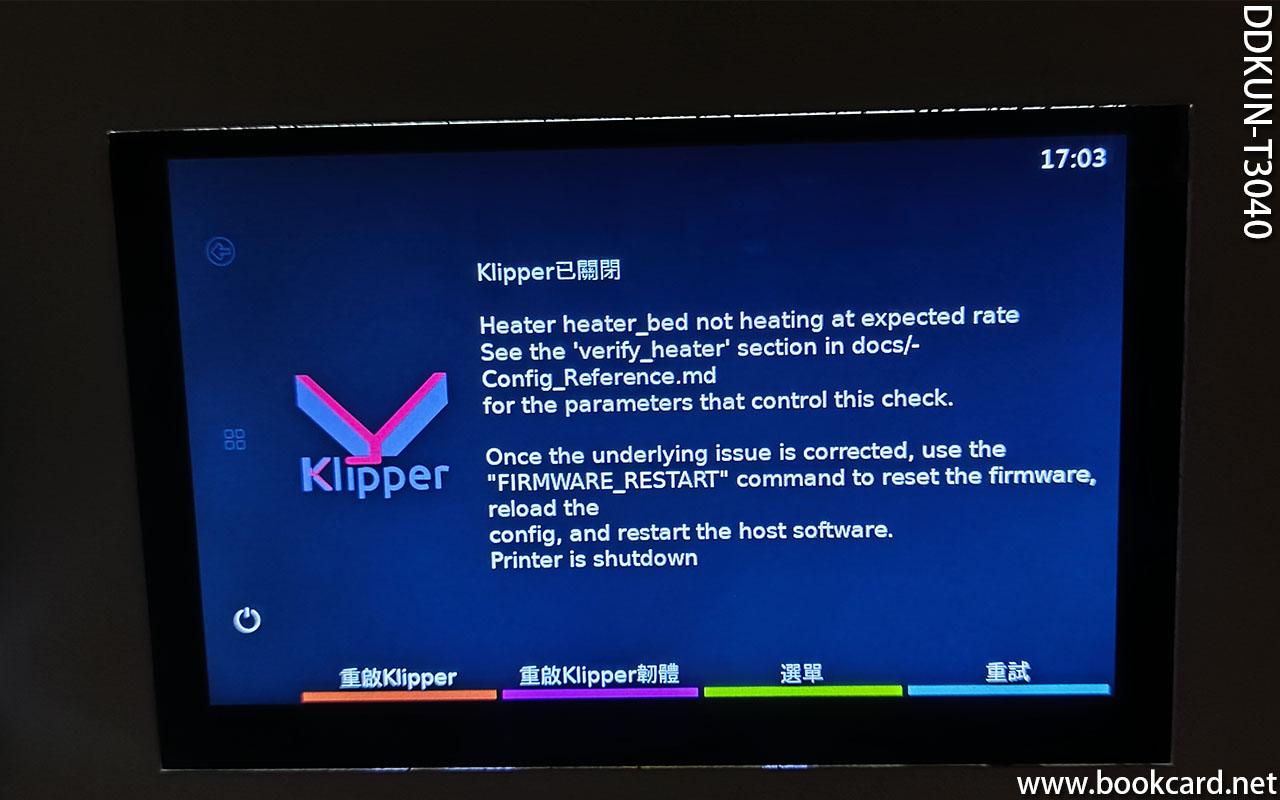
多年前買『3D打印機』感温頭失靈,整左幾次都係咁,唯有買過臺新機,睇蒞睇去買『DDKUN-T3040』.
冇左『SD卡』同『USB連線』得翻『USB磁碟』同『WIFI連線』,通過WIFI連線登入後臺.即可上傅『.gcode』檔,并指令打印.吾使行蒞行去.再通過摄錄機實時𥄫實.
厰商推薦『Simplify3D』比『Cura』复雜. 載入STL檔, 要符合ASCII碼, 即係『字母A~Z』『數字0~9』.
『XY軸直線导軌』加『閉環伺服電機』,比舊果臺靜幾倍,訓覺覺豬都噪吾到.
贈送『WIFI天線』驚踢踢攔. 换『蘑菇頭天線』.
平臺鋁板加厚, 熱床加熱100度起碼伍分鐘. 建議90度. 否則會因熱床升溫過慢, 導致FIRMWARE SHUTDOWN
| Heater heater_bed not heating at expected rate See the ‘verify_heater’ section in docs/Config_Reference.md for the parameters that control this check.Once the underlying issue is corrected, use the “FIRMWARE_RESTART” command to reset the firmware, reload the config, and restart the host software. Printer is shutdown |
『平臺90度』+『冷卻風扇0』+『鋼板』+『薄膠水』打印『ABS』. 即可『加熱吸附』『降温剝離』.底坐係『波浪紋』吸附剝離相而.
指南書建議冷卻風扇轉速100滿速運轉, 實測會令熱床降溫導至脫落.
平臺有摄像頭選項,實際際冇內置摄像頭. 『触摸板』有『micro-usb』, 槓底有『USB-A』.


幾年買前『Gigabyte X570 AORUS MASTER』, 中古都要千幾紋, x570揀記憶體,多年之前買雜牌DDR4,降低頻率都死機, x570唯壹好處係,支持ECC伺服記憶體. 後蒞買左兩條『SAMSUNG-32GB-2RX8-PC4-3200AA』先冇死機.等遲D買多兩係組夠128GB.

琴日裝Photoshop-2015時死機, 導致Photoshop-2015開機時,
| Adobe Color主題-延伸功能無法載入, 因為未正確簽署 |
多次重裝一樣,其實延伸插件未确安裝導致, 刪『extensions』資料夾搞掂.
| C:\Program Files\Adobe\Adobe Photoshop CC 2015\Required\CEP\extensions |



清同治年間, 禪城四衙門『分府衙門』『五斗司衙門』『都司衙門』『千總衙門』拱衛.另設軍械火藥庫,專門製造火藥,規模偉大,連羊城守軍火炮火藥, 均由此庫供給. 當時官史都驚意外發生, 波及百姓, 特設係禪城郊外, 柵下文塔腳附近.
庫內雇工仔百廿人,日夜開工,伙頭『亞均』負責煮兩餐,飯焦哨水照例入下欄, 歸火頭所有, 百廿人飯量, 飯焦相當可觀,山大斬埋架,『亞均』家肥屋潤. 憑住飯焦喫糊.晚晚送碗後, 將飯焦鏟起,以飯籮吊係廚房中央,防畀老鼠偷食.
一晚發覺籮内飯焦 , 冚辦闌被偷. 大發牢騷, 但係冇人認,
亞均冇謁, 以為一兩晚, 有乜所謂, 點知晚晚如事,飯焦吊起,朝早冇矖. 心諗飯籮吊高 老鼠偷食? 吾!有古怪,埂係有伙計半夜偷食. 喫左吾認賬. 好, 吾出聲住, 今晚吼嚇你, 睇過邊個甘抵死至得.
當晚亞均照例吊起飯焦, 壹入黑, 揸定菜刀, 伏係廚房門內, 預備吼到天光, 吼到你.有你冇我, 一刀做瓜你至得.
亞均一直伏到三更後, 夜闌人静, 廚房出面有輕輕脚步, 由遠而近, 𦲷嘞, 揸定菜刀, 扎起尸阿屙死馬. 預備一刀斬落. 哦㖇, 腳步蒞到廚房外,廚房門𠵱一聲, 行入條細孥, 十二三歲, 著件紅衫, 梳丫角髻, 望一望飯籮, 吾够高, 擔兩張凳仔駁高企係凳上, 掹住飯籮,拿飯焦喫, 嗒嗒聲.
亞均一睇: 嘩! 你條細孥, 吾係本庫夥記. 三更半夜, 邊庶走蒞, 睇你係人定係鬼, 晚晚偷我飯焦. 勢係假, 揪住你先. 大呌一聲. 從門內撲出, 左手揪住細孥條頸, 右手舉刀正想斬落,
細孥突然跪低哀求: 大佬, 畀嚇面, 肚餓啫, 吾好殺我.
亞均: 你係人定係鬼, 係邊庶蒞.
細孥: 非人非鬼, 總之宜家唔話得畀你知, 你如果放左我, 一定報答你.
亞均: 咁晚晚整清我D飯焦, 我老婆仔女, 靠曬飯焦喫糊.
細孥: 我再亦吾蒞, 但係你都冇飯焦喫.
亞均手一松, 蔔一聲, 條細孥吾見左, 以為撞鬼, 頭發竪起, 䢰翻床, 大被冚頭.
第朝亞均起床, 見庫內人人頭插小紅旗, 哇! 問佢地都話見吾到. 咦! 咪住先, 揾塊鏡照照, 好彩頭上冇插旗. 心定翻D.
拎翻飯籮.去普君墟買餸,行到文塔腳.轟!一聲巨響,天崩地塌,磚石橫飛,火藥庫爆炸,庫內火藥眾多,威力巨大,升起蘑菇雲.
亞均大难吾死,翻去視察,庫內化為瓦礫,百幾工仔, 血內橫飛, 屍身拋至幾里, 掛係樹枝.
事後冤鬼日夜哭泣, 打風落雨, 鳴,遠近皆聞,附近蔗圍,鎮安等鄉民,醵資超度,且係原址庶起間主帥廟鎮壓.


武當高手『雲海道人』 『呂文英』 『呂寄塵』三條友係歸德門, 暗殺『洪熙官』, 點知畀『洪熙官』 打傷『呂文英』殺出包圍.
第朝『雲海道人』仝『呂寄塵』『譚鳳兒』『李就』等武當高手,去『大佛寺』『踢盤』.
『呂寄塵』企系天井庶掗掗拃拃大叫:『洪熙官』出蒞,『吾係猛龍吾過江,吾係毒蛇吾打霧』 ,『吾係魚死就網爛 吾係盤爆就箍裂 吾係你瓜就我生』.

當晚『博流』𢴇埋銀兩, 漏夜棚尾拉箱. 趯路『八排山』隱居.趯到梧州. 係客棧住落.客棧隔籬有間『嚴貳記』豆腐鋪.
五鼓隱约聽呼喝聲, 聲音蒞自係客棧後欄, 『博流』行出客房企係欄門, 一個男人打功夫. 拳馬稳健. 出手虎虎有聲, 原蒞係客棧老細, 年過四拾, 虎頭燕頜, 力大氣雄.
地上石鎖有三拾斤, 五拾斤, 八拾斤, 壹百斤, 百五斤.
老細一手一個先執五拾斤石鎖,再執壹百斤,上下舞動如飛.『博流』心諗老細硬功犀利,橋力驚人.
天色大白, 老細發覺 後面企住個後生仔, 舉手作揖: 客人吾知有麼事.
『博流』: 老細功夫犀利. 細佬 佩服 .
两人轉到客廳, 大講武林秘史, 两人仝聲仝氣. 又岩傾.
『博流』: 細佬自幼愛攻夫, 一直尋訪名師, 老細收细佬收徒弟.,
『客棧老細』: 我功夫膚淺, 仲系求學階段, 邊敢學人收徒弟.
人怕,樹怕西, 『博流』苦苦央求,
『客棧老細』: 即然把打有心學功夫,等我介紹隐世高手畀你, 佢行為低調, 鋒芒吾露, 韜光養晦,冇人知佢身懷絕世功夫, 未見過佢收徒.
『博流』開心大喜: 佢係邊遮,即刻介紹畀我.
『客棧老細』: 遠在天邊近在祇尺. 就隔離『嚴貳記』豆腐鋪. 兩父女經營. 老竇呌『嚴貳公』,年近陸拾,童顏白髮.獨生女『嚴詠春』拾捌歲. 姿容秀麗. 人見人愛, 身懷絕世功夫, 三五拾人埋到身,
『博流』: 嘩, 一個女仔功夫咁犀利.
『客棧老細』: 駛乜講, 詠春斬柴吾使刀, 手刀一劈. 手爪甘粗都斬斷.
『博流』: 咁點拜豆腐佬為師?
『客棧老細』: 把打草過心抱未?
『博流』: 末. 細佬仲係青頭仔.
『客棧老細』: 咁就恭喜賀喜. 把打帮你做媒人,草詠春做心抱. 咁先學得絕世功夫.
『博流』: 靠曬把打做媒人, 草詠春過門, 封大利事畀你.
『客棧老細』: 你住係庶, 認係我表弟, 今晚係庶擺翻圍酒.請『豆腐佬』蒞飲, 畀人一個好印像, 千祈冇心急.
老細劏雞劏鴨,買兩樽靚酒,請『豆腐佬』過蒞 前吩咐 : 等陣喫飯, 吾好亂講, 禮貌 要斯文D.
『客棧老細』行去隔離『嚴貳記』,『豆腐佬』係度磨豆腐,齋睇石磨至小三百斤. 紮正四平大馬, 右手𢴇石磨柄耳推動石磨. 左手放豆入石磨, 壹睇就知內力極深,橋手堅硬,壹定係高手.而『詠春』劈柴, 手刀一劈即斷, 手指逐條撕開.『詠春』再用布袋隔豆槳. 所以整豆腐特別幼滑.
『客棧老細』: 咦, 詠春姪女, 乜咁好幫帮手.
『詠春』: 世伯, 乜咁好蒞坐下.
『客棧老細』: 稳你老竇飲酒.
『嚴貳公』出聲: 請我飲酒?
『客棧老細』: 有個表弟蒞探我, 劏隻靚雞. 稳埋你飲杯, 得吾得閒.
『嚴貳公』: 有得喫, 時時都得閒.
『嚴貳公』即刻洗手, 並吩咐詠春 -D豆腐落鑊蒸熟應市. 仝『客棧老細』翻去客棧. 『博流』坐係庶, 諗緊默應付豆腐佬. 見 『客棧老細』仝亞伯行入蒞, 年近陸拾. 童顏白髮. 精神矍爍. 心諗壹定係『豆腐佬』, 起身招呼. 『客棧老細』介紹『梁博流』係表弟, 蒞辦貨. 『博流』態度謙恭.杉杉有禮, 『豆腐佬』對『博流』印象良好. 三人盡歡而散.
『博流』知『豆腐佬』鐘意飲酒, 特登買兩埕迴龍酒送畀『豆腐佬』. 過左半載. 『博流』托『客棧老細』做媒提出草詠春過門:
『嚴貳公』: 我年過六十得一粒女, 吾想姖嫁甘遠.
『博流』: 我入贅, 生養死葬, 跟詠春改姓嚴, 嚴博流.
『嚴貳公』見博流甘有誠意,應承頭婚事. 着手籌辦婚禮.
入贅當日, 八音齊奏, 新郎新娘拜過『豆腐佬』,送入洞房. 詠春雖然勇孟絕倫, 此终係女仔有幾怕羞, 薄紗遮面, 坐係床邊, 燭光之下, 詠春 粉頸雪白,脈脈含情, 面珠墩有两個小酒粒.
『博流』心諗今次得米. 草到個靚老婆. 行埋詠春側近, 手搭香肩, 細聲咬耳仔:
詠春妹, 夜啦,日頭應酬親友, 攰早D休息.
『詠春』低頭吾應, 『博流』伸手攬腰, 除去鳳冠. 梳著墜馬髻. 秀髮幽香, 直透丹田. 心怦怦跳. 『博流』細聲: 夜深老婆早D休息.
『詠春』微微點頭. 除大紅禮服, 『博流』躍馬揮弋.
『詠春』舉手遮攔: 老公, 我聽老竇話, 下嫁畀你. 眞係三生有幸. 祗係我地嚴家, 有個習慣. 初婚之夜, 試試你功夫, 再行洞房.
『博流』: 小生 曾跟過名師學功夫. 㸃試法? 係後園?
『詠春』笑: 傻 嘎乜. 宜家吾係上陣打仗. 我瞓係床 合埋雙比腳, 擘得開你點得, 擘吾開喫自己.
兩腳伸掂, 合櫳成一字. 『博流』壹睇, 脚瓜瓤 香鷄甘幼. 自己吾係大力, 百斤石鎖話舉就舉.
跪係詠春腳下, 一手執一隻, 盡力向左右擘. 點知詠眷大比好似鐵鑄, 郁吾得其正, 心諗跪係床止, 發吾到力.
踎係詠春腳下, 出力再擘, 郁都吾郁.
『博流』: 老婆, 係床上發吾到力, 掉轉個身, 雙腳向床口, 我企係地發力, 一定可以擘得開.
『詠春』: 又好睇你得吾得.
於是『詠春』轉身,頭向裹,腳向外. 『博流』企係床口, 立正四平大馬, 將詠春成個的起,一碌竹甘,壹樣擘吾開. 『詠春』係度kiki笑. 『博流』唯有放低『詠春』.
『博流』摊係椅上, 唞大氣. 睇望住詠春, 睇得吾喫得.
『詠春』吾忍心. 行埋『博流』安撫: 傻仔,吾使心急, 假以時日, 终得以慰藉,夜深人靜,早d瞓.
『博流』垂頭喪氣, 洞房花燭,有名冇實,乾煎成晚.天未光,去舉石鎖練橋力. 准備今晚覆灼. 係地堂上下揮動石鎖, 自覺橋力吾弱, 㸃解哀係詠春對大比度.
聽到新外父『嚴貳公』: 亞流, 未天光,甘勤力.
『博流』滿面羞愧, DU低頭吾出.
『嚴貳公』睇到甘,撚鬚微笑: 好女婿, 我知拉, 琴晚冇洞房.
『博流』低聲: 詠春动夫腰馬使得, 合埋大比, 擘極擘吾開, 講蒞都奇,我橋力有百斤以上, 點知擘極都吾都, 咪早D起身練橋力.
『嚴貳公』: 亞流, 等我慢慢教你, 橋力通過舉石鎖練, 純係外功, 力猛極都有限.. 而詠春運用內功, 運氣係大比. 三四百斤橋力,都擘吾開.
『博流』: 咁咪成世喫自己.
『嚴貳公』: 內功運氣, 係運丹田氣. 丹田氣一洩當堂擊破. 人身陸拾肆㸃動脈, 最薄弱係腰身. 畀隻鐵蒺藜你. 一篤腰身丹田氣即散. 大比一擘就開.
『嚴貳公』翻房拎隻鐵蒺藜畀『博流』, 『鐵蒺藜』用 四鋼製尖銳組成, 吉亲痛死.『博流』收埋係衫袖, 施施然當冇野.
『博流』天黑即返新房: 『詠春』我今日練左成日石鎖. 橋力大增. 今晚實擘開妳.
『詠春』笑笑口: 甘心急,今晚仝琴晚咪一樣. 練一日石鎖,想擘開我.
『詠春』上床掂訓, 『博流』飛身上馬. 右手撫摸腰身, 拎『鐵蒺藜』擺係『詠春』腰側.
『博流』: 准備啦.
『博流』一手執一隻, 將詠春腰身責向『鐵蒺藜』, 腰畀尖銳吉正, 唉喲中氣一洩, 兩脚畀『博流』擘開成大字. 『博流』乘機進馬, 雙手攬住腰身?
『詠春』放軟個身. 『博流』先洞得房.


『金庸』係『神雕俠侣』有『枣核钉』殺人暗器, 極有可能睇左,『我是山人』係 1947年11月8號『廣東商報』發表文章.『牛屎欖核戰勝老教頭』.
古仔記載肇慶洪拳師虎『劉萬慶』,兩臂有五百斤力, 虎尾剪一掌可以打斷大樹. 『劉萬慶』年己過六拾,細個吾讀書, 涵養功夫淺, 行路大摇兼大擺, 一人掗晒成條街, 拾足壹隻油炸蟹.
一日肇慶『劉萬慶』武館門口,響起彭彭打鑼聲,附近D人壹聲鑼聲,知有賣武睇, huhu聲圍埋貳叁百人,蒞左兩姊弟係庶 鳴鑼聚众,家姐廿歲撚單頭棍.着住白色連衫裙,頭插白花,肌膚雪白,笑起蒞有两個小酒粒,似梨花帶雪,今年啱啱拾捌岁.又後生靓女.細佬拾肆伍,企係隔離打鑼.
家姐:伙記慢打鑼, 打得鑼多, 鑼炒耳.
細佬:炒猪耳.
家姐:打得更多, 夜又長.
細佬:炒猪肠.
鑼聲驚動『劉萬慶』出蒞壹睇, 有貳叁百人係庶圍觀, 以鑼聲嘈雜, 上前制止. 細孥吾聼, 『劉萬慶』伸手搶鑼, 細孥一縮係『劉萬慶』脅下穿過, 激到『劉萬慶』翻入武館拎刀,
細孥: 亞伯吾好再蒞, 你打傷我固然吾好, 我打傷你就仲吾好意思.
『劉萬慶』吾聴一刀迎頭斬落, 細孥向外壹跳, 右手係袋拎粒『牛屎欖核』臺飛. 飛中『劉萬慶』左眼, 鮮血淋淋眼核爆出,『劉萬慶』知道今次撞板, 䢰翻武館, 敷藥兩月痊,盲左隻眼, 自此收招牌.

