各大导航网站搜索引擎的提交入口
如果你有一个网站,那么你必需提交的网站的域名给搜索引擎,和导航网站,这样你才可以为你网站/博客带来流量.
如果你的域名在起它网站有外链,搜索引擎也会自动收录.最终要你的网站吸引到用户的需求,才能带来收入.
Google 谷歌收录入口

BOOKCARD
各大导航网站搜索引擎的提交入口
如果你有一个网站,那么你必需提交的网站的域名给搜索引擎,和导航网站,这样你才可以为你网站/博客带来流量.
如果你的域名在起它网站有外链,搜索引擎也会自动收录.最终要你的网站吸引到用户的需求,才能带来收入.
Google 谷歌收录入口
应用商店开发者入口
当你开发一款软件或游戏,你当然希望多点染使用它,最好还有一定的收入,那么你需要你需要将你软件或游戏上存到应用市场.
有收费应用和免费应用,免费应用可以加入广告增加收入.
我会跟据重要程度来排列.
Google Play 这是最要的应用市场
Google 移动广告
百度手机助手 在中国国内的应用市场,可以申请移动广告
百度移动广告

白米:稻谷脱壳碾白后为大米,正常大米一般为白色,变黄的大米是品质变坏的象征.
黄米有两种,一种叫黄粒米,另一种叫黄变米.
黄粒米:稻谷在收割期间,遇到高稳多雨,又未能及时脱粒干燥.
稻谷存储时间过长或保存不善,会使加工的大米变黄.
黄粒米产生的主要原因是大米中的营养成份发生了成色反应,其营养价值大幅降低.
黄变米:稻谷在收割期间和储存期间含水过高,被真菌感染发生霉变所致.
黄曲酶感染大米后产身黄曲酶毒素,黄曲酶毒素是最强的置癌物.它的毒性极强,比氰化钾大10倍,比砒霜大68倍.
人体的肝脏主管解毒,大量量的毒素会令肝脏无法解毒,发生肝炎,肝硬化,肝坏死.

大米-防虫,防谷藕
防虫,下面使用防谷藕代称.大米本身以带有谷藕卵.夏天天气焱热,空气湿度大,而且大米容易吸味,吸湿,容易发霉的特性.谷藕并不会对人体健康造成影响.也不会导致大米的品质发生改变.
1.花椒气味防谷藕法:花椒是一种天然的植物,发放强列味道,天然就具有驱虫的作用.将花椒放在布袋内,如果放在密封袋则要刺穿几个梳气孔.此方法只合适将花椒放在大米的包装袋之外.万万不能与大米一起放置,因为大米容易吸味,花椒会盖去大米的米香,而且是不可易转的.
2.海带吸湿防谷藕法:利用干海带吸湿的能力,吸收空气中的水气.此方法同样只能将海带放在大米的包装袋之外.万万不能与大米一起放置,因为大米容易吸味,海带会盖去大米的米香,而且是不可易转的.
3.保存法:使用完全密封袋,不能漏气,因为大米容易吸味.发在冰箱中保存.
4.购米法:选购大米时应选则应选则较大的米厂,它们都有自己一套的防谷藕技术,保证大米在出厂时不含有谷藕,尽量购买当月出厂的,并根据家庭人数食量购买大米.以保证大米开包后,在一个月内食完.
一个成人每一天一餐,每餐两碗饭,则需要5KG大米.
一个成人每一天两餐,每餐两碗饭,则需要10KG大米.
三个成人每一天两餐,每餐两碗饭,则需要30KG大米.可以购买每包15KG的,半个月买一次米,谷藕连生长的时间没有.
排序算法-快速排序(三者取中劃分)
快速排序算法的一個改進版本,在數組取三個元素的中間進行劃分.這樣可以避免出現最壞的情況.
取數組的左邊,中間,右邊的元素.對這三個數進行排序.
#define less(A,B) ((A)<(B)) // 小於比較
#define exch(A,B) {int temp=A; A=B; B=temp;} // 交換
#define compexch(A,B) if(less(A,B)) exch(A,B) // 小於則交換
下面給出C代碼的實現.