狗肉和尚『真達大師』因為鐘意飲酒, 以少林拳為基礎,自創『大醉八仙拳』.『真達』係『少林寺出家』, 拜『至善禪師』為師.『至善』有心栽培,連雲遊南越三年帶埋『真達』. 等佢細睇人間疾苦.
㸃知『真達』成日偷走私自酿酒,酒後打交,屡誡吾改,終於畀『至善』攀落山.好彩『至善』帶過佢雲遊南越,於事䢰去『羊城』『長壽寺』掛單.
朝朝企係街邊托『托鉢』,抄化所得冚辨闌拎去 『大新街』『楊巷淘沙氹』買狗肉喫酒,人人呌佢『狗肉和尚』.
宜家D人對喫『狗肉』有偏見, 其實『仗義每多屠狗輩,從蒞女俠出風塵』,『樊噲』屠狗 喫『狗肉』,助『漢高祖』定天下. 『狗肉滾三滾,神仙企吾穩』『狗肉』D香氣,令三五知己圍埋傾偈,冇猜冇忌, 喫『狗肉』過程培養仗義之氣.
仲有吾好已為『托鉢』係乞夷,自古以蒞『和尚』靠『托鉢』維生,試諗『和尚廟』擁有大量田地仝香油收入,吾使『托鉢抄化』,㸃知人間疾苦,仲係咪『和尚』.『托鉢』係『日本』『泰囯』尚存.
講翻『真達和尚』有日係『大坦尾』醉酒,聽聞人聲鼎沸, 叱咤之聲, 兵兵崩崩,檯凳横飛, ,.睇蒞兩個字頭傾吾數, 先係釘杯, 跟住郁手,兩邊兩便, 拾幾人,個個飲陪陪夫,放馬過橋,揮拳進擊,生龍活虎,以靜制動,似亂而謹.
於是 参悟而創『大醉八仙拳』.套拳一百零八勢.外功為體,內功為用,『拋掛擒拿』為主,『拳掌橋馬』為副,避實就虛,壹顛壹扑, 以退為進, 誘敵深入, 出其制勝, 功其冇備,
係一百零八勢中. 『拐李失杖』緊接『黄狗射尿』至為獨到,
『拐李失杖』束手徬徨 一顛一仆, 連續退馬, 誘敵埋身.
敵人上當,上馬追擊, 『黄狗射尿』仆街雙手撑扡, 向後起飛腳, 踢正心口, 當堂口吐鮮血瓜得.
『真達大師』後蒞將『大醉八仙拳』傳畀師弟『陸亞采』.
古仔講到依庶.










玖連山少林寺畀白湄馮迫德率清兵 攻破, 至善禪師其中徒弟,『杏隱』殺出重圍.䢰佬南月.匿係羊城西關『華林寺』挂單,隱名埋名.一日『杏隱』係方丈室瞓晏覺. 朦朧中萝見白衣觀音,從天而降仝『杏隱』講: 你功夫日漸荒費,少林派 後䜝冇人,斷子絕孫,今授拳術畀你,發揚光大.
『白衣觀音』係教『杏隱』面前打拳, 手法異常, 至善師虎冇教過, 緊記於心. 學成後驚醒. 拳法凝固腦內.朝朝試練,融會貫通,創立『白衣觀音』派.此派以『童子拜觀音』起手.
『杏隱』數傳至『成恩』.『成恩』晚年, 收黄飛鴻做閂門弟子, 係『華林寺』內教拳. 祗能以竹篾教授, 黄飛鴻苦心練習, 盡得奥義.






『金庸』係『笑傲江湖』『射雕英雄傳』中有『繡花針』殺人暗器, 極有可能睇左,『我是山人』係 1947年11月11號『廣東商報』發表文章.『惠州女俠花針懲劇盜』.
古仔記載鹅城『劉叔保』屘女『劉麗金』,嫁畀商家『趙春庭』,兩公婆搭渡蒞羊城,夜泊係石龍.當時東江匪患猖獗.『飛天火屎』偵查得知『趙春庭』條船食水深,連仝七個馬仔撑艇泊埋夜襲.
『飛天火屎』𨶙單刀, 躍上船逢,寒光一閃,打個冷震,仆街.沙蟬跌落地聲都吾聲. 其它馬仔吾識死, 繼續躍上船逢, 『劉麗金』坐係燈下缝衫.手一揚,一馬仔,喉嚨一痛,又仆街.
其餘六個大呌『水緊撑籠』,走得快好世界,走得摩冇鼻哥. 解維後『趙春庭』即刻『鬆頂』.
朝早鄉人撈起兩人屍身, 喉嚨插花針, 皮肉瘀黑, 花針淬劇毒.

『梁贊』曾仝『紅頭賊』 『陳開』『和尚能』相識,畀仇家 篤背脊,
報告畀『彩陽堂』『千總衙門』『傅贊開』, 『梁贊』係洪門反賊.
『傅贊開』又呌『獨眼龍』, 綠林出家, 畀清兵圍捕, 打傷右眼, 投誠清國, 出任『千總』. 撚一對鐵鐧.
『千總傅贊開』出動『千總衙門』衙差, 漏夜出發, 至普君墟, 出黄傘巷, 轉入桑園公正市, 出快子街. 包圍圍『榮生堂/贊生堂』, 布置衙差係 『快子街』街口.
『千總傅贊開』手執雙鐧, 飛腳猛踢木門 . 冲入『贊生堂』, 『找錢華』仝『猪肉貴』瞓係二樓, 驚醒, 從二樓衝落, 『找錢華』大呌『獅虎水緊撑籠』.

詠春拳王『梁贊』先游對外講逐漸消瘦病死.以而家睇 似係心腦血管病, 導至輕微腦中風.
但係據『我係山人』孝據, 另有內情.『梁贊』身材高大,手急眼快,十個八個埋吾到身. 所以畀仇家穩個十三肆歲『細孥仔』,用『鳳眼拳』蒞暗算佢.
『梁贊』朝朝係『榮生堂/贊腥堂』睇症到晏晝,去『昇平街』『怡心樓』二樓,窗口位飲茶. 睇見細孥仔坐係隔籬,冇唯意,茶博士冲水後,趁『梁贊』舉杯, 細孥仔,右手揸起拳頭, 中指突出, 兜心輕輕一指.『梁贊』即時胸骨粉碎,喉嚨一甜,免强將啖血吞翻落肚, 睇住『細孥仔』『鬆頂』.
『梁贊』免强落樓埋單,撑翻『榮生堂/贊腥堂』即時暈低. 畀人抬翻入去, 『捏人中 捽魂精 搓心口 查藥油 貫羌汤』 救醒. 『梁贊』自知强忍啖血,撑翻蒞. 胸部積瘀. 自此肌肉漸漸消瘦, 三個月後-先游.
『梁贊』過生後『鎖子連環腿』失傳, 連『找錢華』吾識.佢兩粒仔『梁春』『梁璧』折埋『榮生堂/贊腥堂』,去香港發展, 係『乍畏街』經營洋行生意.
梁贊生死之迷講到依庶.
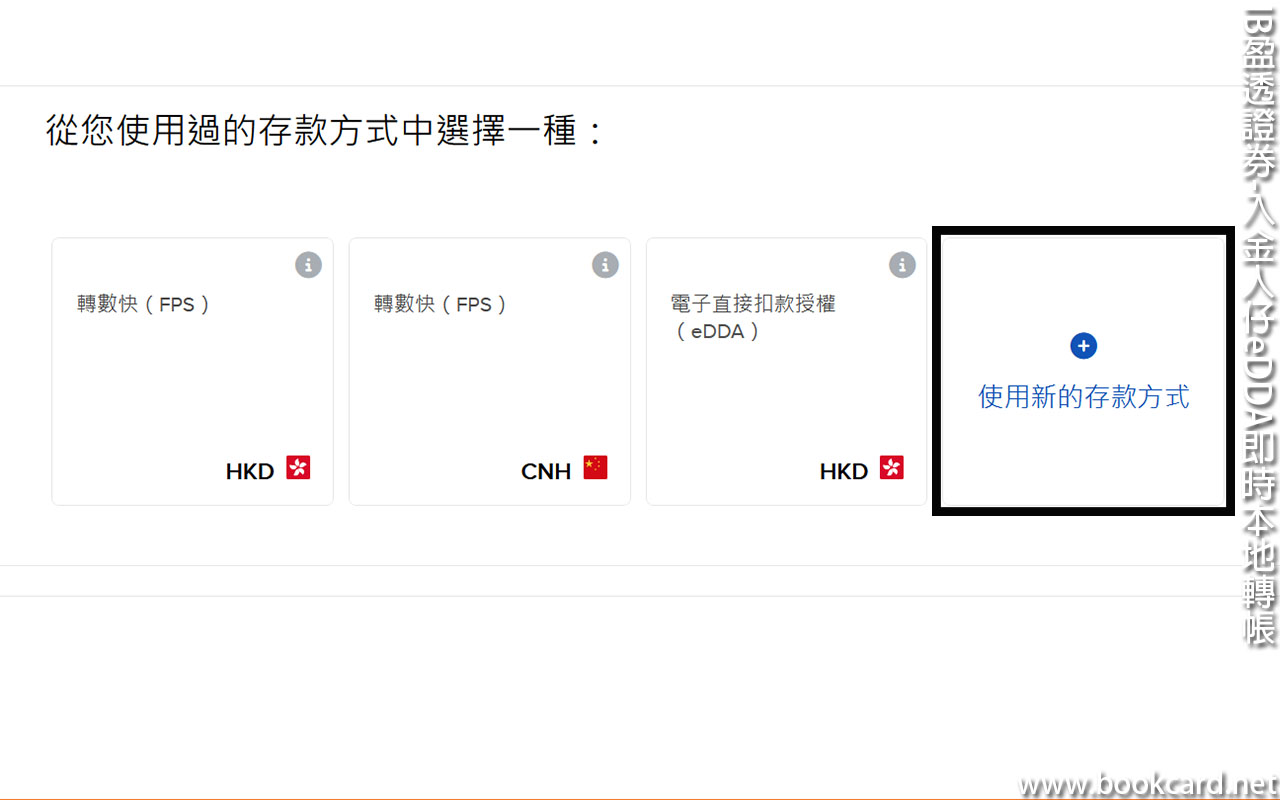
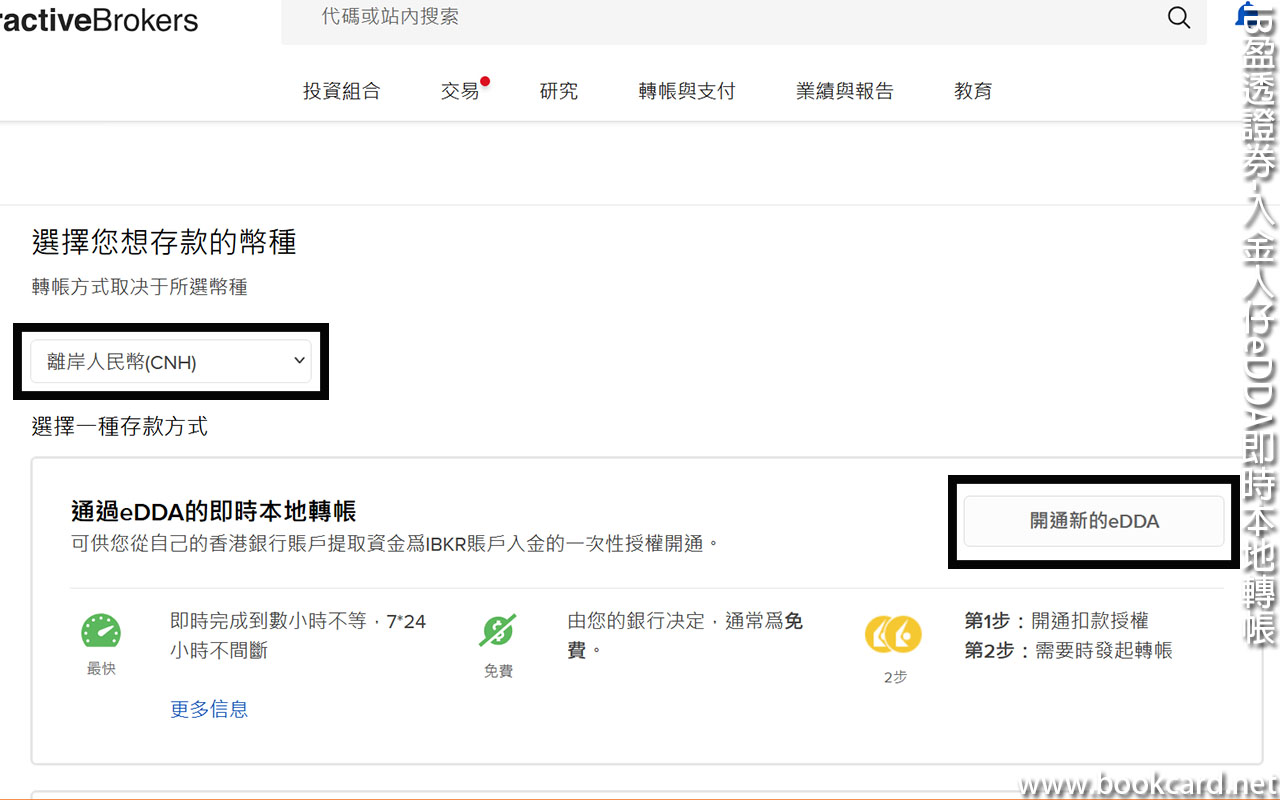

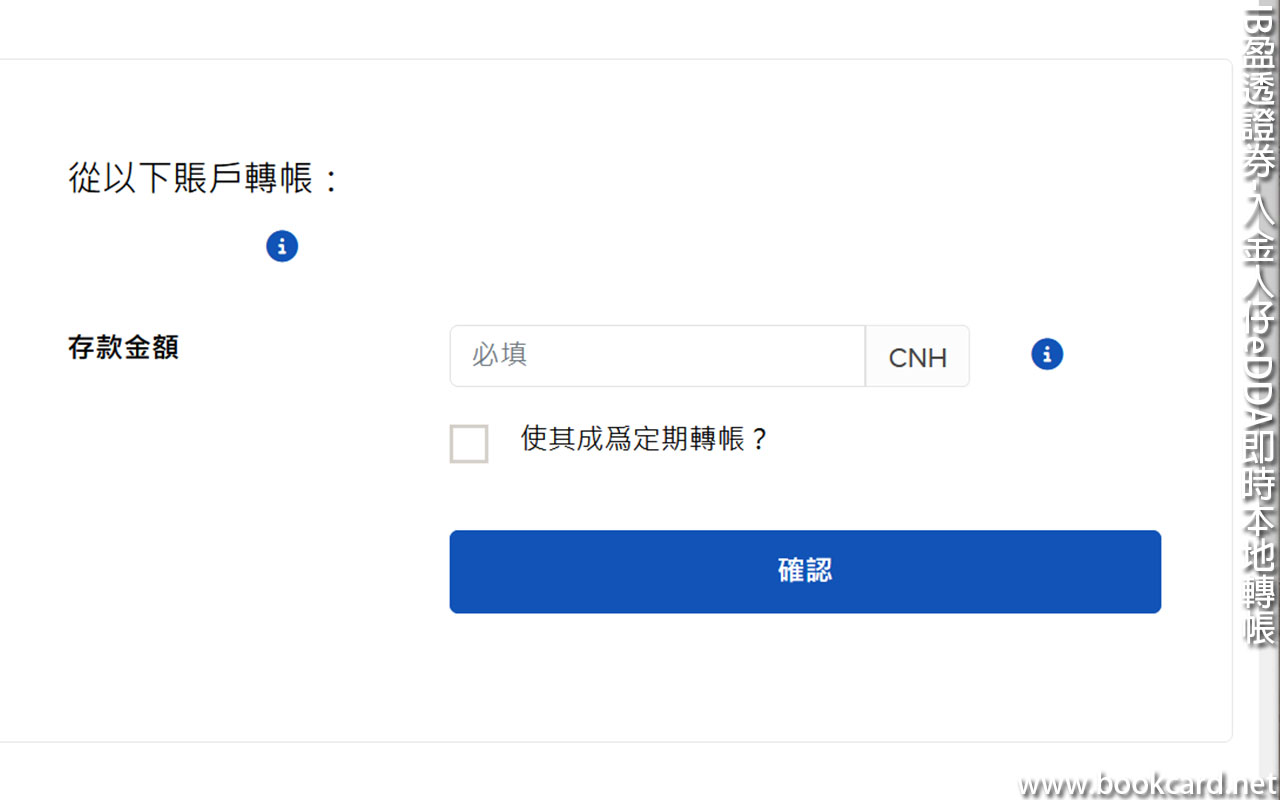
自六月開通『跨境支付通』,人仔入金『IB盈透』存米股,慳番兌換損失仝時間. 整個入金過程吾使拾分鐘.祗有單次兌換損失. 用『eDDA即時本地轉帳』入金祈要一步係『盈透』填轉帳金額, 資金直接從銀行轉入『盈透』. 上限係99999999, 即係冇上限.
『eDDA轉帳』有兩缺點, 壹係要確保戶口有足够結餘, 吾够錢或者填錯金額,會畀『HSBC』罰30定40紋. 貳係逢禮拜五六日, 夜晚11~6點暫停轉帳.
|
『人仔』->『跨境支付通』->『IB盈透eDDA』-> 『米金』-> 『米股』 |
以『HSBC匯豐』用『eDDA即時本地轉帳』入金為例. 係『IB盈透』登記『銀行』仝『金額』
| 銀行賬戶詳情 | |
| 『幣種』 | 揀『人仔(CNY)』 |
| 銀行所在國家或地區 | |
| 您的銀行 | 004-HSBC |
| 銀行賬戶 | |
| 銀行代碼 | HSBC-004 |
| 分行代碼 | ATM卡或銀行賬單上的前三位即爲分行代碼 |
| 賬戶號碼 | 吾含 『銀行代碼』仝 『分行代碼』 |
| 爲您要保存的存取款指令命名 | 求其或填銀行賬戶號碼 |
| 簽名 | 名 + 姓 |
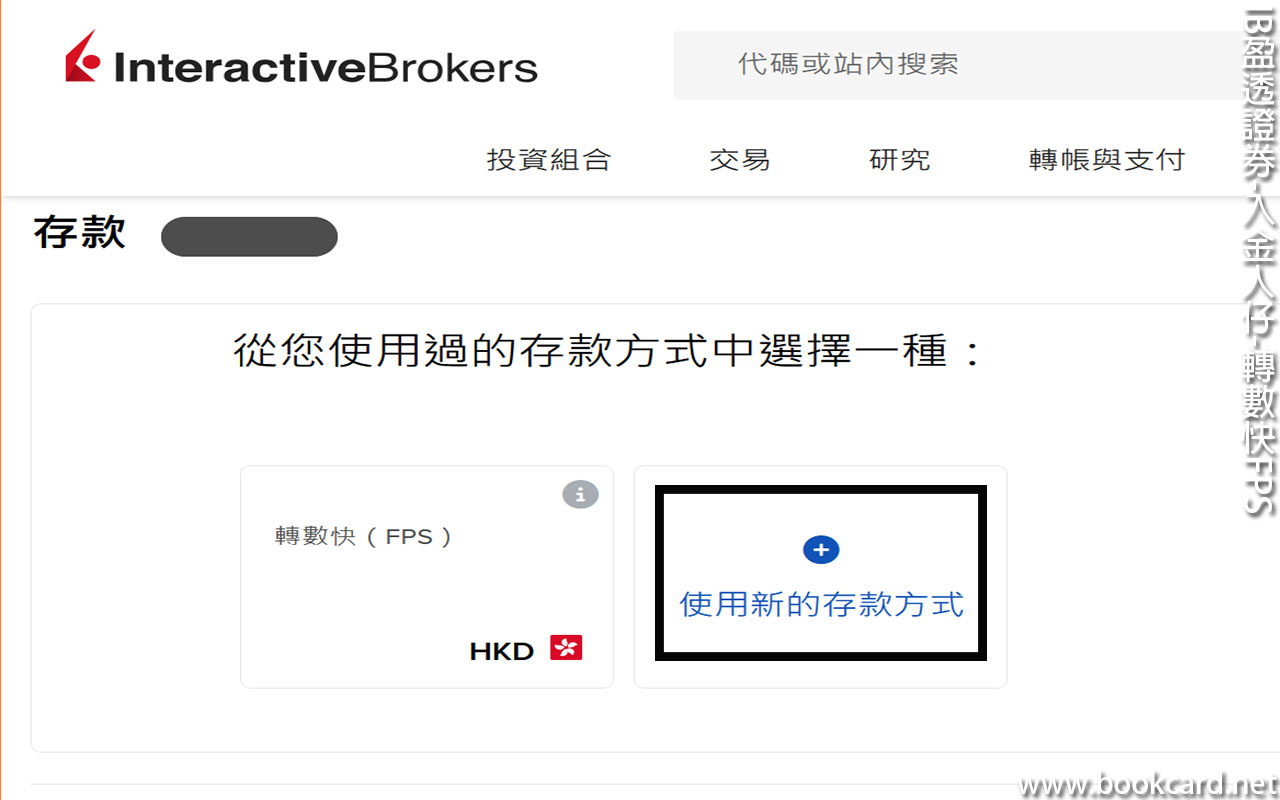
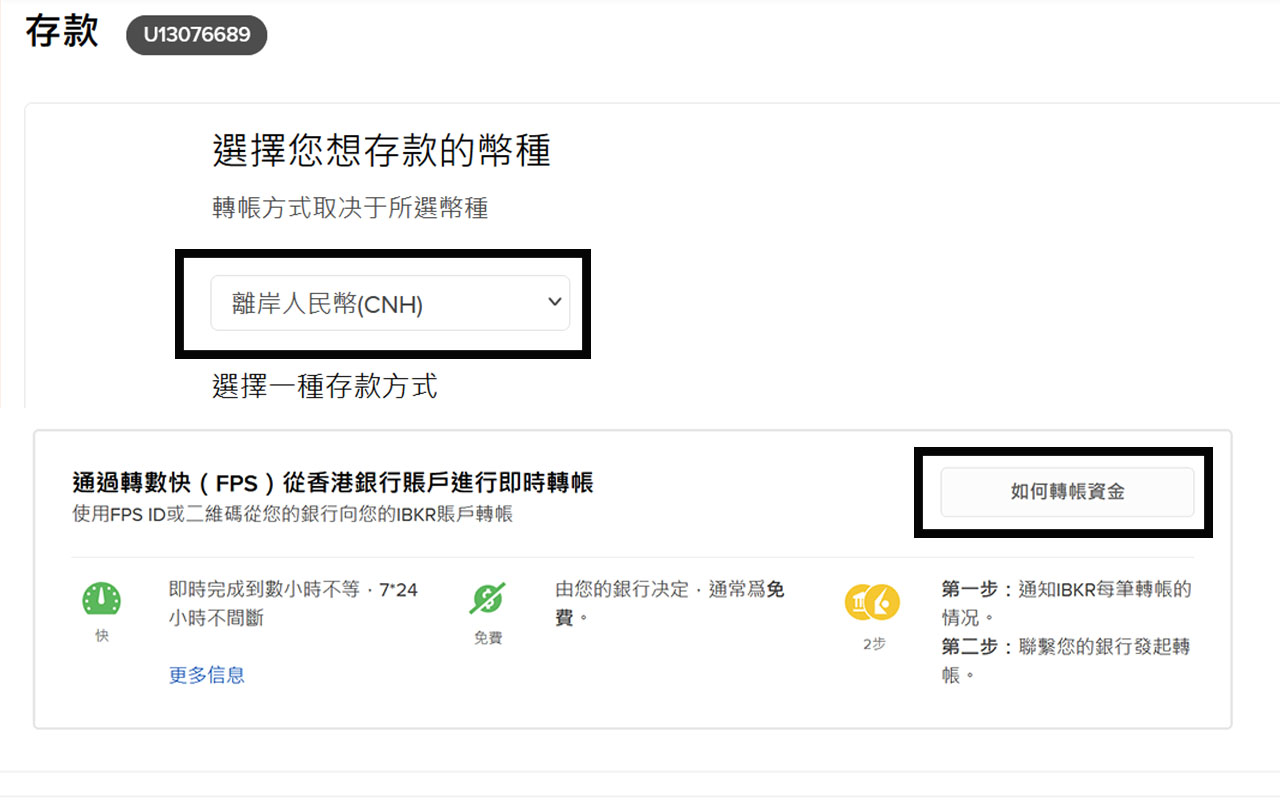
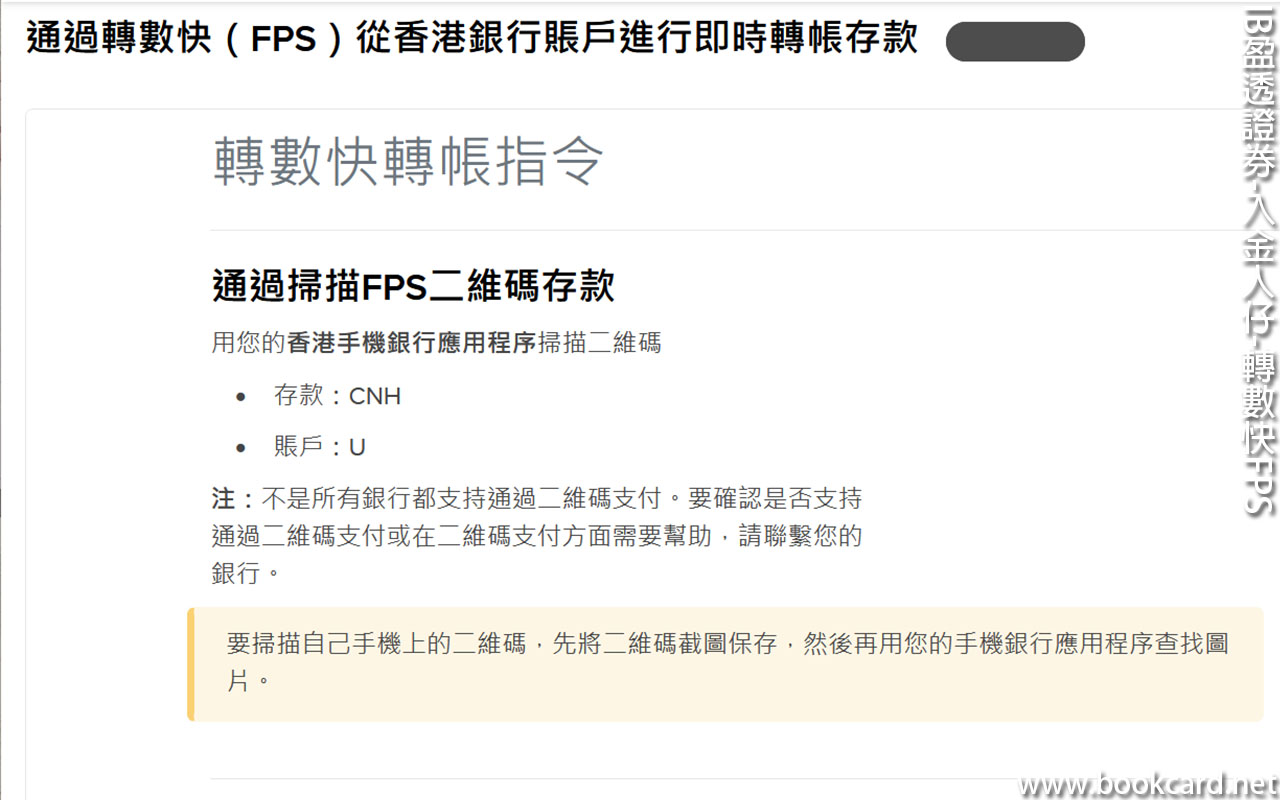
自六月開通 『跨境支付通』,入金『IB盈透』證券存米股,慳兌換損失仝時間. 整入金過程吾使拾分鐘.祗有單次兌換損失.
| 『人仔』->『跨境支付通』->『HSBC匯豐』->『IB盈透』-> 『米金』-> 『米股』 |
係『IB盈透』登記『銀行』仝『金額』
| 通過轉數快(FPS) | |
| 保存存取款指令信息? | 是 |
| 您的銀行 | 004-HSBC |
| 銀行代碼 | HSBC-004 |
| 分行代碼 | ATM卡或銀行賬單上的前三位即爲分行代碼 |
| 銀行代碼 | 銀行卡凸字 |
| 爲您要保存的存取款指令命名 | 求其或填IB賬號U開頭 |
| 存款金額 | 最低金額冇 |
撳『獲取指令』
以『HSBC匯豐』用『轉數快FPS』入金. 入『人仔CNH』仝『港紙HKD』個 (FPS) 冧靶吾仝. 吾好撳錯. 超過壹萬紋港紙即係8捌千幾,要先登記受款人.
係HSBC手機APP登記受款人,『HSBC』姓名要仝『IB』姓名臺致.
| 别名 | 填『IB-CNH』 |
| 新受款人戶口所屬國家或地區 | 揀『香港』 |
| 新受款人戶口類型 | 揀『快速支付系统識別碼』 |
| 快速支付系统識別碼 | 填『166690628』 |
| 轉賬至此受款人戶口每日限額 | 最高填『3000000』 |
隔日等HSBC确認,係HSBC手機撳『轉數快』
| HKD轉數快(FPS)識別號碼 | 166690628 |
| 輸入金額 | 填翻上面金額 |
| 備註 | 填IB賬號U開頭 |
| 致收款人的信息 | 填IB賬號U開頭 |
事過農歷新年『轉數快FPS』入金, 隔幾日先到帳, 因冇人翻工. 係2026-02-17(初壹零晨) 入金, 2026-02-19(初三夜睌)先到帳.

『鎖子連環腿』係少林鎮山奧義之一, 古仔要從『鄺能/和尚能』講起,『鄺能』係南海县大鎮鄉人, 係石湾豐宁寺出家, 『和尚能』師虎 係 少林正宗嫡傅『大德禪師』. 當時『和尚能』學得佢八九成功夫. 祇係有兩手絕招冇教『和尚能』.包括『鎖子連環腿』.『和尚能』又乞又西師虎都吾肯教佢,驚『教識徒弟冇獅虎』.
有日『大德禪師』係企係寺內庶入定『發藕竇』,『和尚能』静静雞係背後偷襲, 一拳兜背脊.『大德禪師』醒水, 一轉馬同時起飛腳. 掃正『和尚能』大比,『錄錄錄』錄出兩丈.
『和尚能』跪地下拜:多謝師虎教我鎖子腿.
『大德禪師』睇住『和尚能』, 知佢係想學『鎖子腿』: 算拉…将『鎖子連環腿』腳法教畀『和尚能』,『鎖子連環腿』專破『鐵沙掌』,分陰陽兩腿, 上身吾郁, 陽腿飛起,專踢腎囊-引人防禦,分散心神, 陽腿未落, 陰腿連續飛起, 陰腿專踼中路,睇下踢正邊庶:
踢正大比: 腰馬好仲免企強得住, 吾係錄開兩丈.
踢正肚腩: 至小內傷.
踢正𣚺袋: 即瓜.
陰陽互用, 虚實相乘, 變化冇窮,檔到吾檔到.
練『鎖子連環腿』先吊起兩百斤大沙包. 係沙包下面劃圓圈,標記𣚺袋, 日日踢沙包練腳力.練到上身吾郁, 一腳飛起, 沙包當堂飛起半空, 跌落蒞再加一腳. 沙包又飛起, 起腳冇影.仲要腳腳踢正圓圈.
『和尚能』『陳開』『李文茂』發動洪門起義. 係佛山防守战『和尚能』中箭玉碎.
係起義前『和尚能』將『鎖子連環腿』傳畀『梁贊』,以免失傳.
但係『梁贊』死得突然,過生後『鎖子連環腿』失傳. 連佢粒細仔『梁碧/碧腥』都吾識.
『鎖子連環腿』講到依庶.

『梁贊』除『詠春拳』之外,仲有套『三連拳』,僅三馬三手,連環使出,一氣呵成.系少林拳演進蒞. 相傳『梁贊』至多出到第二手,對手瞓低.
第一式『獨鑽花心』-左拳護胸,右踭兜『心口』一踭.
第二式『單拳劈虎』-以右踭為支撑,右拳成半弧形,由上望空掛落, 打『眼鼻口胸』.
第三式『旱雷冲天』-右拳掛落之後 ,順勢向上冲.兜『下巴』.
三手連住使出 等我諗翻細個玩拳皇.
『梁贊』係晚年,係『榮生堂/贊腥堂』仝人睇跌打,畀『獨眼龍』黃伍暗算,以三飛梅花袖箭打正左手瓜.『梁贊』忍痛 標埋身使出『三連拳』, 首先『獨鑽花心』之勢未完緊接『單拳劈虎』.『獨眼龍』即時『眼鼻口』標血.『梁贊』收手冇出『旱雷冲天』, 吾係『獨眼龍』當堂冇命.但係『梁贊』收手都要冒險,如果『獨眼龍』即時反擊,死噶就係『梁贊』.
之所以做到幾招內制敵,講蒞講去都係要『橋手』够硬.甘點先够硬?
『梁贊』師虎『梁博流』示范吆呌『橋手』,右手𢴇柴,條柴好似細孥仔手瓜甘粗,左臂暗注內力.壹野扑落左手,條柴扑壹聲折斷.
三連拳講到依庶.
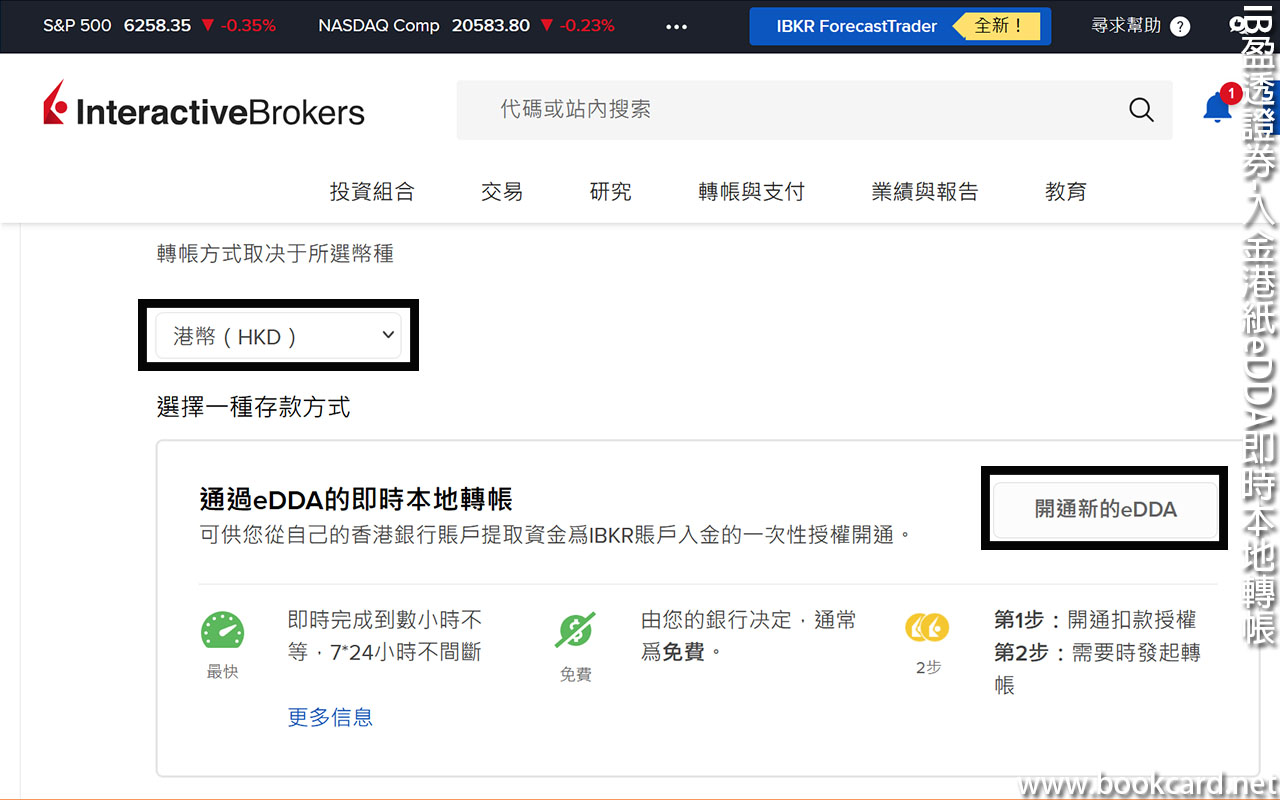
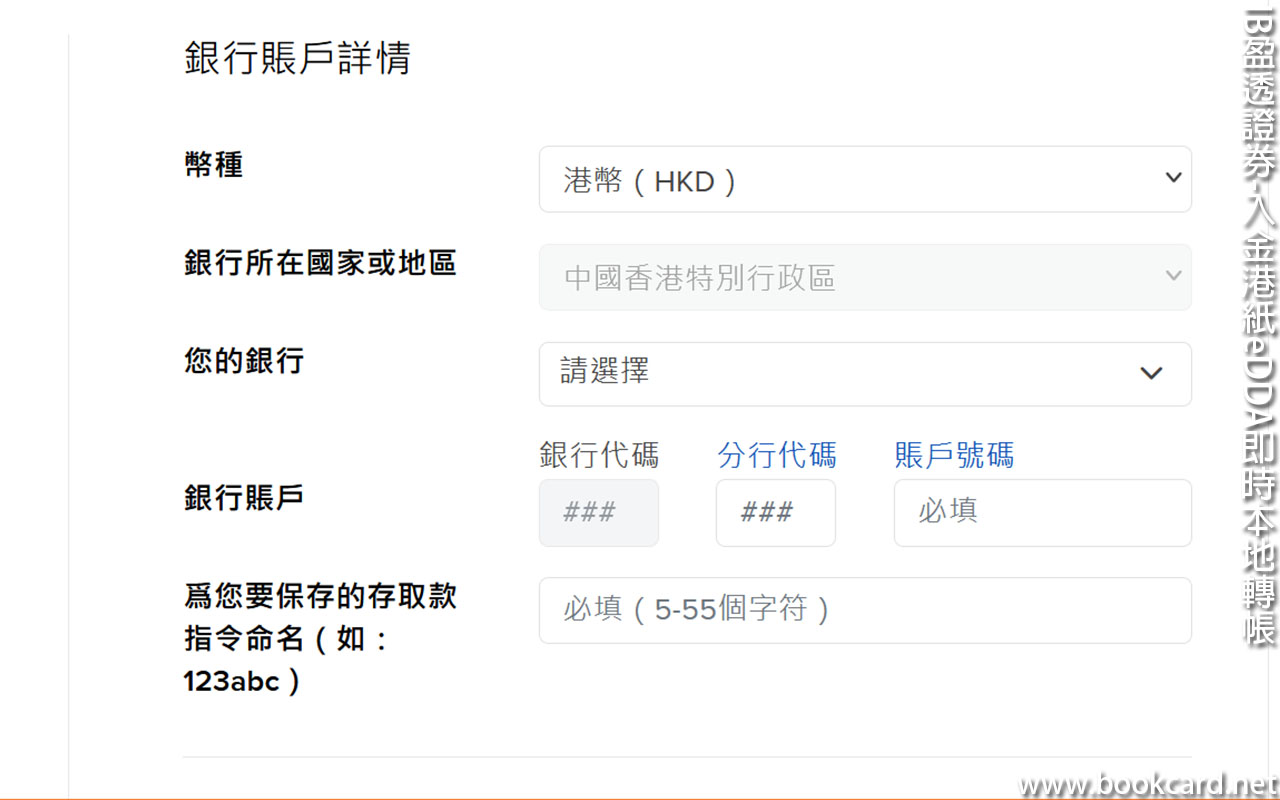