// 劃分算法
//a:數組
//l:數組的左則索引
//r:數組的右則索引
void quicksort(int a[],int l,int r)
{
int i;
int temp;
// a[(l+r)/2] 與 a[r-1]交換
exch(a[(l+r)/2], a[r-1]);
// 取數組的左邊,中間,右邊的元素.對這三個數進行排序.
// 小於則交換
compexch(a[r-1],a[l]);
compexch(a[r], a[l]);
compexch(a[r], a[r-1]);
i = partition(a,l+1,r-1);
quicksort(a[],l, i-1);
quicksort(a[],i+1,r);
}
// 劃分算法
//a:數組
//l:數組的左則索引
//r:數組的右則索引
int partition(int a[],int l,int r)
{
int i,j,v,t;
i = l;
j = r;
v = a[j];//選則最右則的元素作為劃分元素v
while(true)
{
while(a[i]<v)
++i;// i的左則小與v
while(v<a[j])
{
++j;// j的右則大與v
if(j==l)
break;// 跳出
}
if(i>=j)
break;// 兩個指針相遇跳出掃描.
// 交換i,j,交換那些使掃描停止的元素.
t=a[i];
a[i]=a[j];
a[j]=t;
}
// 交換i,r,保證v的左則小於於它,v的右則大於它.
t=a[i];
a[i]=a[r];
a[r]=t;
return i;
}
排序算法-快速排序(非递归)
1.选则最右则的元素作为划分元素v,然后从左则扫描小于v的元素,然后从右则扫描大于v的元素.
交换那些使扫描停止的元素.
2.重复进行这样的过程直到两个指针相遇.
3.然后分别对左右两步分进行递归处理.最终得到一个排好序的数组.
// 全局数据
int stack[128];// 堆栈
int ps;// 堆栈指针
//初始化堆栈
void init()
{
ps = 0;
}
//堆栈是否为空
int IsEmpty()
{
if(ps == 0)
return 1;
else
return 0;
}
// 压入
void push(int v)
{
stack[ps]=v;
++ps;// 指针加一
}
// 弹出
int pop()
{
if(ps == 0)
return = 0;
–ps;// 指针减一
return stack[ps];
}
下面给出C代码的实现.
//快速排序(非递归)
//a:数组
//l:数组的左则索引
//r:数组的右则索引
void quicksort(int a[],int l,int r)
{
init();
push(l);
push(r);
while(IsEmpty())
{
l=pop();
r=pop();
if(r<=l)
continue;
i=partition(a,l,r);
if(i-l < r-i)
{
push(l);
push(i-1);
push(i+1);
push(r);
}
else
{
push(i+1);
push(r);
push(l);
push(i-1);
}
}
}
// 划分算法
//a:数组
//l:数组的左则索引
//r:数组的右则索引
int partition(int a[],int l,int r)
{
int i,j,v,t;
i = l;
j = r;
v = a[j];//选则最右则的元素作为划分元素v
while(true)
{
while(a[i]<v)
++i;// i的左则小与v
while(v<a[j])
{
++j;// j的右则大与v
if(j==l)
break;// 跳出
}
if(i>=j)
break;// 两个指针相遇跳出扫描.
// 交换i,j,交换那些使扫描停止的元素.
t=a[i];
a[i]=a[j];
a[j]=t;
}
// 交换i,r,保证v的左则小于于它,v的右则大于它.
t=a[i];
a[i]=a[r];
a[r]=t;
return i;
}
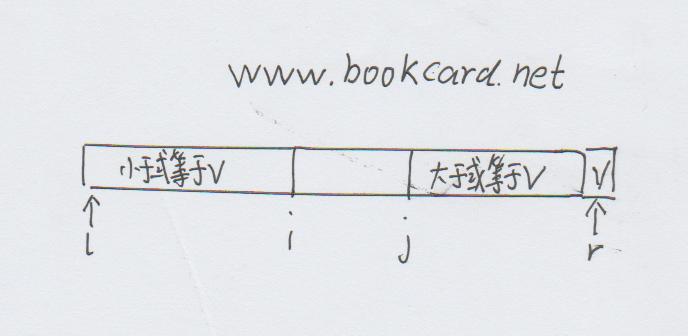
排序算法-快速排序
快速排序是由C.A.R.Hoare在1960年提出.对于大型数据,快速排序算法的性能是希尔排序的5到10倍.