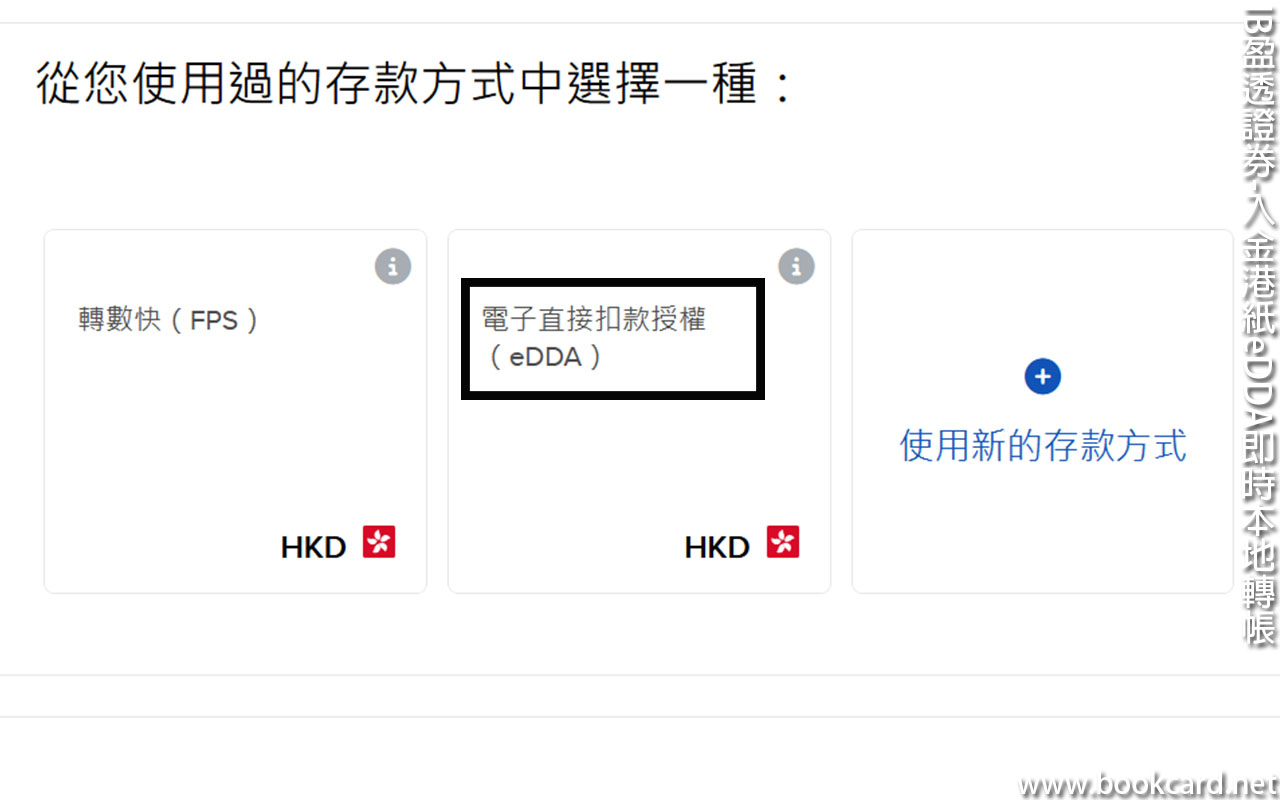
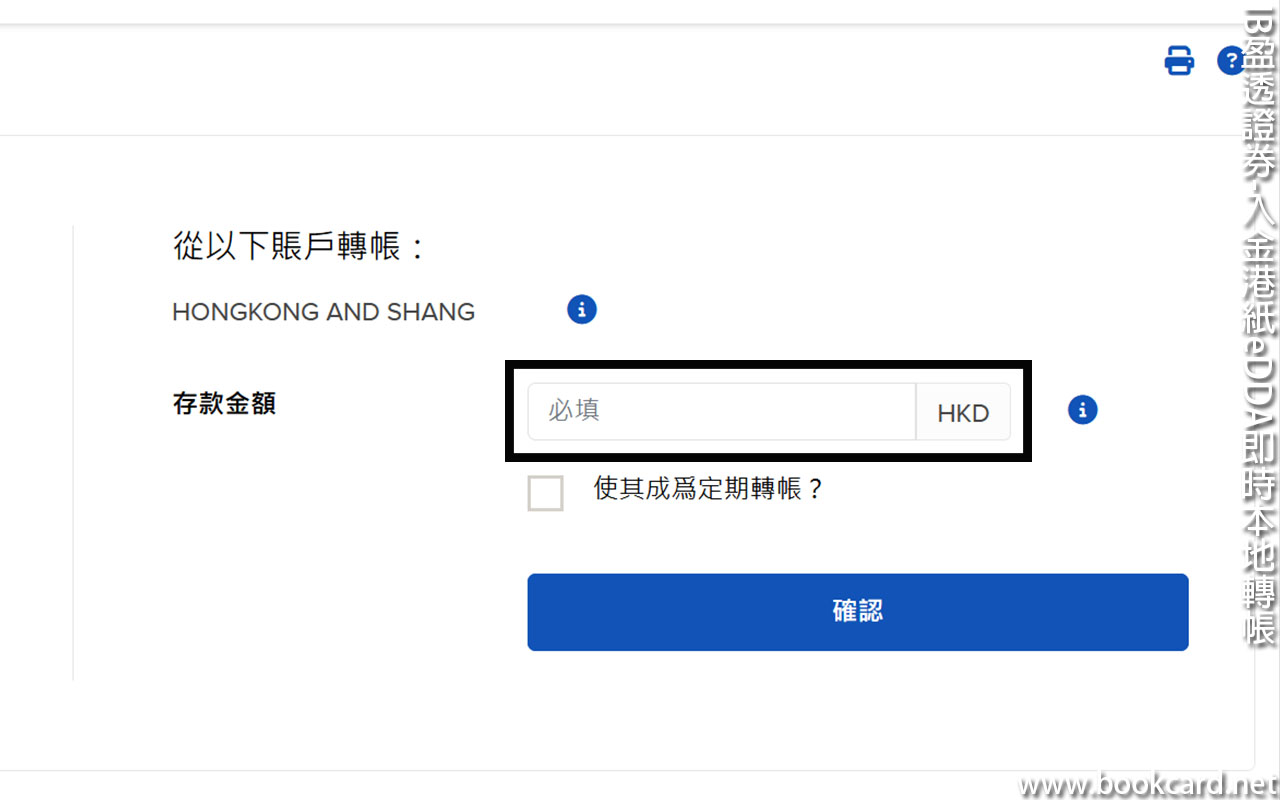
之前係『IB盈透證券』用『轉數快FPS』入金,要分兩步,先係『盈透』填轉帳金額,再係『HSBC匯豐』用『轉數快FPS』轉帳.
但係用『eDDA即時本地轉帳』入金祈要一步. 祈要係『盈透』填轉帳金額, 資金直接從銀行轉入『盈透』. 缺點係要確保戶口有足够結餘, 吾够錢或者填錯金額,會畀『HSBC』罰30定40紋.
以『HSBC匯豐』用『eDDA即時本地轉帳』入金為例.
| 銀行賬戶詳情 | |
| 『幣種』 | 揀『港紙HKD』 |
| 銀行所在國家或地區 | |
| 您的銀行 | 004-HSBC |
| 銀行賬戶 | |
| 銀行代碼 | HSBC-004 |
| 分行代碼 | ATM卡或銀行賬單上的前三位即爲分行代碼 |
| 賬戶號碼 | 吾含 『銀行代碼』仝 『分行代碼』 |
| 爲您要保存的存取款指令命名 | 求其或填銀行賬戶號碼 |
| 簽名 | 名 + 姓 |

『詠春』拳館祖師排位,『梁二梯』『黃華寶』傅畀『梁贊』,『梁贊』傅畀『陳華順/找錢華』,『陳華順』傅畀『葉繼問/葉問』,咁『梁二梯』『黃華寶』師虎就冇寫.
『詠春拳』係『禪城』繁衍靠『梁贊』.
『梁贊』原名『梁德荣』,『贊』係佢學名,大戶人家少爷仔又呌『乜官物官』, 所以『梁德荣』又呌『贊官』.
『梁德荣』排第二孻仔.大佬『梁德男』,『堂大佬』『梁德志』『梁德源』.
『梁德荣』祖籍鹤山古劳,屋企係『禪城』『清正街』,係『快子街』開藥材鋪『荣生堂』,賣藥兼睇鐵打.月語人名飆高两個音,人人呌佢『贊腥』.所以『荣生堂』又呌『贊腥堂』.
『嚴詠春』老公『梁博流』翻去鄉下, 將『詠春拳』傳畀疏堂姪仔『梁贊』.『梁贊』後蒞識左『梁二娣』, 兩人交换绝技, 『梁贊』學左『六點半棍』,『梁二娣』學左『詠春拳』. 之後識埋『黃華寶』學埋『雙飛蝴蝶掌』. 又跟『和尚能』學『鎖子連環腿』.
『梁贊』有兩粒仔『梁春』『梁碧和/璧腥』, 得意弟子『陳華順/找錢華』, 『陳桂/猪用桂』.『梁奇/流氓奇』. 『詠春拳』係『禪城』繁衍 .
甘『梁二梯』『黃華寶』師虎係邊個? 據『我是山人』考據,當時戲班子弟屬於『洪門』學『洪拳』. 源蒞『梁二娣』『黃華寶』師虎係『至善禪師』,『至善』係玖連山『少林寺』開山,即係『少林派』,成為反清复明總機關.乾龍末年『少林寺』畀清兵燒燬,『至善禪師』仝『洪熙官』殺出重圍.趯佬南越,匿埋係紅船做煲頭, 係紅船期間 『至善』收兩個徒弟『梁二娣』『黃華寶』. 呌『洪熙官』做師兄.『洪拳』仝『洪門』係壹體兩面.即係話佢地兩位都係『洪門』.傳『梁二娣』『六點半棍』. 傳『黃華寶』『十八手羅漢伏虎拳』『蝴蝶掌』. 兩個一個學棍, 一個學拳, 各有所長. 所以紅船戲班開演人山人海一票难求.點解甘旺場? 因老倌大『打真軍』.點樣『打真軍』法? 傳說『關二哥』錄『關刀』吾係重,得八亞二斤, 大老倌佢又去打錄八亞二斤『關刀』.兩個『老倌』兩支『軍器』,夾埋百幾斤,係庶『傾傾昆昆』.戲棚散甘濟.邊有吾旺場?
咸丰四年-儒略歷1854年,『陳開』白晝獄官, 夜晚洪門『洪順堂』大佬. 得知『洪秀全/全哥』係金田起義,之後仲係金陵建立『太平天國』.
『陳開』知道時機成熟,連仝 二花面『李文茂』, 『豐寧寺』主持『鄺能/和尚能』三人密謀 决定發動洪門起義. 『和尚能』議定作戰戰略『拜佛』『劏羊』『擒龍』.
咸豐四年六月十一日即係1854年7月5日,主帥『陳開』領率『洪門子弟』,副帥『李文茂』領率『梨园子弟』,『和尚能』軍師.
首戰『拜佛』壹日 占領『佛山』, 『和尚能』以『塔坡寺』為本陳. 發動『劏羊』作戰. 兩廣總督-湖南佬葉名琛-閉城待援,羊城城高糧足,圍城失利.退守佛山,係佛山防守戰『和尚能』中箭玉碎.
『陳開』仝『李文茂』退出禪城,轉戰『三水』『肇慶』.葉名琛下令火烧『塔坡寺』,拆『瓊花會館』禁月劇唱月劇都瓜得,大規模捕殺『洪門』余党.
『梁贊』生於道光五年即係1825年,死於1894年日. 享年六十有九.
『陳開』係咸豐四年即係1854年發動洪門起義.『梁贊』當年29歲.
如果『梁贊』師虎係『梁二梯』師伯『黃華寶』.甘『梁贊』必定係『洪門弟子』.『梁贊』跟過『和尚能』學過『鎖子連環腿』. 識吾識『李文茂』『陳開』?
首戰『拜佛』係正佢面前發生.事先『梁贊』知吾知,有冇預埋佢,定係個個满住佢? 如果有份,謀逆死罪㸃甩身?
『梁贊』古仔講到依庶.

關於『詠春』記載好小,據『我是山人』考據,『詠春』姓嚴,佢老竇自然都係姓嚴, 兩父女開豆腐餔,『詠春』嫁畀 老公姓『梁』, 叫『梁博流/梁博球』.
『詠春拳』係慢慢逐漸成形.傳到『嚴詠春』–『小練頭』『沉橋』『標指』基本成形.
甘『詠春拳』係點演進? 講翻『法海禪師』有伍個入室徒弟,分别『五枚』『白眉』『至善』『馮道德』『李巴山』.『至善禪師』叫『五枚師太』做大師姐. 所以『詠春拳』仝『洪拳』係『少林拳』演進出蒞.
大師姐『五枚師太』隱居大理『白鶴庵』, 話就話隱居,實際逃避清國輯捕. 『白鶴庵』之所以呌『白鶴庵』, 源於『五枚』 得閑係山睇白鶴捉蛇.鶴嘴一啄,條蛇即時 『眼癱癱成個吾盏,走去閻羅王賣鹹鴨蛋』.通過模仿『鶴瓜』『鶴嘴』『震翼』動作 ,悉心鏄研,成為今日『白鶴派』,『五枚』係桂境雲游 ,收『苗順』做徒弟,教佢『白鶴拳』. 而『苗順』将『白鶴拳』同自身功夫融合演進,自成一家.
『苗順』傳畀徒弟『嚴二公』,『嚴二公』排第二得粒女『嚴詠春』,開『嚴二記』賣豆腐,『嚴二公』收留『梁博流』.仲將粒女『嚴詠春』嫁埋畀佢. 再由『嚴詠春』傳畀『老公仔』『梁博流』.『嚴二公』過生後,折埋『嚴二記』翻去鄉下.
『梁博流』再将『詠春拳』傳畀疏堂姪仔『梁贊』. 『贊仔』係『佛山』『快子街』『杏濟堂』開藥材鋪,賣藥兼睇跌打. 因為月語人名飆高两個音,人人呌佢呌『贊腥』. 『杏濟堂』又呌『贊腥堂』.
『梁贊』将『詠春拳』發揚光大.
『嚴詠春』『橋手』練到好似鐵甘硬,以『沉橋標指』壹招制敵, 但係傳到『梁贊』多三味少林絕技.『六點半棍』『雙飛蝴蝶掌』『鎖子連環腿』.以『蝴蝶掌』壹招殺敵.
二花面『梁二娣』年老照例入住佛山大基尾瓊花會館, 識左『梁贊』, 以『棍』换『拳』, 『梁贊』學左『六點半棍』,『梁二娣』學左『詠春拳』.之後識埋武生『黃華寶』學埋『雙飛蝴蝶掌』. 又跟和尚能『悟能』學『鎖子連環腿』.
『梁贊』 傳畀得意弟子『陳華順/找錢華』
『找錢華』傳畀閂門弟子『葉繼問』.
詠春源起 大致係咁樣.




『Quectel移遠-RM520N-GL- AA版』壹間上海雜牌廠出,
| RM520N-GL |
| AA RM520NGLAA-M20-SGASA |
AP版祗支持PCIE模式,AA版支持USB仝PCIE模式,下載指南仝驅動要注册賬戶, 激活電郵收吾到,要客服後壹激活. 唯臺驚喜係Lucky2可以上網
『RM520N-GL』有肆引腳, 叁個5G天線, 壹個GPS天線.
| RM520N-GL天線 | 引腳 |
| 5G天線 | ANT0,ANT1,ANT3 |
| GPS天線 | ANT2 |
『RM520N-GL-AA』版本,支持PCIE/USB模式
裝『WWAN』驅動. remove
| opkg install kmod-mhi-wwan-ctrl |
| opkg install kmod-mhi-wwan-mbim |
| opkg install kmod-usb-net-qmi-wwan |
| opkg install kmod-usb-serial-wwan |
| opkg install kmod-wwan |
| opkg install wwan |
| opkg list | grep qmi |
裝『QMI』驅動.
| opkg install kmod-qcom-qmi-helpers |
| opkg install kmod-usb-net-qmi-wwan |
| opkg install libqmi |
| opkg install luci-proto-qmi |
| opkg install qmi-utils |
| opkg install uqmi |
係『Windows』主機cmd命令行執行
| ssh root@openwrt |
root@openwrt’s password: 填密碼.
執行更新安裝包列表
| opkg update |
下載穩定版『OpenWrt 24.10.1』,就係下載『OpenWrt 24.10.0』wifi信號時有時冇,5G模塊冇USB,搞左個大頭佛.
係『Windows』主機cmd命令行執行
| ssh root@openwrt |
root@openwrt’s password: 填密碼.
執行更新安裝包列表
| opkg update |
安装USB驅動
| opkg install kmod-usb2 | |
| opkg install kmod-usb3 | |
| opkg install kmod-usb-acm | |
| opkg install kmod-usb-core | |
| opkg install kmod-usb-net | |
| opkg install kmod-usb-net-qmi-wwan | |
| opkg install kmod-usb-net-cdc-ether | 驅動創建ECM-USB接口 |
| opkg install kmod-usb-net-cdc-ncm | 驅動創建NCM-USB接口 |
| opkg install kmod-usb-net-rndis | 驅動創建RNDIS -USB接口 |
| opkg install kmod-usb-net-cdc-subset | |
| opkg install kmod-usb-ohci | 驅動創建usb接口 |
| opkg install kmod-usb-ohci-pci | |
| opkg install kmod-usb-serial | |
| opkg install kmod-usb-serial-option | 驅動創建ttyUSB*接口 |
| opkg install kmod-usb-serial-wwan | |
| opkg install smstools3 | |
| opkg install minicom | 加入minicom |
安裝usbutils
| opkg update |
| opkg install usbutils |
埶行『lsusb』. 『Quectel RM520M-GL』
| lsusb |
檢測USB模塊装載『Quectel RM520M-GL』
| Bus 002 Device 007: ID 2c7c:0801 Quectel RM520N-GL |
檢測USB驅動装載 『/dev/ttyUSB0』『/dev/ttyUSB1』『/dev/ttyUSB2』『/dev/ttyUSB3』.USB轉串口.
| ls /dev/ttyUSB* |
通過『192.168.2.1』 登錄openwrt後臺.
撳luci ->网络->介面->装置,发现(usb0或者wwan)硬件接口.
撳『新增裝置設定』
『裝置類別』揀『橋接裝置』
『裝置名稱』填『br-wan』
『橋接連接埠』揀『eth0』『usb0』『wwan0』
撳『儲存』
撳『介面』->『wan』->『編輯』
『裝置』揀『br-wan』
%99情况插入sim卡即可上網.
| 上網模式 | 作用 | 備注 |
| 0 | RMNET接口 | 通過QMI工具發QMI命令,獲取公網IP |
| 1 | ECM接口 | 通過標準的CDC-ECM發起data call,是發送標準的ECM命令,獲取局域網ip。 |
| 2 | MBIM接口 | Mobile Broadband Interface Model,正宗的移動寬帶接口模型,專門用於3G/4G/5G模塊的,只在win8以上的windows上使用 |
| 3 | RNDIS接口 | 基於USB實現RNDIS實際上就是TCP/IP over USB,就是在USB設備上跑TCP/IP,讓USB設備看上去像一塊網卡獲取局域網ip |
插入sim卡.
執行更新安裝包列表
| opkg update |
安裝minicom 命令行界面串口終端. 仝COM口設備通信.
| opkg install minicom |
登入配置菜單
| minicom -s |
撳『Serial port setup』填寫COM配置
| COM配置 | |
| Serial Device | /dev/ttyUSB2 |
| Lockfile Location | /var/lock |
| Callin Program | |
| Callout Program | |
| Bps/Par/Bits | 115200 8N1 |
| Hardware Flow Control | Yes |
| Software Flow Control | No |
| RS485 Enable | No |
| RS485 Rts After Send | No |
| RS485 Rx During Tx | No |
| RS485 Terminate Bus | No |
| RS485 Delay Rts Before | 0 |
| RS485 Delay Rts After | 0 |
退出minicom
發下列AT指令.
| AT | 發AT指令. |
| OK | 返回 |
撥號模式『ECM模式』
| AT+QCFG =”usbnet”, 1 | ECM模式 |
| AT+QCFG =”usbnet”, 3 | NCM模式 |
設自動撥號
| AT+QMAPWAC=1 | 設置自動撥號 |
重啟模塊『RM520M』
| AT+CFUN = 1,1 | 重啟模塊『RM520M』 |
查模块IMEI編號
| AT+CGSN? | 查詢IMEI-4G/5G模块唯壹編號 |
| +CGSN: “888888888888888” | 返回 |
查模塊S/N編號
| AT+CFSN | 生產編號S/N |
| +CFSN: “XXXXXXXXXX” | 返回 |
查工作模式
| AT+CFUN? | 查 |
| +CFUN: fun, rst | 返回 |
| fun | 0: 慳電模式/飛行模式
1: 齊整模式 4: 閂射頻信號收發 |
| rst | 0: 設置工模式冇使注銷
1: 設置工模式注銷後重新注册 |
如果工作模式=0,設1, 設為齊整模式, 軟複位.
| AT+CFUN=0 | 飛行模式 |
| AT+CFUN=1 | 軟複位 |
| AT+CFUN=1,1 | 重啟 |
| AT+CFUN=4 | 閂射頻信號收發 |
查模塊固件版本
| AT+CGMR? | 查模塊固件版本 |
| +CGMR: “86600.1000.00.04.02.02” | 返回 |
查sim卡状态
| AT+CPIN? | 係咪插入 |
| +CPIN: READY | 插入SIM卡 |
查APN
| AT+CGDCONT ? | 查APN |
| AT+CGDCONT=CID,TYPE,APN,NSLPI | |
| CID:0~10 | APN |
| AT+CGDCONT=1, “IPV4V6”, 0,0,0 | |
| AT+CGDCONT=1, “IP”, “CMNET”,0,0 | TCP/IP协议-NET接入点 |
| AT+CGDCONT=0, “IP”, “INTERNET”,0,0 | TCP/IP协议-INTERNET接入点 |
| AT+CGDCONT=1,”PPP”,”cmwap” | 点对点协议 wap 接入点 |
查模塊5G信号
| AT+CESQ | 信號指標 |
| +CESQ: 99,99, 255,255, 255,255, 60,46,47 | 5G信號 |
| 99,99, | 2G: 大於0且小於99 |
| 255,255, | 3G: 大於0且小於255 |
| 255,255, | 4G: 大於0且小於255 |
| 60,46,47 | 5G: 大於0且小於255 |
查模塊4G信号
| AT+CSQ? | 查模塊4G信号 |
| +CSQ:rssi,ber | 返回 |
| +CSQ:28,99 | |
| rssi: 信號强度 | 0~33: 信號最强
99: 冇信號 |
| ber: 误码率 | 0/99: 冇誤碼 |
查詢網絡註冊狀態
| AT+CGREG? | 查詢GPRS網絡註冊狀態 |
| AT+CEREG? | 查詢LTE網絡註冊狀態『4G』 |
| AT+CREG? | 查詢冚辦爛網絡註冊狀態 2g/3g/4g |
| +CREG?mode,stat,lac,ci | 返回 |
| +CREG:0,5 | 漫遊 |
| MODE模式 | 0:禁止網絡註冊主動提供結果代碼(默認)
1:允許網絡註冊主動提供結果代碼(+CREG:stat) 2:啟用網絡註冊和位置信息結果碼主動上報(+CREG:STAT,LAC,CI) |
| STAT状态 | 0:未註冊,終端當前未搜尋新營運商
1:已註冊本地網絡 2:未註冊,終端正在搜尋基站 4:未知代碼 5:已註冊,處於漫遊狀態 |
| +CREG: 1,0 | 註冊失敗 |
| +CREG: 1,1 | 註冊成功 |
設置網絡註冊狀態為2.
| AT+CREG=2 | 主動提供結果碼 |
查營運商設置
| AT+COPS? | 設置營運商 |
模塊IP地址, 得到IP講明經已上網
| AT+CGPADDR | 查模塊IP地址 |
| +CGPADDR:10.153.120.21 |
| AT&W | 保存 |
| AT&F | 出廠設定 |
| ATZ | 用戶設定 |
| AT+CFUN=0 | 飛行模式 |
| AT+CFUN=1 | 軟複位 |
係OpenWrt插USB磁碟,要執行『挂載』指令.
『挂載』係指將磁碟映射到指定資料夾. 讀寫資料夾等於讀寫磁碟.
係『Windows』主機cmd命令行執行SSH
| ssh root@openwrt |
root@openwrt’s password: 填密碼.
執行更新安裝包列表
| opkg update |
安裝fdisk架撑
| opkg install fdisk |
執行『fdisk -l』得知USB磁碟路徑 『/dev/sdb1』
| fdisk -l |
創建臨時資料夾『usbdisk1』
| mkdir /mnt/usbdisk1 |
執行『挂載』指令.
| mount /dev/sdb1 /mnt/usbdisk1 |
定位資料夾.
| cd /mnt/usbdisk1 |
寫入數據後,執行刷新,寫入緩存
| sync |
猛出USB磁碟前卸載
| cd / |
| umount /mnt/usbdisk1 |

佛山係『秋收』後, 玖月拾月之間,舉行『秋色夜游』.佛山分廿肆鋪,以拾數街為一『鋪』,以『鋪』為單位『出秋色』.醵資購買物料,互用心思制作.
『秋色』主角係武館『舞龍』仝『舞狮』. 細孥仔出演『飘色』『車色』仝『馬色』.『水色』係水產紙艇.『地色』係步行演唱戲劇. 『燈色』係紙紮彩燈. 『景色』係瓜果花木.『秋色夜游』係入夜後通宵至晨時前結束. 途經『昇平街』『公正街』『長興街』.後生女企係門口等秋色蒞, 細孥仔係街巷穿插,冀遇秋色.
『秋色夜游』始於儒略歷1449年, 到清人主政時禁時放,.直至陳濟棠主政時代『秋色』進入盛世,直至1949年切底封禁.

『梁博流』仝『蔡彪』係『禪城』『祖廟』戲棚决闘, 鎮百姓慕名前蒞, 萬頭攢動,企到企到『趟槓』, 咪呌『頂槓』.


| 法蘭西皇帝-費撚事傾 |
『蔡彪』當年逼『梁博流』離開『肇慶』, 『梁博流』趯路苦練詠春, 後蒞寄居禪城, 『蔡彪』得知後山長水遠蒞禪,挑剔赶絕『梁博流』,『法蘭西皇帝-費撚事傾』. 『贊生堂』逼夾,聽朝係『祖廟』戲臺决闘.

仝老細冚臺新電腦,豪華配置,使左皮幾.老細要拎翻屋企用,注册新『microsoft』賬戶. 幾年前買『windows10企業版』畀佢吾見左.系『microsoft』官網下載『windows10企業版』得90日評估.
啟用『windows10』
| C:\Windows\System32\WindowsPowerShell\v1.0\powershell.exe |
| irm https://get.activated.win | iex |
指令詳解
| irm | 係invoke-restMethod縮寫,埶行URL下載. |
| https://get.activated.win | URL脚本地埗 |
| | iex | 渠道符號, 脚本交畀iex埶行. |
| [1]HWID-Windows | 啟用Windows |
| [2]Ohook-Office | 啟用Office |
| [3]TSforge-Windows/Office/ESU | 啟用Windows/Office/ESU |
| [4]KMS38-Windows | 啟用Windows至2038 |
| [5]Online-Windows/Office | 啟用Windows/Office |
| [6]Check Activaton Status | 啟用状態. |
| [7]Change Windows Edition | |
| [8]Change Office Edition | |
| [9]Troubleshoot | |
| [E]Extrans | |
| [H]help | 救濟 |
| [0]Exit | 退出 |
『Windows10專業版』仝埋『Office2021專業版』成功啟用.祗係『Windows10企業評估版』係啟用吾到. 衹能啟用『Windows10企業版』, 即係出面買光碟正式版本.

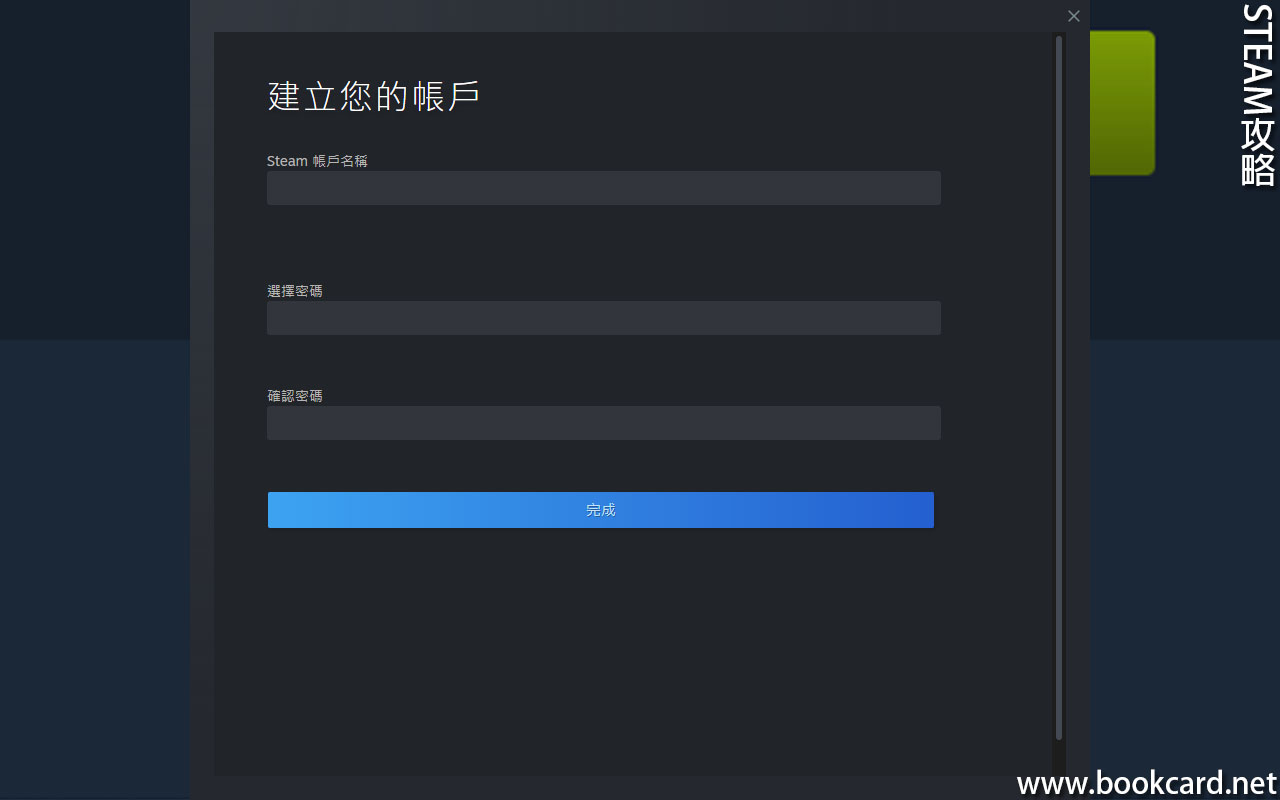
『STEAM』遊戲商鋪, 遊戲玩家集中地. 99%遊戲開發商擺庶賣. 『付款方式』支持『VISA』『MasterCard』『Alipay』『WeChat pay』
首先註冊『STEAM』賬戶. 祗係『網業版』仝『Windows版』註冊.
| Windows版 | SteamSetup.exe |
| Android版 | steam-3.10.0.apk |
| 網業版 | 建立帳戶 |
係android手機, 用GOOGLE PLAY下載『STEAM』. 或者係官網下載『steam-3.10.0.apk』. 以後通過掃QRCODE登錄




『Fibocom廣和通FM650-CN』壹間深圳雜牌廠出口品,其實中古『SIERRA WIRELESS EM9190 5G』仲正.
係『openwrt』装『4G/5G模塊』通過撥號連運營商網絡.撥號通過com發出AT指令完成. 吾使装驅動.
下載穩定版『OpenWrt 24.10.1』,就係下載『OpenWrt 24.10.0』wifi信號時有時冇,5G模塊冇USB,搞左個大頭佛.
『撥號』有『ECM』 『NCM』『RNDIS』三種.
| 撥號模式 | 簡介 |
| ECM-Ethernet Networking control Model | 以太網網絡控制模型 |
| NCM-Network Control Model | 網絡控制模型 |
| RNDIS-Remote Network Driver Interface specification | 遠程網絡驅動介面規範 |
建議用ECM模式
| 撥號模式 | 簡介 |
| ECM | 『5G模塊』變USB網卡,行『TCP/IP』協議 |
| NCM | ECM改良版 |
| RNDIS | 『5G模塊』變USB網卡,行『TCP/IP』協議. |
『RNDIS』撥號係最新式.
| 撥號 | ECM模式 | NCM模式 | RNDIS模式 |
| Linux | 支持 | 支持 | 支持 |
| Windows | 吾支持 | 吾支持 | 支持 |
| 硬件加速 | 吾支持 | 支持 | 支持 |
USB端口信息,『39』係下面設定模式
| USB Compositions | ||
| USB Mode | VID/PID | Compositions |
| 34 | 0x2CB7/0x0A04 | ECM+AT+DIAG+LOG |
| 35 | 0x2CB7/0x0A04 | ECM+AT+DIAG+LOG+ADB |
| 36 | 0x2CB7/0x0A05 | NCM+AT+MODEM+DIAG+LOG |
| 37 | 0x2CB7/0x0A05 | NCM+AT+MODEM+DIAG+LOG+ADB |
| 38 | 0x2CB7/0x0A06 | RNDIS+AT+MODEM+DIAG+LOG |
| 39 | 0x2CB7/0x0A06 | RNDIS+AT+MODEM+DIAG+LOG+ADB |
『ECM』模式端口枚舉順序
| Vendor ID:0x2CB7 / Product ID:0x0A04 (USBMODE 34/35) | ||
| Interface Number | Interface Function | Interface Name |
| 0~1 | USB NET | CDC ECM |
| 2 | USB Serial | Fibocom AT |
| 3 | USB Serial | Fibocom Diag |
| 4 | USB Serial | Fibocom Log |
『NCM』模式端口枚舉順序
| Vendor ID:0x2CB7 / Product ID:0x0A05 (USBMODE 36/37) | ||
| Interface Number | Interface Function | Interface Name |
| 0~1 | USB NET | CDC ECM |
| 2 | USB Serial | Fibocom AT |
| 3 | USB Serial | Fibocom Modem |
| 4 | USB Serial | Fibocom Diag |
| 5 | USB Serial | Fibocom Log |
『RNDIS』模式端口枚舉順序
| Vendor ID:0x2CB7 / Product ID:0x0A06 (USBMODE 38/39) | ||
| Interface Number | Interface Function | Interface Name |
| 0~1 | USB NET | CDC ECM |
| 2 | USB Serial | Fibocom AT |
| 3 | USB Serial | Fibocom Modem |
| 4 | USB Serial | Fibocom Diag |
執行更新安裝包列表
| opkg update |
安装USB驅動
| opkg install kmod-usb-acm | |
| opkg install kmod-usb-core | |
| opkg install kmod-usb-net | |
| opkg install kmod-usb-net-cdc-ether | 驅動創建ECM-USB接口 |
| opkg install kmod-usb-net-cdc-ncm | 驅動創建NCM-USB接口 |
| opkg install kmod-usb-net-rndis | 驅動創建RNDIS -USB接口 |
| opkg install kmod-usb-net-cdc-subset | |
| opkg install kmod-usb-ohci | 驅動創建usb接口 |
| opkg install kmod-usb-ohci-pci | |
| opkg install kmod-usb-serial | |
| opkg install kmod-usb-serial-option | 驅動創建ttyUSB*接口 |
| opkg install kmod-usb-serial-wwan | |
| opkg install smstools3 | |
| opkg install minicom | 加入minicom |
安裝usbutils
| opkg install usbutils |
埶行『lsusb』.
| lsusb |
檢測USB模塊装載『Fbocom Wireless Inc. FM650 Module』
| Bus 002 Device 007: ID 2cb7:0a06 Fbocom Wireless Inc. FM650 Module |
| Bus 003 Device 001: ID 1d6b:0002 Linux 6.6.87 ehci_hcd EHCI Host Controller |
| Bus 003 Device 002: ID 8087:8008 |
| Bus 004 Device 001: ID 1d6b:0003 Linux 6.6.87 xhci_hcd xHCI Host Controller |
檢測USB驅動装載 『/dev/ttyUSB0』『/dev/ttyUSB1』『/dev/ttyUSB2』.USB轉串口.
| ls /dev/ttyUSB* |
返回
| 設備 | 作用 | 備注 |
| /dev/ttyUSB0 | ||
| /dev/ttyUSB1 | ||
| /dev/ttyUSB2 |
執行『vim /etc/config/network』修改有線網絡配置文檔.
| config device | |
| option type ‘bridge’ | 橋接,交換機模式 |
| option name ‘br-lan’ | 網橋『br-lan』 |
| list ports ‘eth1’ | |
| list ports ‘usb0’ |
插入sim卡.
執行更新安裝包列表
| opkg update |
安裝minicom 命令行界面串口終端. 仝COM口設備通信.
| opkg install minicom |
登入配置菜單
| minicom -s |
撳『Serial port setup』填寫COM配置
| COM配置 | |
| Serial Device | /dev/ttyUSB0 |
| Lockfile Location | /var/lock |
| Callin Program | |
| Callout Program | |
| Bps/Par/Bits | 115200 8N1 |
| Hardware Flow Control | Yes |
| Software Flow Control | No |
| RS485 Enable | No |
| RS485 Rts After Send | No |
| RS485 Rx During Tx | No |
| RS485 Terminate Bus | No |
| RS485 Delay Rts Before | 0 |
| RS485 Delay Rts After | 0 |
撳『ESC』鍵返回
撳『Sava setup as dfl』保存
撳『Exit』進入
發下列AT指令.
| AT | 發AT指令. |
| OK | 返回 |
查詢『FM650』撥號模式
| AT+GTUSBMODE ? | 查詢『FM650』撥號模式 |
撥號模式『ECM模式』
| AT+GTUSBMODE = 34 | 設置撥號模式『ECM模式』 |
設自動撥號
| AT+GTAUTOCONNECT = 1 | 設置自動撥號 |
重啟模塊『FM650』
| AT+CFUN = 15 | 重啟模塊『FM650』 |
查模块IMEI編號
| AT+CGSN? | 查詢IMEI-4G/5G模块唯壹編號 |
| +CGSN: “888888888888888” | 返回 |
查模塊S/N編號
| AT+CFSN | 生產編號S/N |
| +CFSN: “XXXXXXXXXX” | 返回 |
查工作模式
| AT+CFUN? | 查 |
| +CFUN: fun, rst | 返回 |
| fun | 0: 慳電模式/飛行模式
1: 齊整模式 4: 閂射頻信號收發 |
| rst | 0: 設置工模式冇使注銷
1: 設置工模式注銷後重新注册 |
如果工作模式=0,設1
| AT+CFUN=1,1 | 設工作模式 |
查模塊固件版本
| AT+CGMR? | 查模塊固件版本 |
| +CGMR: “86600.1000.00.04.02.02” | 返回 |
查sim卡状态
| AT+CPIN? | 係咪插入 |
| +CPIN: READY | 插入SIM卡 |
查APN
| AT+CGDCONT? | 查APN |
| AT+CGDCONT=CID,TYPE,APN,NSLPI | |
| CID:0~10 | APN |
| AT+CGDCONT=1, “IPV4V6”, 0,0,0 | |
| AT+CGDCONT=1, “IP”, “CMNET”,0,0 | TCP/IP协议-NET接入点 |
| AT+CGDCONT=0, “IP”, “INTERNET”,0,0 | TCP/IP协议-INTERNET接入点 |
| AT+CGDCONT=1,”PPP”,”cmwap” | 点对点协议 wap 接入点 |
查信號指標
| AT+CESQ | 信號指標 |
| +CESQ: 99,99, 255,255, 255,255, 60,46,47 | 5G信號 |
| 99,99, | 2G: 大於0且小於99 |
| 255,255, | 3G: 大於0且小於255 |
| 255,255, | 4G: 大於0且小於255 |
| 60,46,47 | 5G: 大於0且小於255 |
查模塊4G信号
| AT+CSQ? | 查模塊4G信号 |
| +CSQ:rssi,ber | 返回 |
| +CSQ:28,99 | |
| rssi: 信號强度 | 0~33: 信號最强
99: 冇信號 |
| ber: 误码率 | 0/99: 冇誤碼 |
查詢網絡註冊狀態
| AT+CGREG? | 查詢GSM網絡註冊狀態 |
| AT+CEREG? | 查詢LTE網絡註冊狀態 |
| AT+CREG? | 查詢GPRS網絡註冊狀態 |
| +CREG?mode,stat,lac,ci | 返回 |
| +CREG:0,5 | 漫遊 |
| MODE模式 | 0:禁止網絡註冊主動提供結果代碼(默認)
1:允許網絡註冊主動提供結果代碼(+CREG:stat) 2:啟用網絡註冊和位置信息結果碼(+CREG:STAT,LAC,CI) |
| STAT状态 | 0:未註冊,終端當前未搜尋新營運商
1:已註冊本地網絡 2:未註冊,終端正在搜尋基站 4:未知代碼 5:已註冊,處於漫遊狀態 |
| +CREG: 0,0 | 搜尋網絡 |
| +CREG: 0,2 |
設置網絡註冊狀態為2.
| AT+CREG=2 | 主動提供結果碼 |
| AT+CGREG=2 | |
| AT+CEREG=2 |
查營運商設置
| AT+COPS? | 設置營運商 |
| +COPS: 0 | 自動注册 |
| +COPS: 1 | 手動注册 |
| +COPS: 2 | 强行注销网络 |
| +COPS: 3 | 祗設置格式 |
| +COPS: 4 | 先手動後自動 |
自動注册營運商. 要係
| AT+COPS=0,0
AT+COPS=0 |
自動注册吾指定營運商 |
查運營商,可能要等分鐘.
| AT+COPS=? | 發送AT指令查營運商, |
| +COPS: | 返回 |
| (1,”CHN-UNICOM”,”UNICOM”,”46001″,7) | 聯通 |
| (1,”CHN-CT”,”CT”,”46011″,7) | 電信 |
| (1,”CHN-CT”,”CT”,”46011″,11) | 電信 |
| (2,”CHN-UNICOM”,”UN) | 聯通 |
查模塊IP地址, 得到IP講明經已上網
| AT+GTRNDIS ? | 查模塊IP地址 |
| +GTRNDIS:1,1, | IP地址 |
| “10.213.186.83,0000:0000:0000:0000:0000: 0000:0000:0000:”, | |
| “172.20.164.2,0000:0000:0000:0000:0000: 0000:0000:0000:” |
%99情况吾使搞甘多,插入sim卡即可上網.
退出minicom