快速排序是一种分而治之算法,它将素组划分成两部分,然后分别对两个部分进行排序.
1.选则最右则的元素作为划分元素v,然后从左则扫描小于v的元素,然后从右则扫描大于v的元素.
交换那些使扫描停止的元素.
2.重复进行这样的过程直到两个指针相遇.
3.然后分别对左右两步分进行递归处理.最终得到一个排好序的数组.
下面给出C代码的实现.
// 划分算法
//a:数组
//l:数组的左则索引
//r:数组的右则索引
int partition(int a[],int l,int r)
{
int i,j,v,t;
i = l;
j = r;
v = a[j];//选则最右则的元素作为划分元素v
while(true)
{
while(a[i]<v)
++i;// i的左则小与v
while(v<a[j])
{
++j;// j的右则大与v
if(j==l)
break;// 跳出
}
if(i>=j)
break;// 两个指针相遇跳出扫描.
// 交换i,j,交换那些使扫描停止的元素.
t=a[i];
a[i]=a[j];
a[j]=t;
}
// 交换i,r,保证v的左则小于于它,v的右则大于它.
t=a[i];
a[i]=a[r];
a[r]=t;
return i;
}
//快速排序
//a:数组
//l:数组的左则索引
//r:数组的右则索引
void quicksort(int a[],int l,int r)
{
int i;
if(l<=0)
return ;
quicksort(a,l, i-1);
quicksort(a,i+1,r);
}
//快速排序
//a:数组
//c:数组的长度
void quicksort(int a[],int c)
{
quicksort(a,0,c-1);
}
排序算法-希尔排序
1.希尔排序是查入排序的扩展版.在扫描数据时,把移动的增量或减量由原来的1变成h.
2.h就是步长.对于每个h,对每个h单独使用插入排斥.
下面给出C代码的实现.
//a:数组
//l:数组的长度
void shellsort(int a[],int l)
{
int i,j;
int h;// 步长
int v;
// 计算步长
h=1;
while(h<=l/9)
h=3*h+1;
for(;h>0; h/=3)// 改边步长
{
for(i=h; i<=l; ++i)// 使用插入排斥
{
j=i;
v=a[i];
while(j>=h && v < a[j-h])
{
a[j]=a[j-h];
j-=h;
a[j]=v;
}
}
}
}
顏色代碼
這是一款生成自定義顏色的應用程式.
展示色樣,色板的實用工具!
全中文顏色名稱
專業的顏色選擇器
用戶自定義顏色(RGB/CMYK)
按音量鍵切換畫面
分享自定義的顏色代碼
支援多種顏色模型/顏色空間轉換
http://shouji.baidu.com/software/8050740.html



排序算法-冒泡排序
1.进行遍历,当遇到最小元素时,将它与左边的元素逐个交换.直到将最小的元素移到对列的最左边.
2.进行遍历,将第二小的元素放到数组的左边第二个元素中.
3.以此类推.
冒泡排序,实际是选择排序,但需要更多CPU开销.
冒泡排序排序的特点是容易实现,不过比插入排序和选择排序慢.
下面给出C代码的实现.
//a:数组
//l:数组的长度
void bubble(int a[],int l)
{
int i,j;// 索引
int temp;// 用于交换
for(i=0;i<l;++i)
{
for(j=0;j<i;–j)
{ // 小于比较
if(a[j-1]<a[j])
{// 进行交换
temp=a[j];
a[j]=a[j-1];
a[j-1]=temp;
}
}
}
}
你必須登入才能發表留言。