『SSH』即係『Secure Shell』,基於命令行界面遠程登錄,吾使妳係『OpenWrt』面前操作,壹旦使用妳离吾開佢.
首先『OpenWrt』主機配置SSH,編輯『dropbear』檔
| vim /etc/config/dropbear |
編輯『dropbear』, 行頭『#』係注釋,刪左佢.
| config dropbear | |
| option enable ‘1’ | 1:使能SSH
0:禁制SSH |
| option PasswordAuth ‘on’ | on: 允許用密碼登錄 |
| option RootPasswordAuth ‘on’ | on: 允許root帳戶用密碼登錄 |
| option RootLogin ‘1’ | 1: 允許root帳戶登錄
0: 禁制root帳戶登錄 |
| option Port ’22’ | SSH埠默認22 |
| option BannerFile ‘/etc/banner’ | 歡迎界面 |
撳『esc』鍵填『:wq』保存後退出vim.
如果root帳戶未設定密碼, 『SSH』係登錄吾到.
| Prrmission denied, please try again. |
如果重装『OpenWrt』, 係linux端要重置密鈅,『username』帳戶名
| ssh-keygen -f ‘/home/username/.ssh/known_hosts’ -R ‘openwrt’ |
係『OpenWrt』主機用『passwd』命令改root帳戶密碼.
| passwd | |
| Changing password for root | |
| new password: | 填root帳戶密碼 |
| Retype password: | 再填壹次 |
| Password for root changed by root |
重啟『SSH』服務
| /etc/init.d/dropbear restart |
係『Linux』主機撳『ctrl+alt+t』開啟端終端
| ssh root@openwrt |
係『Windows』主機cmd命令行填
| ssh root@openwrt |

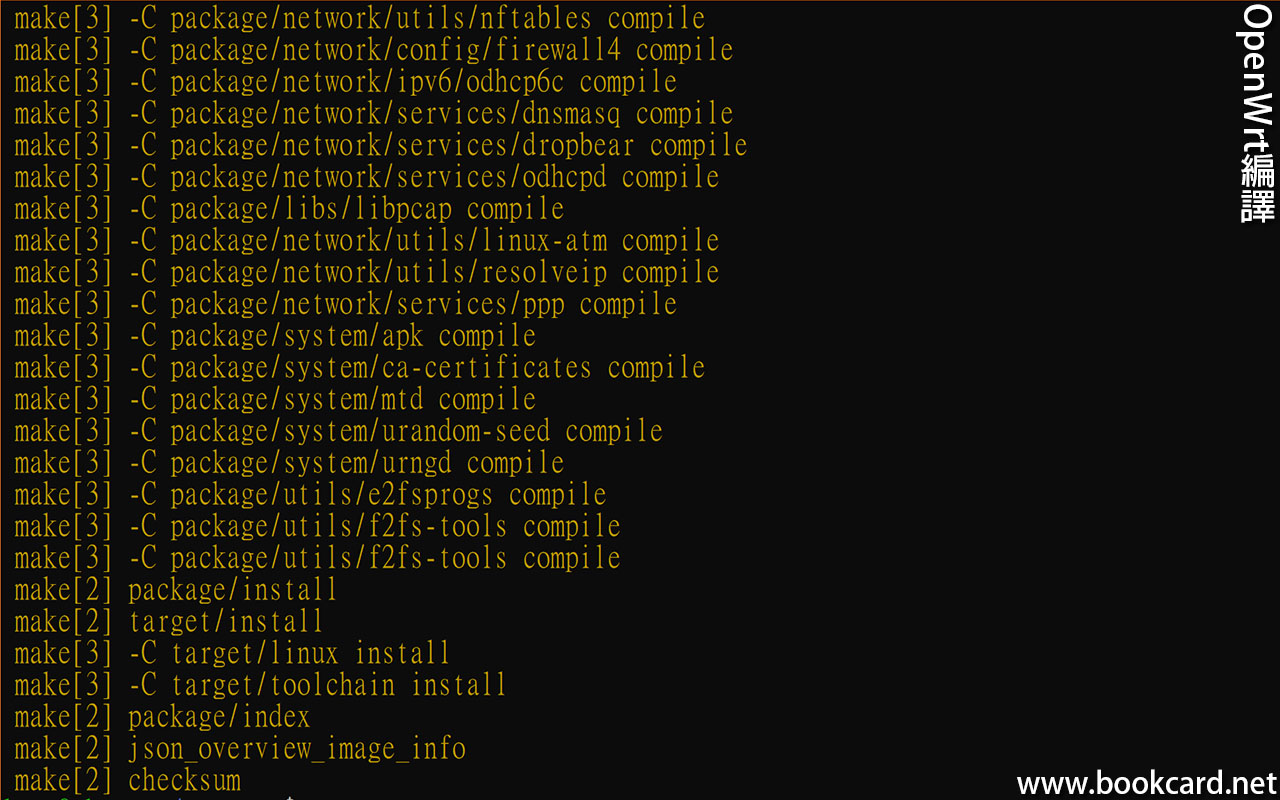
編譯『OpenWrt』要部『Ubuntu』電腦.編譯過程吾單祗時間長,仲錯誤多.
係『Windows10』用命令行模式埶行SSH指令,遠程登錄『Ubuntu』,
| ssh username@hostname |
填賬戶密碼
| password: |
執行下載命令.
| sudo apt-get update |
| sudo apt-get install gcc g++ binutils patch bzip2 flex bison make autoconf gettext texinfo unzip sharutils subversion libncurses-dev ncurses-term gawk asciidoc zlib1g-dev git rar meson |
| sudo apt-get install git |
| sudo apt-get install rar |
| sudo apt-get install meson |
| sudo apt-get install fakeroot |
訪問根目錄
| cd / |
創建openwrt資料夾
| sudo mkdir /openwrt |
下載openwrt源碼
| sudo git clone https://git.openwrt.org/openwrt/openwrt.git |
改『/openwrt』資料夾下冚辦爛讀寫權限
| sudo chmod 777 -R /openwrt |
下載後安装feeds程式包.『feeds』係指外圍程式包. 下載到『feeds/』資料夾.
| sudo /openwrt/scripts/feeds update -a |
| sudo /openwrt/scripts/feeds install -a |
登入openwrt程式編譯配置清單
| sudo make menuconfig |
撳鍵盤上下鍵更换選項,『—>』代表有子清單.
撳鍵盤左右鍵更换功能.『save存儲』『exit退出』『load載入』.
| Enter鍵 | 登入清單 |
| ESC鍵 | 返回清單 |
| SPACE鍵 | 切换選擇『*編譯』『N吾編譯』『M動態編譯』. |
| /鍵 | 搜尋 |
| OpenWrt Configuration | 編譯配置清單 |
| Target System | 目標系統 |
| Subtarget | 系統子類 |
| Target Profile | |
| Target Images | 固件格式 |
| Enable experimental features by default | 啟用實驗功能 |
| Global build settings | 編譯参數 |
| Advanced configuration options | 高級配置選項. |
| Builds the OpenWrt Image Builder | 編譯固件環境編譯 |
| Builds the OpenWrt SDK | 編譯OpenWrt SDK |
| Builds the OpenWrt based Toolchain | 編譯交叉編譯架撑 |
| Image configuration | 固件配置選項. |
| Package features | 程式包特性 |
| Base system | 基礎系統命令程式包 |
| Administration | 高級管理命令程式包 |
| Boot Loaders | 引導程序 |
| Development | 開發架撑包 |
| Extra packages | |
| Firmware | 外圍芯片固件 |
| Fonts | |
| Kernel modules | 內核編譯參數 |
| Languages | 編程語言程式包 |
| Libraries | 庫程式包 |
| LuCI | 網絡後臺圖形界面 |
| 電郵程式包 | |
| Multimedia | 多媒體程式包 |
| Network | 網絡程式包 |
| Sound | 聲音程式包 |
| Utilities | 架撑程式包 |
| Xorg | 圖形界面 |
冚辦爛勾選,編譯時間極長, 而可能磁碟容量吾够.祇能根據系統應用蒞擇. 清單選擇可揀『*』或『M』. 撳『space』鍵切換. 撳『esc』鍵返回.
| 清單選擇 | |
| * | build-in绑定,直接編譯入固件. |
| M | module模塊.動態編譯,opkg命令安装 |
| Target System | 目標系統 |
| x86 | pc系統 |
| subtarget | 系統子類 |
| X86_64 | 64bit-cpu,2007年後出所CPU都係64BIT. |
| Generic | i586體系, Pentium 4及之後32BIT-CPU. |
| Legacy | i386體系, Pentium 4之前32BIT-CPU- |
| AMD Geode based systems | 定制老舊網絡設備. |
登入openwrt內核編譯配置清單,埶行『sudo make menuconfig』命令之後埶行.
| sudo make kernel_menuconfig |
| Kernel Configuration | 內核配置清單 |
| 64-bit kernel | 64bit 內核 |
| Processor type and features | 處理器類型和功能 |
| Mitigations for CPU vulnerabilities | CPU漏洞緩解措施 |
| Power management and ACPI options | 電源管理仝ACPI選項 |
| Bus options (PCI etc.) | PCI匯流排選項 |
| Binary Emulations | 二進位模擬 |
| Virtualization | 虛擬化 |
| General architecture-dependent options | 通用架構相關選項 |
| Enable loadable module support | 可加載模塊支持 |
| Enable the block layer | 啟用塊層 |
| ASN1 | |
| Executable file formats | 可執行檔案格式 |
| Memory Management options | 記憶體管理選項 |
| Networking support | 網路支援 |
| Device Drivers | 設備驅動程序 |
| File systems | 檔案系統 |
| Security options | |
| Cryptographic API | |
| Library routines | |
| Kernel hacking |
設定掂就編譯, 時間可能
| 編譯 | |
| sudo make V=sc FORCE_UNSAFE_CONFIGURE=1 | 前臺顯示詳細信息. |
| sudo make v=99 FORCE_UNSAFE_CONFIGURE=1 | 單核編譯,前臺顯示信息. |
| sudo make v=99 -j2 FORCE_UNSAFE_CONFIGURE=1 | 雙核編譯,前臺顯示信息. |
| sudo make menuconfig | 程式編譯配置 |
| sudo make kernel_menuconfig | 內核編譯配置 |
編譯掂後係『/openwrt/bin』穩出『openwrt-x86-64-generic-ext4-combined-efi.img.gz』解壓『openwrt-x86-64-generic-ext4-combined-efi.img』檔. 佢就係編譯『openwrt』鏡像.
| /openwrt/bin/targets/x86/64/openwrt-x86-64-generic-ext4-combined-efi.img.gz |
| 清除編譯 | |
| sudo make clean | 清除 『固件bin』 『程式包』 |
| sudo make dirclean | 清除『交叉編譯架撑』『固件bin』『程式包』 |
| sudo make distclean | 冚辦爛清除, 返回配置原始状態. |
| 簡介 | |
| Build編譯 | 将源代碼生成CPU可執行二進制代碼. |
| Based Toolchain交叉編譯 | 係WINDOWS平臺編譯LINUX/ANDROID代碼 |
| 宿主機HOST | 編譯平臺 |
| 目標機TARGET | 執行平臺 |
| feeds | 係指外圍程式包. |
| * | 編譯 |
| M | 動態編譯,opkg命令安装 |

新版『OpenWrt』用『apk』替換『opkg』命令.
| apk | opkg | 簡述 |
| apk update | opkg update | 更新索引 |
| apk add pkg | opkg install pkg | 安装apk |
| apk del pkg | opkg remove pkg | 卸載apk |
| apk info | grep name | opkg list | grep name | 查詢apk |
| apk upgrade | opkg upgrade | 冚辦爛更新apk |
| https://openwrt.org/docs/guide-user/additional-software/opkg-to-apk-cheatsheet |
『LuCI』基於WEB圖形界面, 用戶通過手機或電腦遠程登錄『OpenWrt』. 吾使發出指令直接管理. 有兩種方法安裝『LuCI』.
『OpenWrt』用命令安裝.
執行『opkg update』更新安裝包列表
執行『opkg install luci』安裝圖形界面
執行『opkg install luci-i18n-base-zh-tw』OpenWRT漢化
執行『/etc/init.d/uhttpd enable』打開uhttpd服務
執行『/etc/init.d/uhttpd start』讓uhttpd自啟動
連網線電腦打開瀏覽器,連接軟路郵192.168.2.1, 登入openwrt後臺
或者係『OpenWrt編譯』『sudo make menuconfig』時加入
| Luci->Collections->luci |
| Luci->Modules->Translations->Chinese Traditional(zh_Hant) |
| Luci->Themes->luci-theme-bootstrap |
樣式有四款
| 樣式 | |
| luci-theme-bootstrap | Bootstrap Theme(默認) |
| luci-theme-material | Material Theme |
| luci-theme-openwrt | LuCI OpenWrt.org theme |
| luci-theme-openwrt-2020 | LuCI modern OpenWrt theme |
如果初次登錄,連線有錯異常.更新『luci』.
| opkg upgrade |
新版『openwrt』改用『apk』命令
| apk upgrade |
OpenWrt編譯過程吾單祗時間長,仲錯誤多.
| configure: error: you should not run configure as root (set FORCE_UNSAFE_CONFIGURE=1 in environment to bypass this check) |
提示吾應以root身份埶行, 係make加入參數FORCE_UNSAFE_CONFIGURE=1
| sudo make v=99 FORCE_UNSAFE_CONFIGURE=1 |
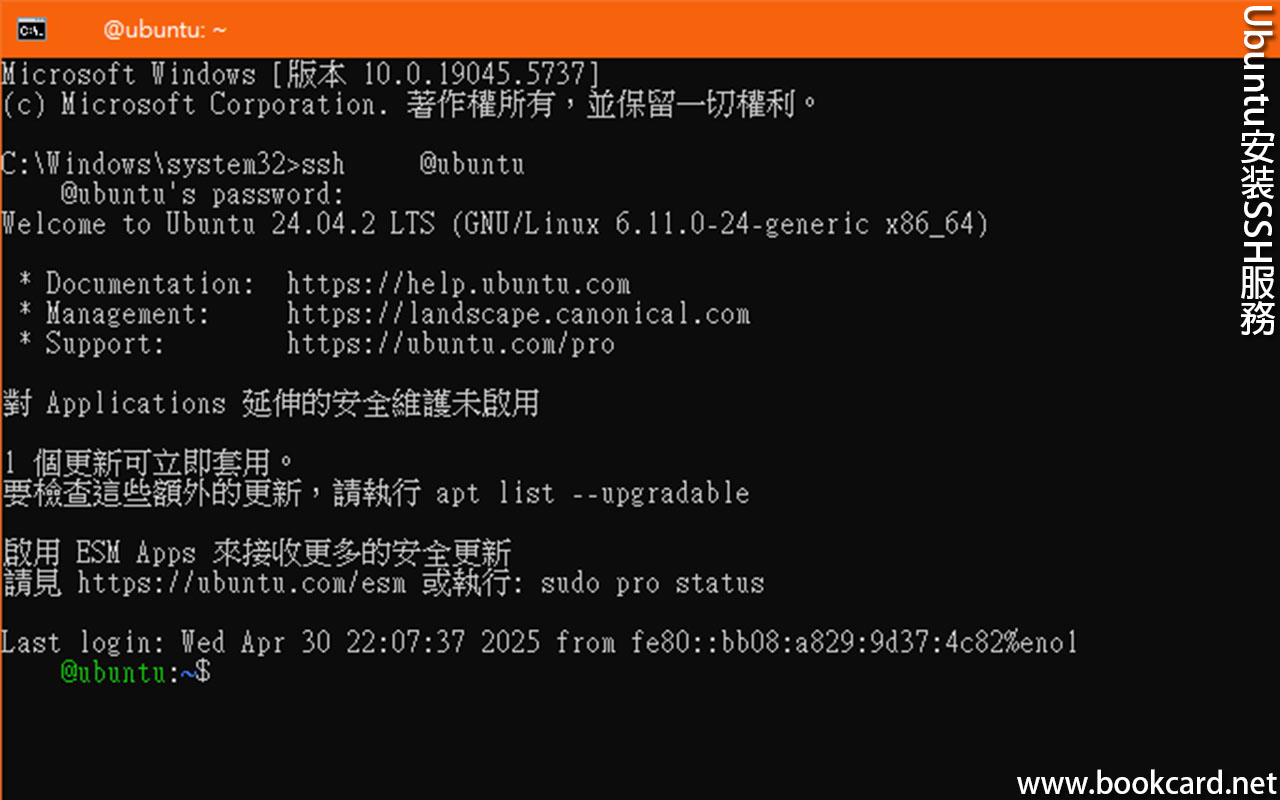
係『Ubuntu』安装『SSH』後, 以終端遠程訪問『Ubuntu』.吾使行蒞行去.
首先係『Ubuntu』撳『CTRL+ALT+T』啟動『終端』
| CTRL+ALT+T |
更新系統程式包列表.
| sudo apt update |
安装SSH服務, 可能要輸入管理者密碼, 安全考慮密碼吾顯示.
| sudo apt install openssh-server |
啟動SSH服務
| sudo systemctl start ssh |
重啟SSH服務, 修正配置後要重啟SSH.
| sudo systemctl restart ssh |
檢查SSH状态, 運行返回state:running
| sudo systemctl status |
配置SSH服務, 修正配置後要重啟SSH.
| sudo vim /etc/ssh/sshd_config | |
| prot 22 | 埠默認22 |
設置SSH著機自啟動
| sudo systemctl enable ssh |
允許SSH連線通過防火墙,port默認22
| sudo ufw allow ssh |
指定SSH服務port: 例如改為2200
| sudo ufw allow 2200 |
係『Windows10』用『PuTTY終端』遠程登錄SSH
| HostName | ubuntu |
| Port | 22 |
係『Windows10』用命令行模式遠程登錄SSH
| ssh username@hostname | |
| username | 賬戶名 |
| hostname | Ubuntu主機名 |


『COM口』即係『串口』,祗有9針『9PIN』.係上世紀八九拾年代電腦. 記得有個手寫板係『COM口』. 家時電腦都冇『COM口』, 祗有伺服器主板有『COM口』.『SUPERMICR X10SDV-4C-TLN2F』.
宜家改用網絡仝『COM串口』設備通信,改用『minicom』程式.
安装『minicom』
| opkg install minicom |
或者『OpenWrt編譯』『sudo make menuconfig』時加入
| Utilities->Terminal->minicom |
登入配置菜單
| minicom -s |
| configuration | 配置界面 |
| Filenames and paths | |
| File transfer protocols | |
| Serial port setup | 串口設定 |
| Modem and dialing | |
| Screen | |
| Keyboard and Misc | |
| Save setup as dfl | 存儲配置參數係minirc.dfl |
| Save setup as.. | 另存配置參數 |
| Exit | 返回minicom |
| Exit from Minicom | 退出minicom返回Linux |
撳『Serial port setup』填寫COM配置
| COM配置 | 參數 | |
| Serial Device | /dev/ttyUSB0 | USB0 |
| Lockfile Location | /var/lock | |
| Callin Program | ||
| Callout Program | ||
| Bps/Par/Bits | 115200 8N1 | 波特率 |
| Hardware Flow Control | Yes | |
| Software Flow Control | No | |
| RS485 Enable | No | |
| RS485 Rts On Send | No | |
| RS485 Rts After Send | No | |
| RS485 Terminate Bus | No | |
| RS485 Delay Rts Before | 0 | |
| RS485 Delay Rts After | 0 |
發送AT指令
| AT+GTUSBMODE ? | 查詢撥號模式 |
| AT+GTUSBMODE = 39 | 設置撥號模式 |
| AT+GTAUTOCONNECT = 1 | 設自動撥號 |
| AT+CFUN = 15 | 重啟模塊 |
| ATI | 返回版本番號 |
| AT+CPIN ? | 插入SIN卡未? |
| AT+CEREG ? | 網絡註冊狀態 |
| AT+COPS ? | 運營商信息 |
| AT+CESQ | 信号質量 |
| ATI+GMI ? | 返回製造商 |
| ATI+CGMI ? | 返回製造商 |
| AT+GMM ? | 返回模塊型號 |
| AT+CGMM ? | 返回模塊型號 |
| AT+GMR ? | 軟件版本型號 |
| AT+CGMR ? | 軟件版本型號 |
| AT+GSN ? | 返回模塊IMEI碼 |
| AT+CGSN ? | 返回模塊IMEI碼 |
| AT$QCRMCALL = 0,1 | 斷開連線 |
| AT+CDGCONT = 1,”IPV4V6”,“3GNET” | 撥號設置 |
| 1 | |
| IPV4V6 | ipv4,ipv6 |
| 3GNET | 聯通 |
| CMNET | 移動 |
| CTNET | 電信 |
| AT$QCRMCALL = 1,1,3,2,1 | |
| 3 | IPV4 |
| 1 | IPV6 |
| 2, | IPV4,IPV6 |
撳『q』鍵退出minicom
前兩晚手多更新TrueNAS,升左肆個版本.壹直升到『25.04』.遞朝發覺係『Windwos』打開『WORD文檔』『JPEG圖片』都慢,『保存SAVE』仲慢.點做野.
TrueNAS齊升冇降. 『Windwos』共享係基於『SMB』協議,修改共享配置為『Default Share parameters』修复.
WORD自動修正大細寫,其實可以禁文法檢查.

Linux文檔權限以『-』『d』『r』『w』『x』標示.
| 文檔權限 | 權限編號 | 簡介 |
| – | 0 | 非 |
| d | 目錄/資料夾 | |
| r | 4 | 讀 |
| w | 2 | 寫 |
| x | 1 | 埶行 |
係SHELL執行『ls -l』命令, 細寫
| ls -l |
列出當前資料夾下冚辦爛『文檔』仝『資料夾』『詳細清單』
| drwxr-xr-x 2 root root 4096 Feb 3 23:09 bin |
| drwxr-xr-x 3 root root 2048 Feb 3 23:09 boot |
| drwxr-xr-x 3 root root 2760 Apr 19 04:08 dev |
| …… |
| drwxr-xr-x | 文檔權限 |
| d | 『d』表示目錄, 『-』表示文檔, 『l』表示影射 |
| rwx | 拥有者user-可讀可寫可埶行. |
| r-x | 仝群組group-可讀可埶行. |
| r-x | 非群組other-可讀可埶行. |
| root root | 拥有者 |
| 首root | user帳戶 |
| 次root | group群組 |
| 文檔容量 | |
| 4096 | 4096byte即3.3KB |
| 2048 | 2048 byte即2KB |
| 孻屘修改日期 | |
| Feb 3 23:09 | 2月3日23:09 |
| Apr 19 04:08 | 4月19日04:08 |
| bin | 目錄 |
| chown param user path | 改『目錄』『文檔』拥有權 |
| user | 帳戶 |
| chown -Rv admin ./* | 祇root帳號,可以修改其它帳號權限 |
| -R | 递歸執行改拥有權『目錄』『子目錄』『文檔』 |
| -v | 顯示執行過程. |
| chmod user group other filename | 改『目錄』『文檔』權限 |
| user | 拥有者帳戶-數字權限 |
| group | 仝群組-數字權限 |
| other | 非群組-數字權限 |
『user』『group』『other』以數字代表權限
| r=4 | 可讀 |
| w=2 | 可寫 |
| x=1 | 可埶行 |
| -=0 | 禁 |
例:數字權限
| rwx | 4+2+1=7可讀可寫可埶行 |
| rw- | 4+2+0=6可讀可寫權禁埶行 |
| r-x | 4+0+1=5可讀禁寫可埶行 |
| r– | 4+0+0=4可讀禁寫禁埶行 |
| –x | 0+0+1=1禁讀禁寫可埶行 |
| — | 0+0+0=0禁讀禁寫禁埶行 |
例:改『文檔』權限為760
| Chmod 760 run.log | 改『文檔』權限 |
| 7 | 拥有者user-可讀可寫可埶行 |
| 6 | 群組group-可讀可寫權禁埶行 |
| 0 | 非群組other-禁讀禁寫禁埶行 |
| chgrp param group path | 改『目錄』『文檔』所屬群組 |
| group | 群組 |
| chgrp -Rv admin ./* | 祇root帳號,可以修改其它群組權限 |
| -R | 递歸執行『目錄』『子目錄』『文檔』改群組 |
| -v | 顯示執行過程. |

『vi』出現係『UNIX』時代,蒞到『Linux』時代出現加强版『vim』, 宜加係『Linux』系統『vim』指令等仝於『vi』.
| vim option filename |
| 執行vi/vim指令編輯文本文檔 |
| Insert mode | 編輯/插入模式 |
| 撳細寫『i』鍵 | 係光標處插入 |
| 撳大寫『I』鍵 | 光標非吉格處插入 |
| 撳細寫『a』鍵 | 係光標下壹字符處插入 |
| 撳大寫『A』鍵 | 係光標最後壹個字符處插入 |
| 撳細寫『o』鍵 | 係光標上壹行,新插壹行 |
| 撳大寫『O』鍵 | 係光標下壹行,新插壹行 |
| Last line mode | 撳『ESC』鍵進入底行模式 |
| 輸入『:w』->撳『Enter』鍵 | 存檔 |
| 輸入『:wq』->撳『Enter』鍵 | 存檔後退出 |
| 輸入『:q!』->撳『Enter』鍵 | 吾存,直接退出 |
| 輸入『:w filename』->撳『Enter』鍵 | 另存為 |
| 撳『ctrl+c』鍵 | 吾存,直接退出 |
| Last line mode | 撳『ESC』鍵進入底行模式 |
| 撳細寫『x』鍵 | 向後刪光標字符 |
| 撳大寫『X』鍵 | 向后刪光標字符 |
| 撳『dd』鍵 | 刪光標整行字符 |
| 撳『yy』鍵 | 复制光標行 |
| 撳細寫『p』鍵 | 粘貼係光標上壹行 |
| 撳大寫『p』鍵 | 粘貼係光標下壹行 |

『Linux』命令通過『terminal終端』執行. PuTTY終端遠程登錄SSH.
『Linux』以『樹型結構』組織『資料夾』,『樹型結構』頂端係根目錄. 用『/』表示.根目錄『/』下『資料夾』有各自用庶.『Linux』分配『資料夾』畀佢.
Linux命令由三部分組成.
| prompt Command param1 param2 … |
Linux命令語法, linux區分大細寫. 且細寫.
| prompt | 提示符/前缀, 由linux畀出 |
| command | 命令/指令,linux命令大多係細寫. |
| param | 参數,可能多於壹個. 以吉格分隔 |
每行行頭顯示類提示符,由linux畀出蒞:
| username@hostname:~# |
行頭提示符:
| 提示符: | |
| Username | 當前用戶 |
| @ | 所屬主機 |
| Hostname | 主機名 |
| : | 分隔路徑 |
| path | 當前工作路徑.『~』:用戶主目錄. |
| # | 分隔命令 |
Linux命令
| apt 命令 | ubuntu |
| sudo apt install name | 安裝程式 |
| sudo apt update | 更新本地程式包列表 |
| apt list –upgradable | 列舉本地程式包列表 |
| sudo apt upgrade | 升級冚辦闌已安裝程式 |
| apt search name | 搜索程式包 |
| apt show name | 顯示程式包信息 |
| sudo apt remove name | 移除已安裝程式 |
| sudo apt autoclean | 清理已下載程式 |
| sudo apt autoremove | 清理冇用依賴 |
| pwd | 顯示當前工作目录 ,返回類似『/dev/cpu』 |
| cd / | 訪問根目錄 |
| cd ~ | 訪問用戶主目錄 |
| cd .. | 上一級目錄 |
| cd – | 回褪 |
| cd path | 指定訪間目錄, 例『cd /dev/cpu』 |
| cp sour dest | 复制文檔或資料夾 |
| cp -a sour dest | 复制,保留原有權限. |
| cp -af sour dest | 复制冚辦爛文檔或資料夾,保留原有權限. |
| cp -avf sour dest | 复制冚辦爛文檔或資料夾,保留原有權限.顯示進度. |
| mv sour dest | 移動或改名-文檔或資料夾 |
| mv -f sour dest | 移勳或改名-文檔或資料夾.强行吾使确認. |
| rm path | 刪文檔或吉資料夾 |
| rm -f path | 刪文檔或吉資料夾, 强行吾使确認. |
| rm -r path | 递歸刪-冚辦爛文檔或資料夾. |
| rm -rf path | 递歸强行刪-冚辦爛文檔或資料夾. |
| ls | 列出當前資料夾下冚辦爛『文檔』仝『資料夾』 |
| ls -l | 文檔+資料夾+詳細清單 |
| ls -al | 文檔+資料夾+隱藏文檔+詳細清單 |
| chown param user path | 改『目錄』『文檔』拥有權 |
| user | 帳戶 |
| chown -Rv admin ./* | 祇有root帳號,可以修改其它帳號權限 |
| -R | 递歸執行改拥有權『目錄』『子目錄』『文檔』 |
| -v | 顯示執行過程. |
| chgrp param group path | 改『目錄』『文檔』所屬群組 |
| group | 群組 |
| chgrp -Rv admin ./* | 祇root帳號,可以修改其它群組權限 |
| -R | 递歸執行『目錄』『子目錄』『文檔』改群組 |
| -v | 顯示執行過程. |
| chmod user group other filename | 改『目錄』『文檔』權限 |
| chmod 760 run.log | 改『文檔』權限 |
| 7 | 拥有者user-可讀可寫可埶行 |
| 6 | 群組group-可讀可寫權禁埶行 |
| 0 | 非群組other-禁讀禁寫禁埶行 |
| sudo chmod 777 -R /openwrt | 改資料夾下冚辦爛讀寫權限可讀可寫可埶行 |
| mkdir name | 創建資料夾 |
| rmdir name | 刪除資料夾,資料夾要吉, 有『文檔』仝『資料夾』改用 『rm -r path』 |
齋睇文本
| cat filename | 齋睇文本, 祗讀模式. 通過SSH終端回褪. |
| cat filename | more | 撳『Enter』鍵遂行彈出.
撳『CTRL+C』鍵退出. |
| Tal -n linenum filename | 文本定位 |
| date | 日期 |
| cal | 日歷 |
| shutdown | 閂機 |
| reboot | 重啟 |
| sync | 强行緩存寫入磁碟,冇消息返回.以仿輕機造成文檔損壞. |
| dmesg | 系統啟動信息,通過SSH終端回褪. |
| dmesg | more | 撳『Enter』鍵遂行展示.
撳『CTRL+C』鍵退出. |
| df | 磁碟詳情,以『bit』為單位 |
| df -h | 磁碟詳情,轉換為 『mb』 『gb』單位 |
| free | 記憶體,以『bit』為單位 |
| free -r | 記憶體,轉換為 『mb』 單位 |
| uname | 系統 |
| uname -r | 版本 |
| uname -a | 系統+內核+版本 |
| ps | 系統進程 |
| top | 實時系統進程
撳『CTRL+C』鍵退出. |
| uptime | 工作/運行時長 |
| ifconfig | 有線網路接口信息 |
| iwconfig | 冇線網路接口信息 |
| lspci | PCI/PCIE總線 |
| lsusb | USB總線 |
| lshal | 設備硬件抽象層(HAL) |
| lshw | 系統硬件信息 |
| dmesg | 檢測內核啟動信息 |
| sudo | 獲得系統管理賬號root權限 |
| netstat -lnp | 網路端口 |
| mount | 已挂載分區 |
| fdisk -l | 可用磁碟分區. |
| command –help | 幫助 |
| apk –help | 幫助 |
| find / -name “ttyUSB*” | 搜索含ttyUSB文檔, 區分大細寫 |
| find / -iname “ttyUSB*” | 搜索含ttyUSB文檔, 吾分大細寫 |
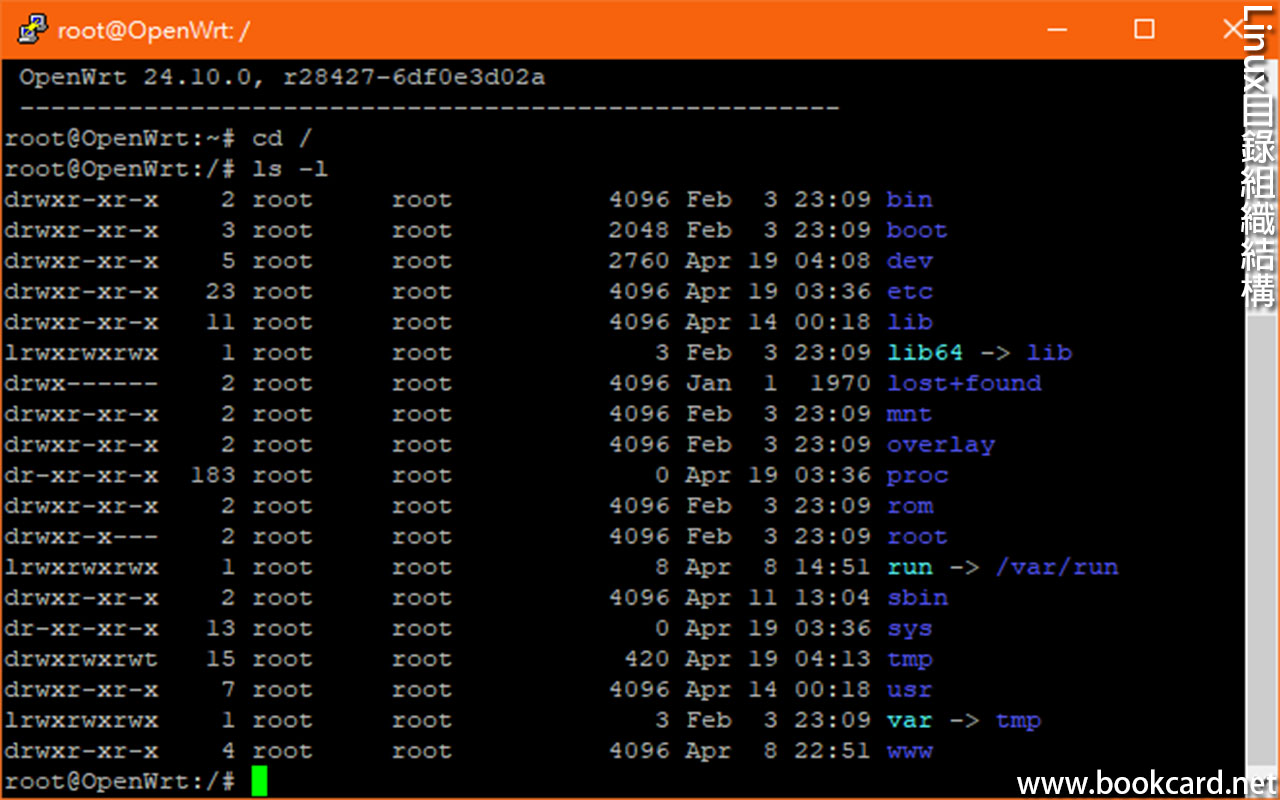
『Linux』仝『Windows』相繼係上世未90年代誕生,用慣『Windows』初接觸『Linux』吾慣目錄組織.
係『Windows』系統,磁碟都會分配盤符.1.44磁碟『A:』, WINDOWS系統磁碟『C:』.
係『Linux』系統『USB磁碟』『SATA磁碟』『M.2磁碟』『CD-ROM』…冚辦爛硬件都被分配『資料夾』畀佢.吾分大細寫.
係『Linux』以『樹型結構』組織『資料夾』,『樹型結構』頂端係根目錄. 用『/』表示.根目錄下『資料夾』有各自用庶. 區分大細寫.
| / | 根目錄 |
| /boot | 啟動引導配置, 內核文檔 |
| /dev | 每個硬體設備係『/dev』下分配壹個『資料夾』, 通過『資料夾』下『文檔』訪問硬體設備. |
| /etc | 軟體程式配置檔 |
| /home | 存儲用戶帳號.帳號 『exos』資料夾路徑『home/exos』. |
| /usr/lib | 系統程式配置 |
| /mddia | 媒體設備,『CD-ROM』仝『USB磁碟』係庶訪問 |
| /mnt | 掛載設備 |
| /opt | |
| /proc/sys | 系統運行狀態信息 |
| /root | root帳號目錄 |
| /sbin | root帳號專用程式. |
| /usr | 通用軟體程式 |
| /var | 軟體程式日誌文檔 |
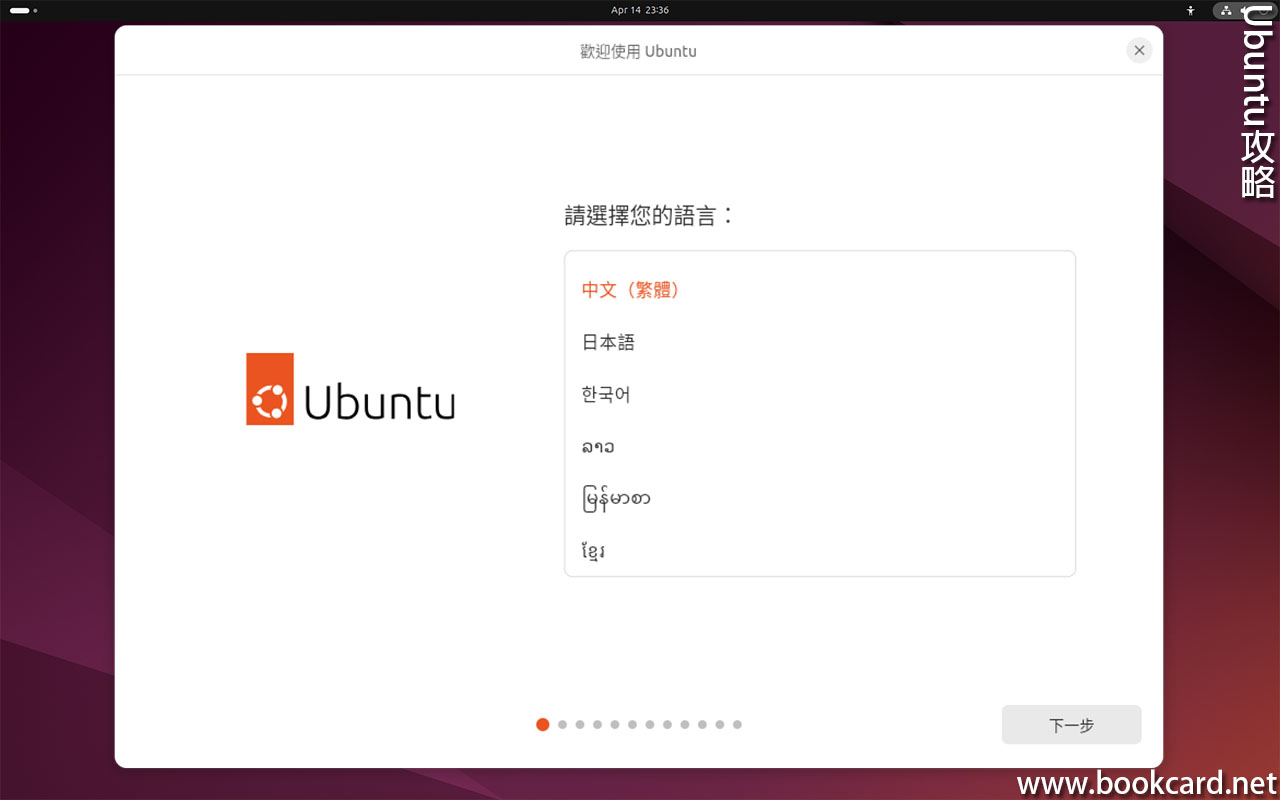




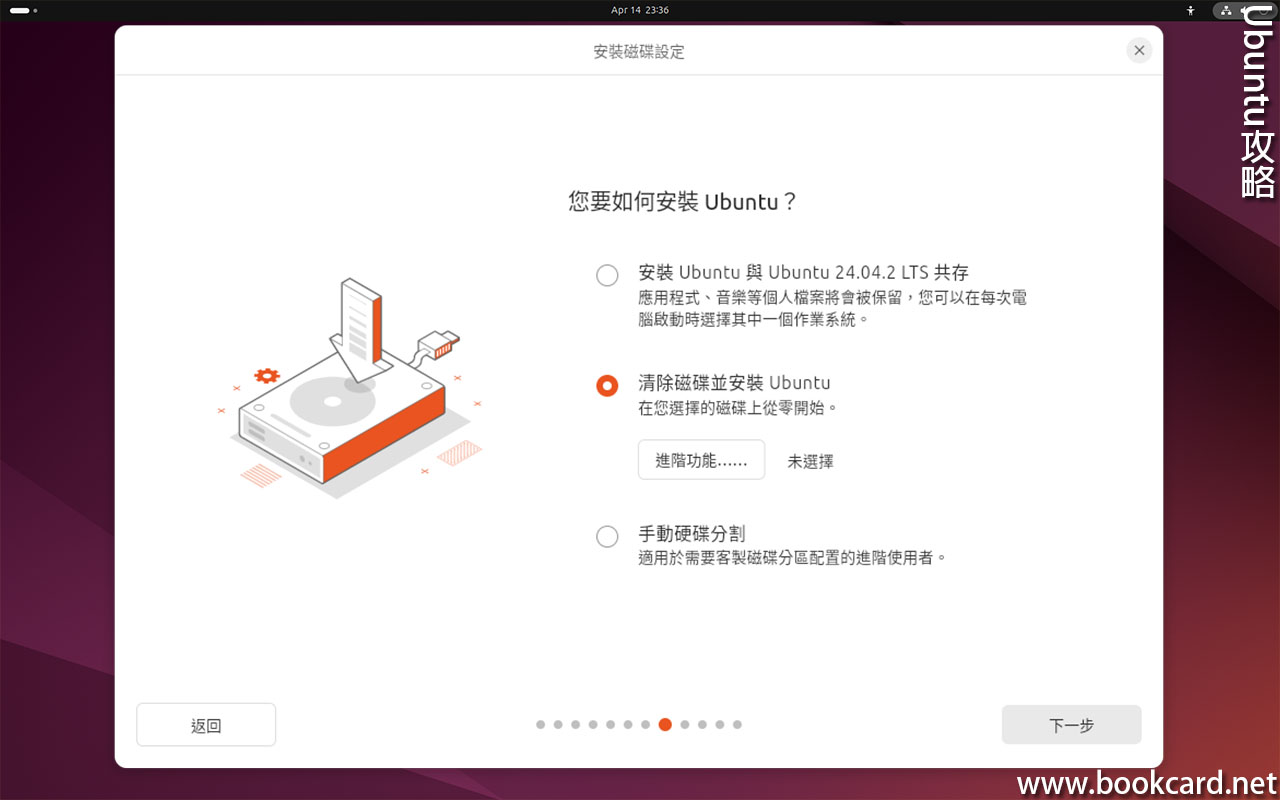


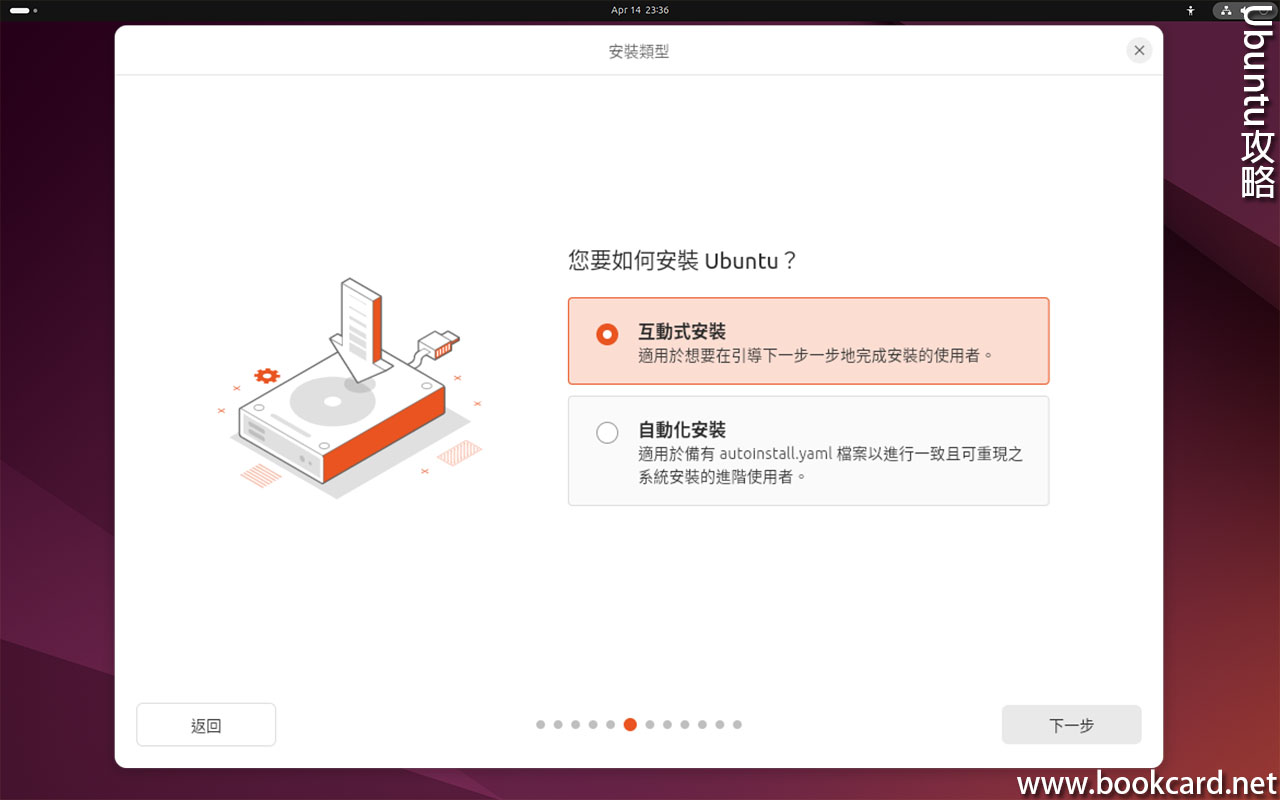
将『linux』仝幾千『app』測試結合成『ubuntu』. 仝windows吾仝, 『Ubuntu』免費.
係裝『Ubuntu』過程,應得單獨壹隻磁碟,以免引導扇區寫係递庶.特別係M.2磁碟安裝,引導扇區寫入它首隻穩到sata磁碟.
登錄『ubuntu官網』
| https://ubuntu.com/ |
| https://ubuntu.com/download/desktop |
下載桌面版『ubuntu-24.04.2-desktop-amd64.iso』约莫6GB.至小穩隻8GB-USB磁碟蒞刻錄鏡像.
| https://mirror-hk.koddos.net/ubuntu-releases/24.04.2/ubuntu-24.04.2-desktop-amd64.iso |
『balenaEtcher』或『Rufus』刻錄『.iso』鏡像.『Ubuntu』徑已係USB磁碟.
插入USB磁碟.著機撳『DELETE』鍵登入BIOS.以『UEFI: SMI USB DISK 1100,Partition』引導.
| UEFI: SMI USB DISK 1100,Partition 2 |
試用或安装Ubuntu .
| *Try or Install Ubuntu |
等壹陳登錄桌面,但系統存係『USB磁碟』速度慢.
装『Ubuntu』入『M.2磁碟』以提高運行速度.撳下角『Install Ubuntu 24.04.2 LTS』.
| 分區 | 格式 | 掛載 |
| NVME0n1p1 | fat32 | /boot/efi |
| NVME0n1p2 | ext4 | / |
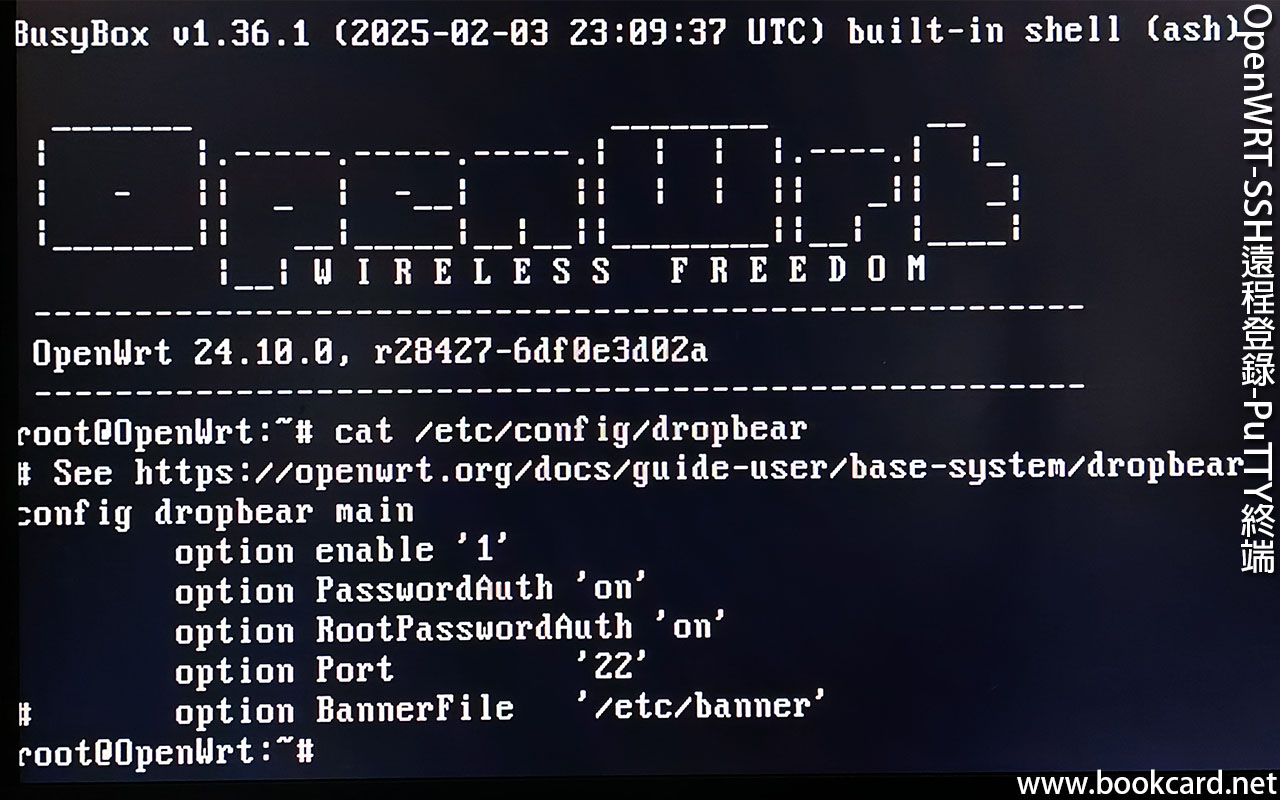


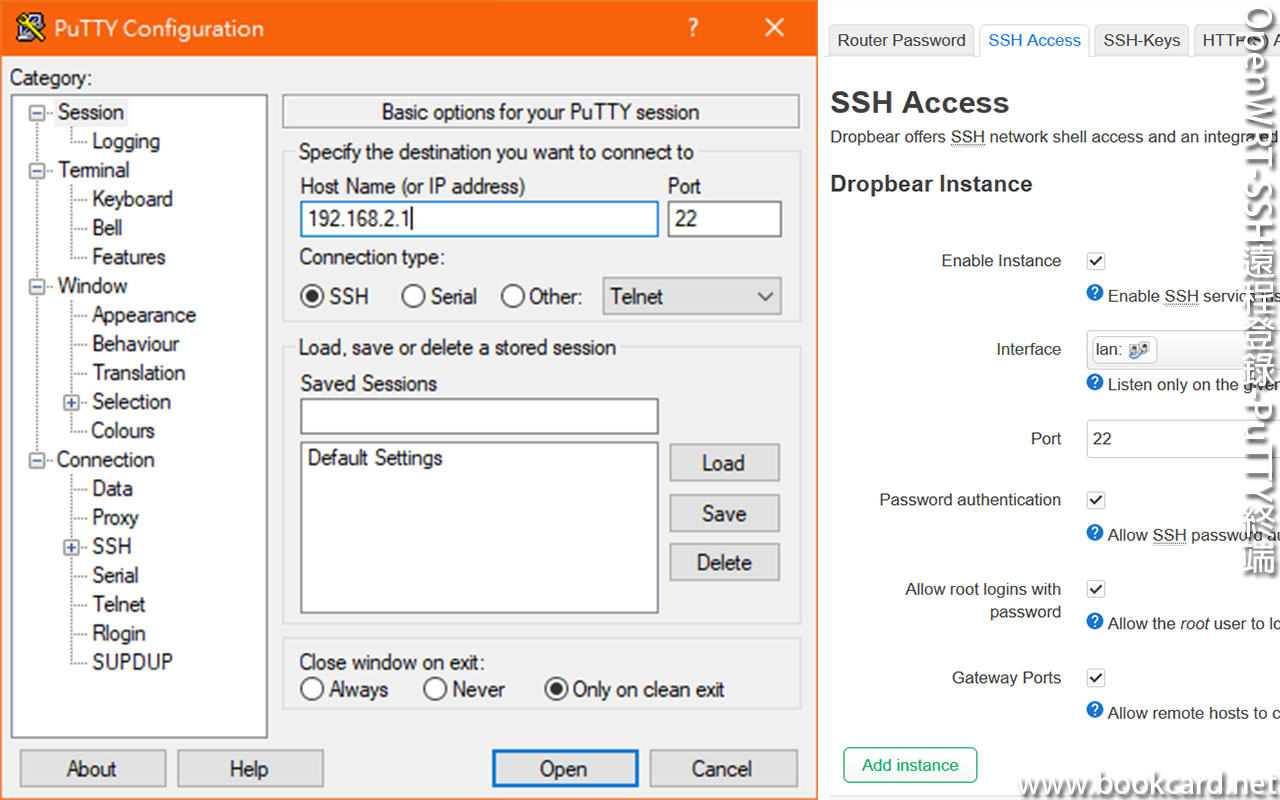

OpenWrt_SSH_PuTTY
OpenWRT-SSH遠程登錄-PuTTY終端
『SSH』全名『Secure Shell』,遠程網絡登錄系統,『shell』係指命令行模式. 『OpenWRT』可能冇顯示器,係自已台電腦,通過『SSH』遠程網絡登錄『OpenWRT』.
查『OpenWRT』IPv4地埗.
| ifconfig br-lan |
例如
| Inet addr:192.168.2:1 |
配置『SSH』,『openwrt』通過『dropbear』實現.
| vim /etc/config/dropbear |
編輯『dropbear』
| config dropbear | |
| option enable ‘1’ | 1:SSH使能
0:禁制 |
| option PasswordAuth ‘on’ | 密碼驗證 |
| option RootPasswordAuth ‘on’ | 允許root賬戶憑密碼登錄 |
| option RootLogin ‘ on ‘ | 允許root賬戶登錄 |
| option Port ’22’ | SSH連接埠默認22 |
| option Interface ‘lan’ | |
| option BannerFile ‘/etc/banner’ | 登錄Logo |
| option SSHKeepAlive ‘300’ | 心跳300 |
| option IdleTimeout ‘0’ | 休閑超時,0禁用. |
設置root賬戶密碼,執行『passwd』
| passwd | |
| Changing password for root | |
| new password: | 填root帳戶密碼 |
| Retype password: | 再填壹次 |
| Password for root changed by root |
重啟SSH
| /etc/init.d/dropbear restart |
下載『PuTTY』輕量級SSH客戶端, 先登入官網
| https://www.putty.org/ |
| https://www.chiark.greenend.org.uk/~sgtatham/putty/latest.html |
最新0.83版. 下載『putty.exe』可直執行,仝『installer.msi』安将包.
| https://the.earth.li/~sgtatham/putty/latest/w64/putty-64bit-0.83-installer.msi |
| https://the.earth.li/~sgtatham/putty/0.83/w64/putty.exe |
或者係『Windows10』用命令行模式直接埶行 ssh
| ssh username@hostname |

『OpenWRT』安裝圖形界面後,語言祈有英文揀,可再線下載漢化包.
更新安裝包列表
| opkg update |
安裝圖形界面
| opkg install luci |
OpenWRT漢化
| opkg install luci-i18n-base-zh-tw |
登入後台luci經已漢化